Téléchargé 88 fois
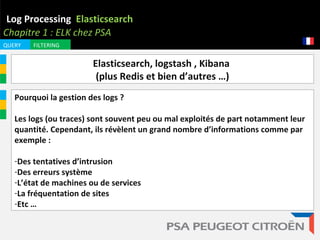

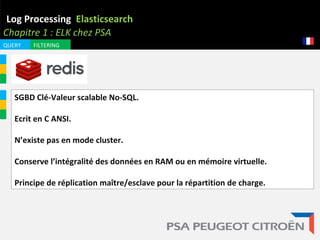




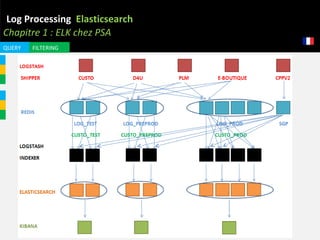

Le document aborde l'importance de la gestion des logs, démontrant comment ces derniers peuvent révéler diverses informations critiques, comme des tentatives d'intrusion et des erreurs système. Il présente l'outil ELK (Elasticsearch, Logstash, Kibana) comme une solution efficace pour la collecte, l'analyse et le stockage des logs, en mettant l'accent sur ses capacités et son architecture. Enfin, il évoque le potentiel futur de cette technologie dans le traitement des données, notamment dans le contexte des voitures connectées.































![[Sildes] plateforme centralisée d’analyse des logs des frontaux http en temps...](https://cdn.slidesharecdn.com/ss_thumbnails/sildesplateformecentralisedanalysedeslogsdesfrontauxhttpentempsreldansunmilieuvirtualis-160429150553-thumbnail.jpg?width=640&height=640&fit=bounds)











