Téléchargé 26 fois












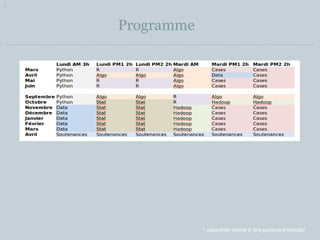



Le document présente un programme de formation pour devenir actuaire data scientist, débutant en septembre 2014, comprenant divers modules sur la programmation, le datamining, et le machine learning. La formation se déroule sur plusieurs mois avec des cours théoriques et des projets pratiques, visant à appliquer des compétences en data science à des problématiques actuarielle. Les participants devront réaliser un projet avec soutenance et passer des examens pour obtenir le diplôme de l'institut du risk management.











































![Orientation_CP[1]_pour_data_science.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/orientationcp1-250502074627-9c8b835f-thumbnail.jpg?width=640&height=640&fit=bounds)











































