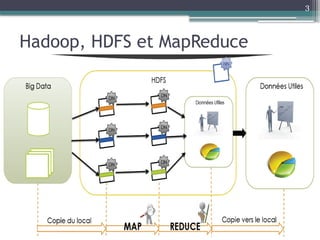
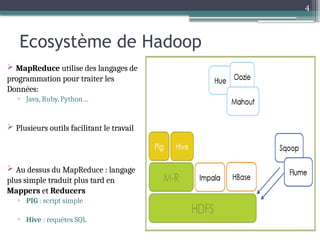
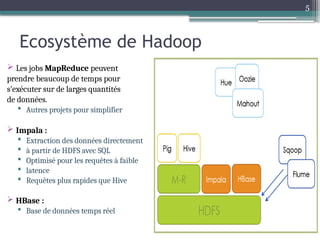
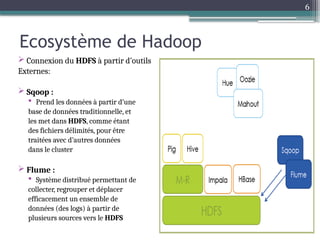
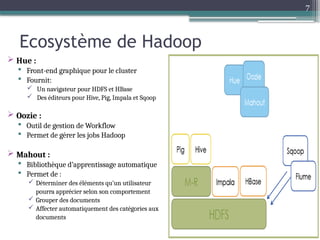
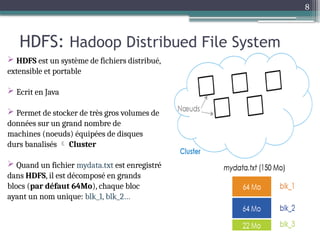
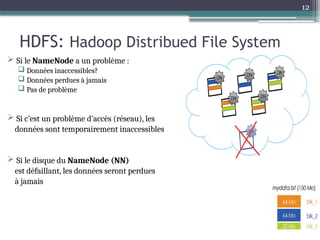
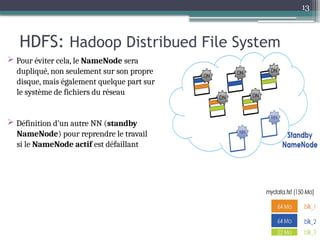
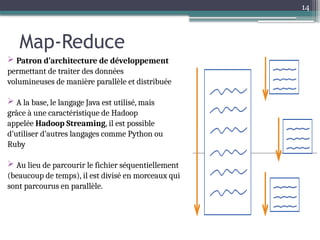
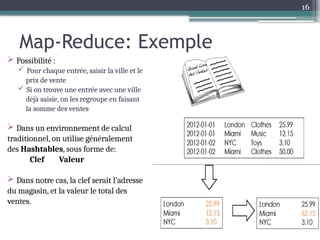
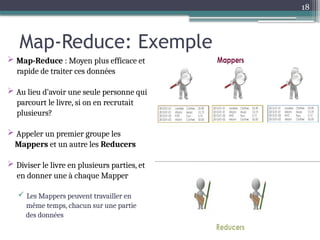
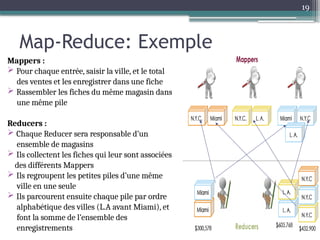
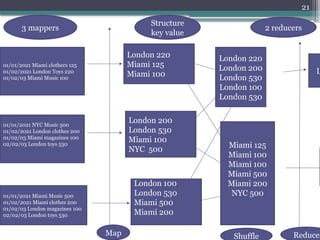
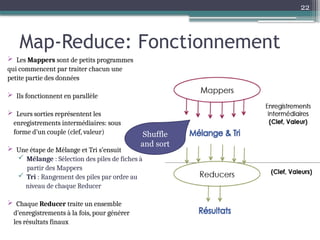
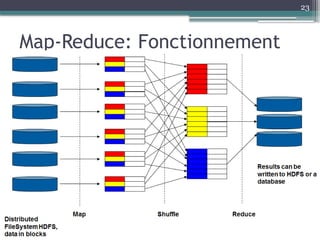
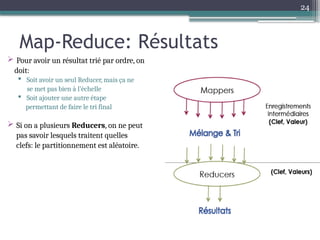
Le document présente Hadoop, un framework open source pour le traitement de grandes masses de données, divisé en stockage (HDFS) et traitement (MapReduce). Il détaille aussi l'écosystème de Hadoop, incluant divers outils comme Hive, Pig, et HBase, qui facilitent le traitement et la gestion des données. Enfin, il explique le fonctionnement de MapReduce, qui permet un traitement parallèle des données en utilisant des mappers et des reducers pour améliorer l'efficacité.