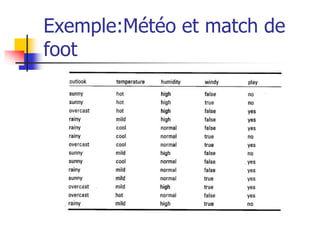
Le document présente une méthode automatique pour découvrir des relations intéressantes entre des objets à l'aide de règles d'association de la forme x ⇒ y, en utilisant des indicateurs tels que le support et la confiance. Il décrit l'algorithme a priori pour générer des ensembles d'items fréquents à partir de données et mentionne diverses applications pratiques dans des domaines tels que l'analyse de marché et la détection des fraudes. Malgré son efficacité, la méthode est coûteuse en termes de calcul et peut produire des règles triviales.

![Motivations et généralités
Approche automatique pour découvrir des relations /
corrélations intéressantes entre des objets
Règles de la forme: X Y [support, confidence]
X et Y peuvent être composés de conjonctions
Support P(X Y) = P(X et Y)
Confidence P(X Y) = P( Y | X) = P(X et Y)/P(X)
Applications:
Utilisé pour analyser le panier de la ménagère
Design des rayons dans les supermarchés, ventes croisées,
segmentation du marché, design des catalogues de ventes
Détection des fraudes
Gestion des stocks](https://image.slidesharecdn.com/associations5-230330222151-e635cec3/85/associations5-ppt-2-320.jpg)
![Exemples de règles
Règle booléenne:
achète(x, “SQLServer”) ^ achète(x,
“DMBook”) achète(x, “DBMiner”) [0.2%,
60%]
Règle quantitative:
age(x, “30..39”) ^ salaire(x, “42..48K”)
achète(x, “PC”) [1%, 75%]](https://image.slidesharecdn.com/associations5-230330222151-e635cec3/85/associations5-ppt-3-320.jpg)

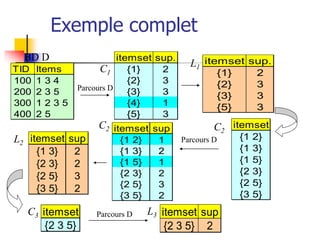
![L’algorithme A Priori [nom,
année]
Un item est une paire (attribut, valeur)
Un ensemble d’items regroupe des items
(sans duplication)
Principe de l’algorithme A Priori:
Génération d’ensembles d’items
Calcul des fréquences des ensembles d’items
On garde les ensembles d’items avec un support
minimum: les ensembles d’items fréquents
On ne génère et on ne garde que les règles avec
une confidence minimum](https://image.slidesharecdn.com/associations5-230330222151-e635cec3/85/associations5-ppt-5-320.jpg)










![Autre algorithme
L’algorithme d’arbre de modèles
fréquents (Frequent-pattern tree)
[name, année]](https://image.slidesharecdn.com/associations5-230330222151-e635cec3/85/associations5-ppt-18-320.jpg)

















