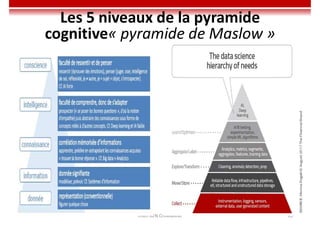
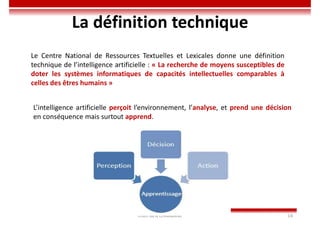
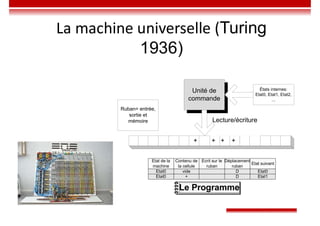
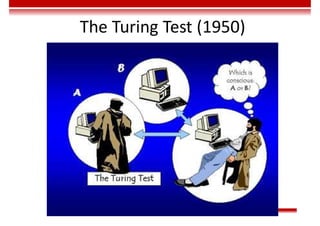
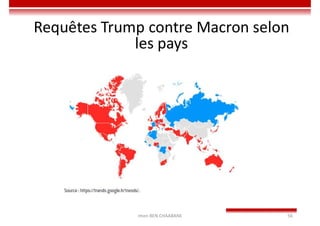
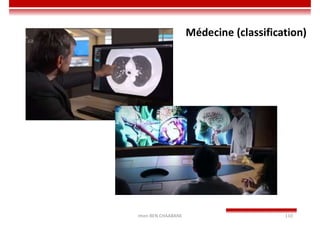
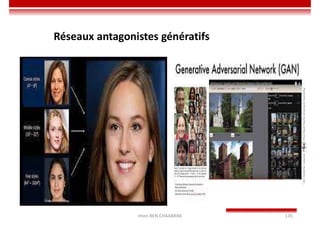
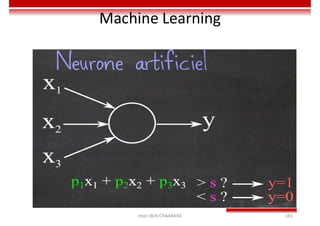
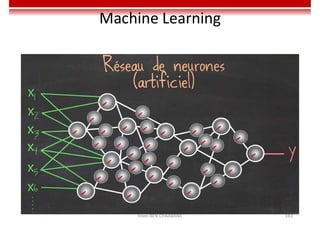
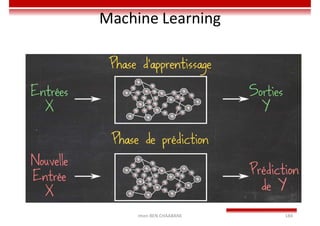
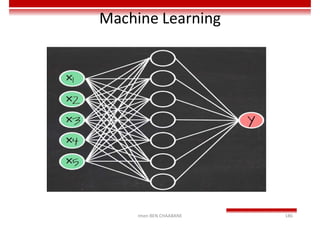
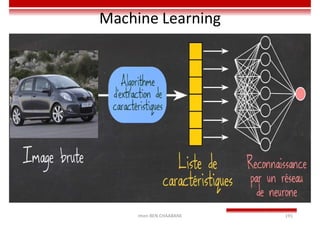
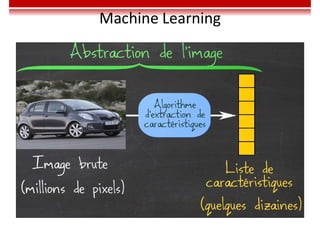
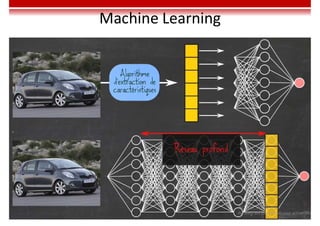
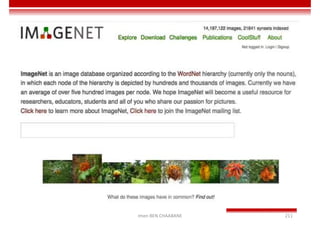
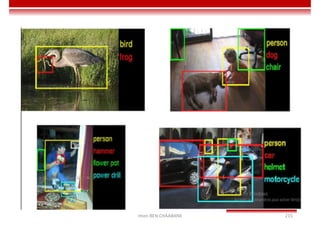
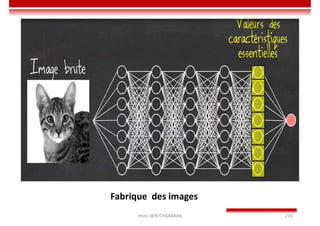
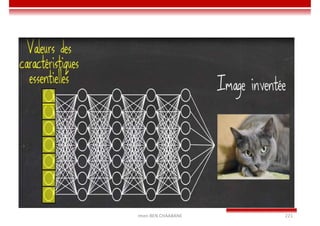
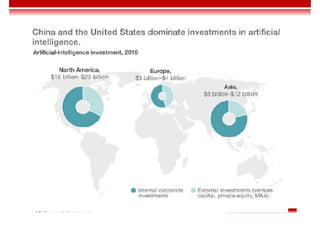
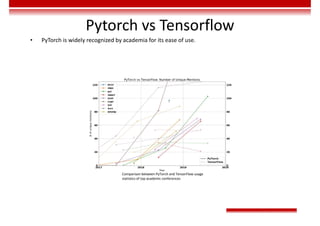
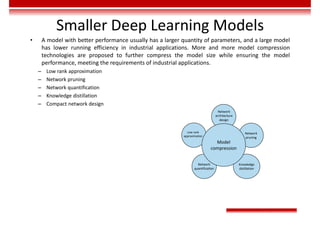
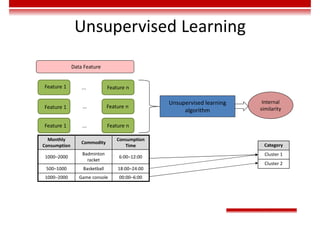
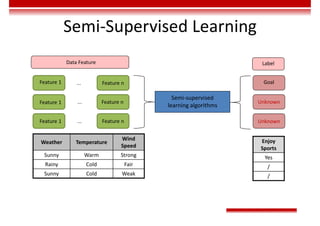
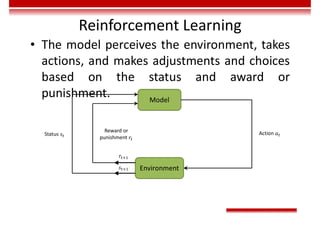
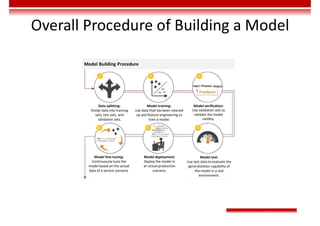
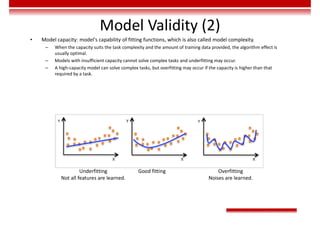
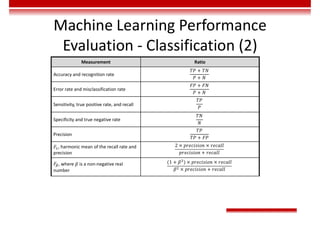
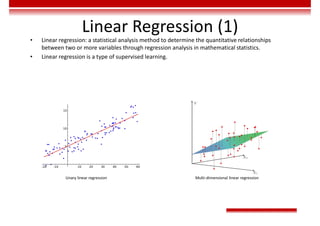
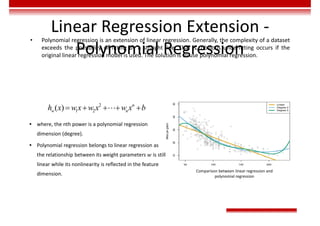
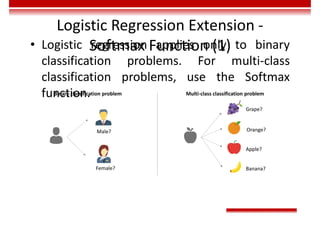
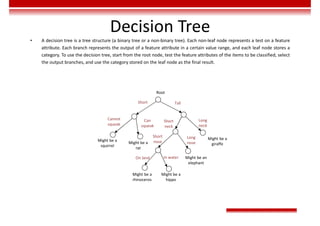
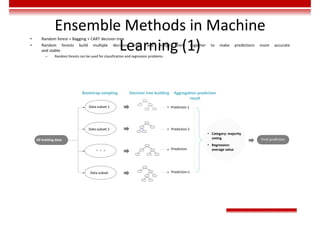
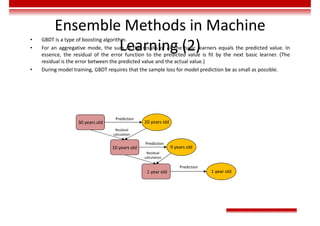
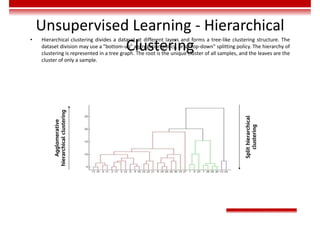
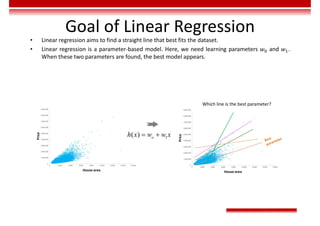
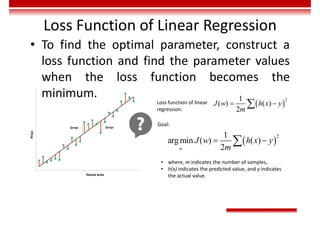
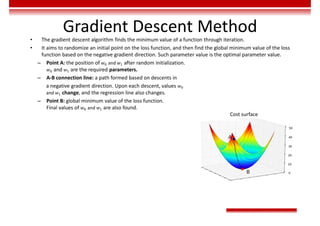
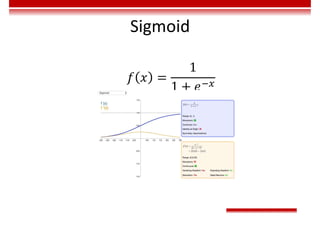
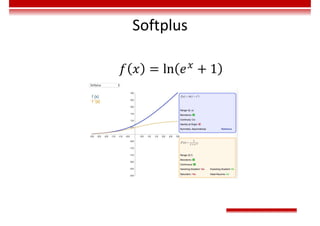
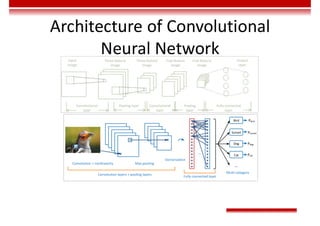
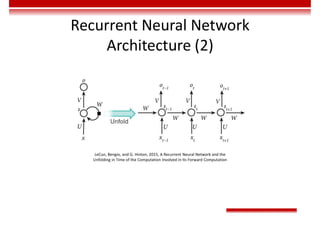
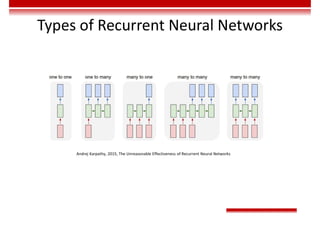
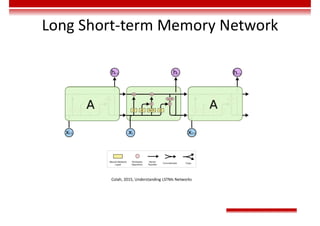
Le document traite des concepts et de l'historique de l'intelligence artificielle (IA), définissant l'IA comme l'ensemble des théories et techniques visant à simuler l'intelligence humaine. Il aborde également les différentes applications, risques, cadres juridiques, métiers associés et les évolutions futures de l'IA, tout en soulignant la distinction entre l'IA faible et forte. L'importance de l'apprentissage, des systèmes experts et des grandes entreprises technologiques investissant dans l'IA est également discutée.



























































































































































































































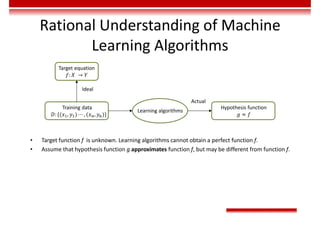






















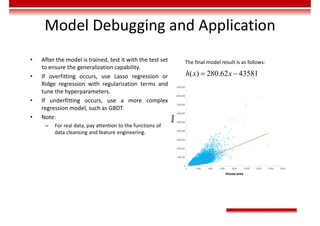
![Machine Learning Performance
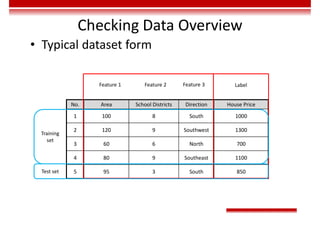
Evaluation - Regression
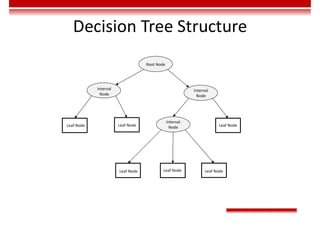
• The closer the Mean Absolute Error (MAE) is to 0, the better the model can fit the training data.
𝑀𝐴𝐸 =
1
m
𝑦 − 𝑦
• Mean Square Error (MSE)
𝑀𝑆𝐸 =
1
m
𝑦 − 𝑦
• The value range of R2
is (–∞, 1]. A larger value indicates that the model can better fit the training data. TSS
indicates the difference between samples. RSS indicates the difference between the predicted value and
sample value.
𝑅 = 1 −
𝑅𝑆𝑆
𝑇𝑆𝑆
= 1 −
∑ 𝑦 − 𝑦
∑ 𝑦 − 𝑦](https://image.slidesharecdn.com/aicourse-230214201310-cad54a70/85/AI_course-pdf-311-320.jpg)


















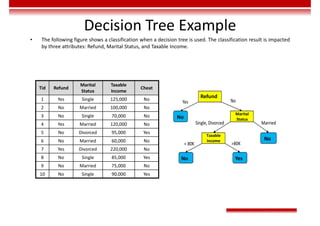











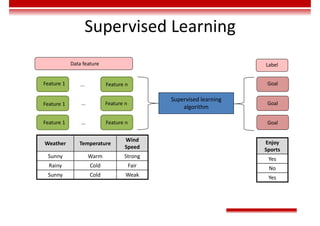
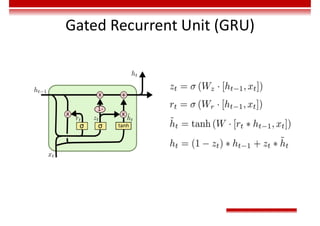
![Single-Layer Perceptron
• Input vector: 𝑋 = [𝑥 , 𝑥 , … , 𝑥 ]
• Weight: 𝑊 = [𝜔 , 𝜔 , … , 𝜔 ] , in which 𝜔 is the offset.
• Activation function: 𝑂 = 𝑠𝑖𝑔𝑛 𝑛𝑒𝑡 =
1, 𝑛𝑒𝑡 > 0,
−1, 𝑜𝑡ℎ𝑒𝑟𝑤𝑖𝑠𝑒.
• The preceding perceptron is equivalent to a classifier. It uses the high-dimensional 𝑋 vector as the input and performs
binary classification on input samples in the high-dimensional space. When 𝑾𝑻𝐗 > 0, O = 1. In this case, the samples
are classified into a type. Otherwise, O = −1. In this case, the samples are classified into the other type. The boundary of
these two types is 𝑾𝑻𝐗 = 0, which is a high-dimensional hyperplane.
Classification plane
𝐴𝑥 + 𝐵𝑦 + 𝐶𝑧 + 𝐷 = 0
Classification hyperplane
𝑊 X + 𝑏 = 0
Classification line
𝐴𝑥 + 𝐵𝑦 + 𝐶 = 0
Classification point
𝐴𝑥 + 𝐵 = 0
𝑛𝑒𝑡 = 𝜔 𝑥 = 𝑾𝑻
𝐗
𝑥
𝑥
𝑥](https://image.slidesharecdn.com/aicourse-230214201310-cad54a70/85/AI_course-pdf-371-320.jpg)



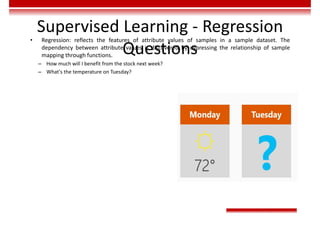
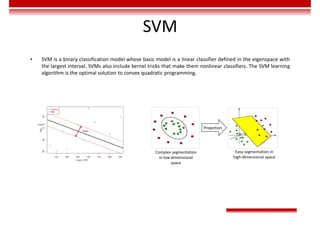
![Gradient Descent and Loss
Function
• The gradient of the multivariate function 𝑜 = 𝑓 𝑥 = 𝑓 𝑥 , 𝑥 , … , 𝑥 at 𝑋 = [𝑥 , 𝑥 , … , 𝑥 ] is shown as follows:
𝛻𝑓 𝑥 , 𝑥 , … , 𝑥 = [ , , … , ] | ,
The direction of the gradient vector is the fastest growing direction of the function. As a result, the direction of the negative
gradient vector −𝛻𝑓 is the fastest descent direction of the function.
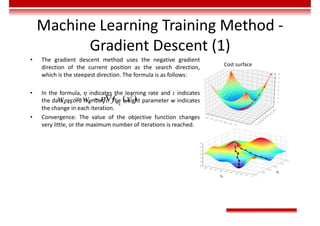
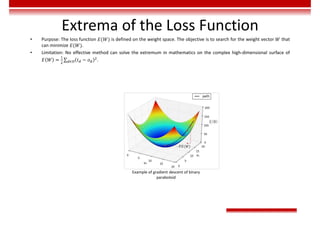
• During the training of the deep learning network, target classification errors must be parameterized. A loss function
(error function) is used, which reflects the error between the target output and actual output of the perceptron. For a
single training sample x, the most common error function is the Quadratic cost function.
𝐸 𝑤 = ∑ 𝑡 − 𝑜
∈ ,
In the preceding function, 𝑑 is one neuron in the output layer, D is all the neurons in the output layer, 𝑡 is the target
output, and 𝑜 is the actual output.
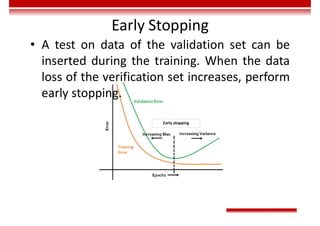
• The gradient descent method enables the loss function to search along the negative gradient direction and update the
parameters iteratively, finally minimizing the loss function.](https://image.slidesharecdn.com/aicourse-230214201310-cad54a70/85/AI_course-pdf-377-320.jpg)




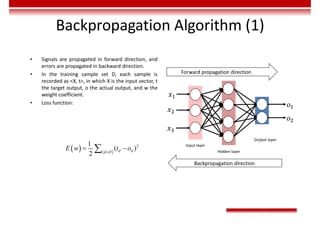







































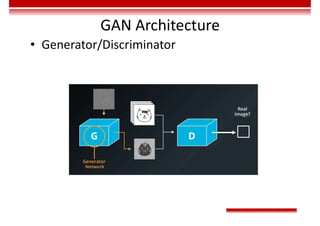

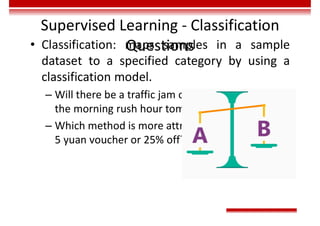
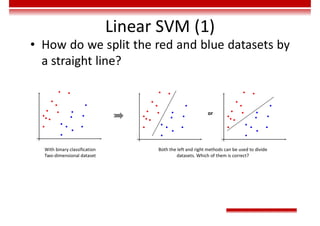
![Training Rules of GAN
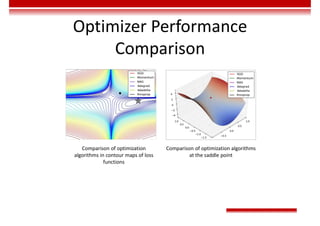
• Optimization objective:
– Value function
– In the early training stage, when the outcome of G is
very poor, D determines that the generated sample
is fake with high confidence, because the sample is
obviously different from training data. In this case,
log(1-D(G(z))) is saturated (where the gradient is 0,
and iteration cannot be performed). Therefore, we
choose to train G only by minimizing [-log(D(G(z))].
( )
( ) [ ( )] [ ( ( ( )
1 ]
, ))
data z z
x p x z p
G D
minmaxV D G E logD x E log D G z
( )](https://image.slidesharecdn.com/aicourse-230214201310-cad54a70/85/AI_course-pdf-434-320.jpg)







![Comprendre l’intelligence artificielle [webinaire]](https://cdn.slidesharecdn.com/ss_thumbnails/technologiawebinaireintelligenceartificielleclaudemarson01042019-190403213713-thumbnail.jpg?width=640&height=640&fit=bounds)












































