Téléchargé 33 fois







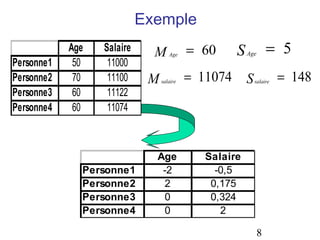


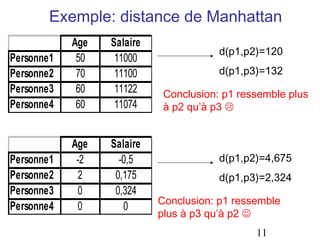





![Variables Ordinales
Une variable ordinale peut être discrète ou continue
L’ordre peut être important, ex: classement
Peuvent être traitées comme les variables intervalles
rif ∈ 1,..., M f }
{
remplacer x par son rang
if
Remplacer le rang de chaque variable par une valeur
dans [0, 1] en remplaçant la variable f dans l’objet I par
rif −
1
zif =
Mf −
1
Utiliser une distance pour calculer la similarité
17](https://image.slidesharecdn.com/coursclustersi2e-131202151208-phpapp01/85/Cours-cluster-si2e-16-320.jpg)






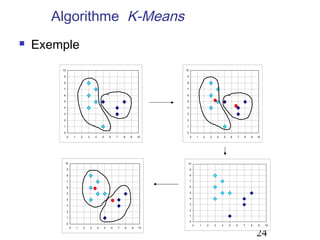






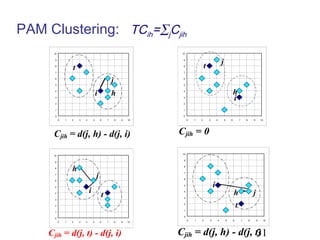
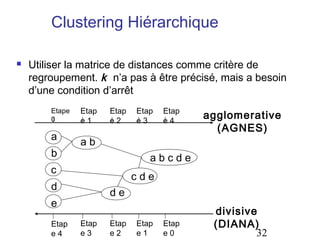

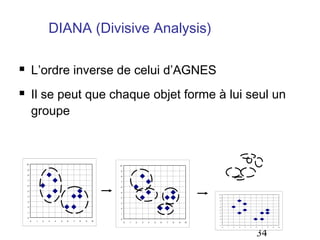


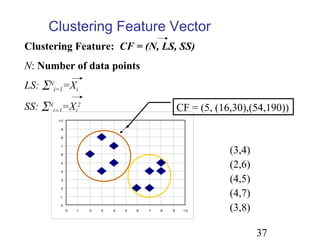
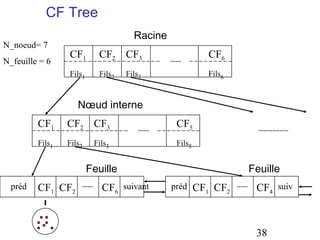
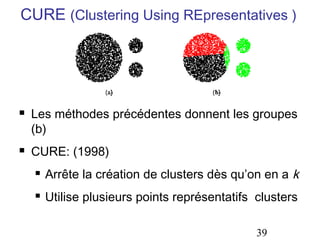

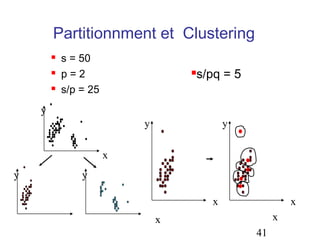
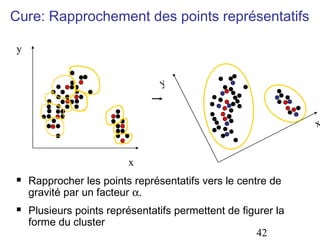




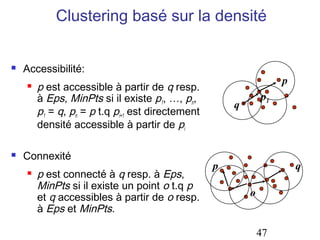
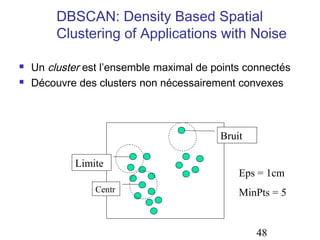





Le document aborde les méthodes de regroupement (clustering), en détaillant les critères d'un bon regroupement et les différentes structures de données nécessaires. Il décrit diverses mesures de similarité et de distance pour évaluer la qualité des regroupements, ainsi que plusieurs algorithmes de partitionnement, comme k-means et k-medoids. Enfin, il souligne l'importance de choisir les bonnes méthodes en fonction des types de données et des caractéristiques des résultats souhaités.



































































