Téléchargé 12 fois




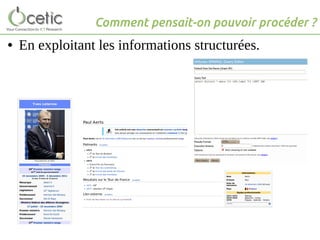



















Le document présente une étude menée par Robert Viseur sur l'exploitation des données de Wikipédia pour créer une base de données biographiques de personnalités belges. Il décrit les cinq étapes du processus, depuis l'identification des articles jusqu'à l'évaluation de la fiabilité des données, en mettant en évidence les défis rencontrés en raison de la structure non uniforme des articles. Les résultats montrent une précision d'extraction d'environ 90%, avec une fiabilité des données jugée satisfaisante.

































