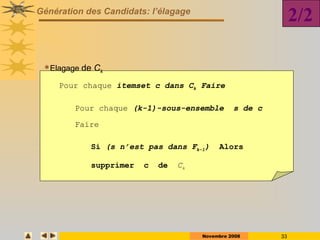
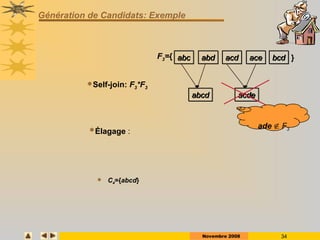
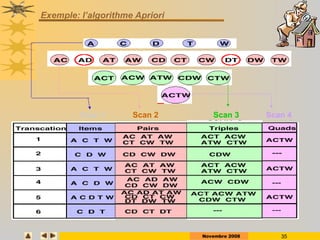
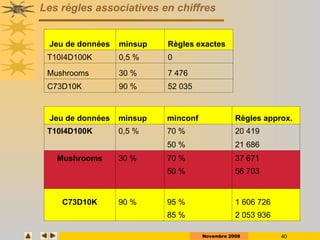
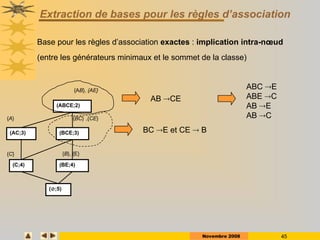
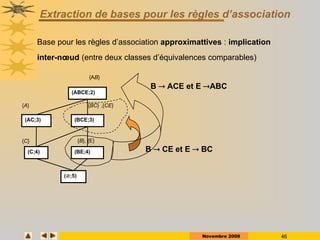
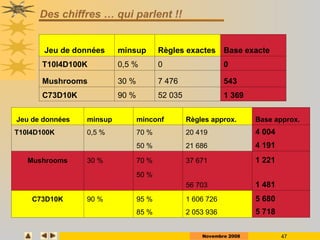
Le document présente des techniques de fouille de données, en particulier l'extraction de règles associatives, en expliquant leur utilité pour la découverte de connaissances cachées dans de grandes quantités d'informations. Il aborde également des technologies comme Apriori et FP-Growth pour identifier des itemsets fréquents ainsi que des applications variées telles que l'analyse de marché et la détection de fraudes. Enfin, il décrit des approches pour réduire la taille des ensembles fréquents et améliorer l'extraction de règles associatives.










































![Novembre 2008 65
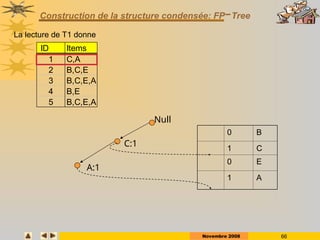
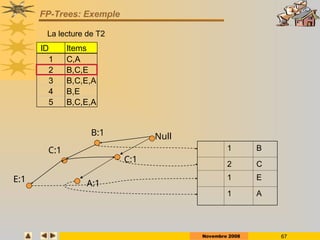
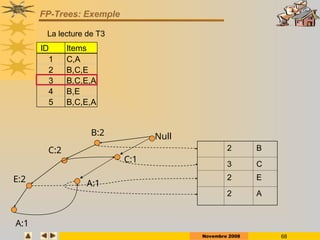
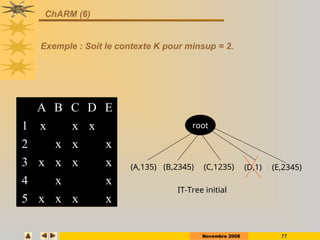
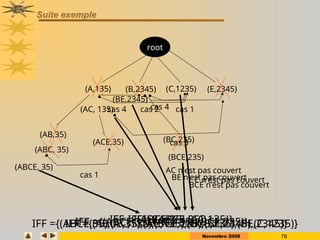
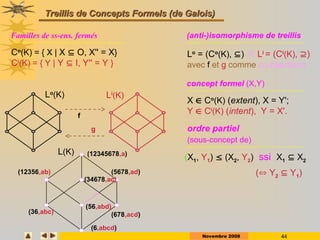
Construction de la structure condensée: FP-Tree
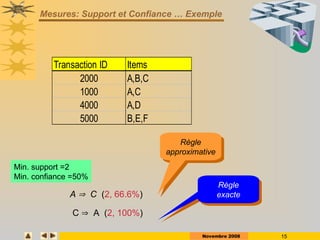
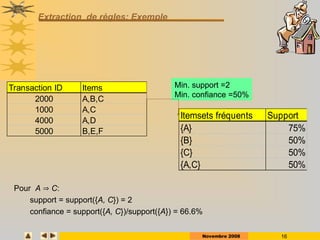
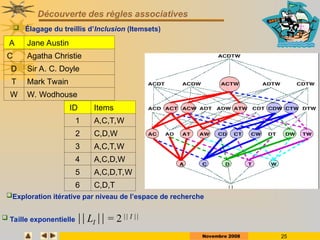
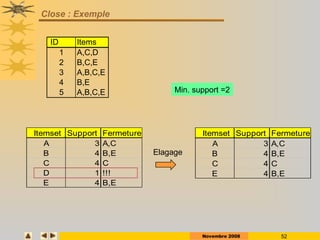
ID Items
1 A,C,D
2 B,C,E
3 A,B,C,E
4 B,E
5 A,B,C,E
1. On construit la liste « triée »: L = [B:4, C:4, E:4, A:3]
2. On parcourt une 2ème fois la base. On lit les transactions selon l’ordre des items
dans L
Min. support =2
ID Items
1 C,A
2 B,C,E
3 B,C,E,A
4 B,E
5 B,C,E,A](https://image.slidesharecdn.com/dm0809-p1-250124222732-9fe87f47/85/DM_0809-P1rkllllklhulkjeuljulkjulkjlejkluel-ppt-65-320.jpg)