Télécharger pour lire hors ligne















![[Smile] atelier spark - salon big data 13032018](https://image.slidesharecdn.com/smile-atelierspark-salonbigdata13032018-180328084149/85/Smile-atelier-spark-salon-big-data-13032018-18-320.jpg)

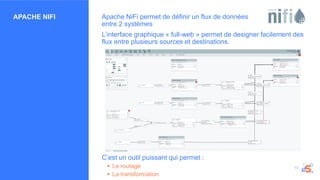
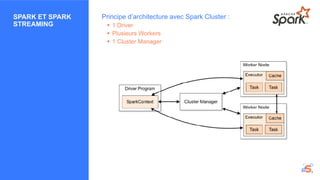
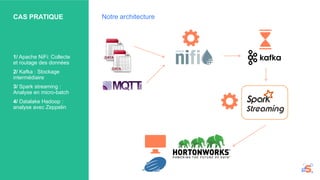
L'atelier se concentre sur les enjeux du big data et du traitement des données en temps réel à l'aide de technologies comme Apache NiFi, Kafka et Spark. Ces outils permettent de collecter, router, stocker et analyser des données, facilitant ainsi la prise de décision rapide dans divers secteurs, tels que la finance et l'IoT. Les participants sont invités à explorer des cas pratiques et à poser des questions sur l'implémentation de solutions adaptées à leurs besoins numériques.















































