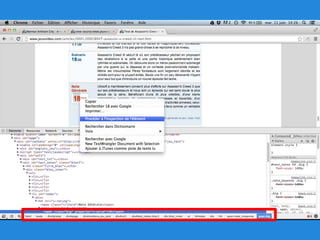
Ce document explique comment extraire des données d'une page web en utilisant R, en se concentrant sur des méthodes telles que 'readHTMLTable' et le package 'css'. Il fournit également des détails sur la structure d'un document HTML, les attributs et les sélecteurs CSS nécessaires pour cibler des éléments précis. En conclusion, il encourage l'utilisation d'outils de développement pour inspecter les éléments et faciliter l'extraction de données.



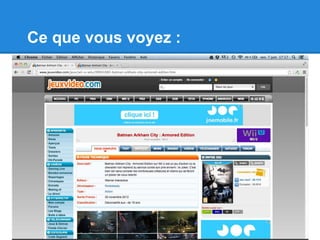
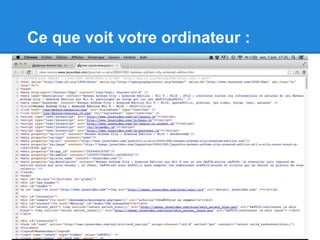

![Si les données sont dans un tableau
• readHTMLtable du package XML
library(XML)
url <- "http://www.jeuxvideo.com/articles/listes/tests-wiiu-type-0-note-0-tri-0-0.htm"
tables <- readHTMLTable(url)
# la fonction renvoie une liste contenant tous les tableaux
# de la page y compris des tableaux invisibles.
# Il est bon de vérifier leur taille afin d'identifier
# celui qui vous intéresse
lapply(tables, dim)
tables[[3]]](https://image.slidesharecdn.com/extractiondonneesweb-130716141717-phpapp02/85/Extraction-donnees-web-6-320.jpg)
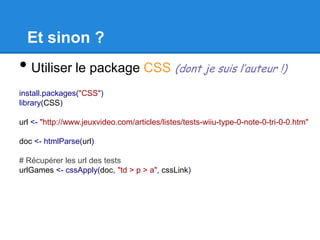







![Les sélecteurs CSS
• *[attr] : éléments possédant l’attribut « attr »
• *[attr='value'] : éléments dont l’attribut « attr »
est égal à « value »](https://image.slidesharecdn.com/extractiondonneesweb-130716141717-phpapp02/85/Extraction-donnees-web-15-320.jpg)