Téléchargé 137 fois











![3 – récupération automatique de données insee.fr
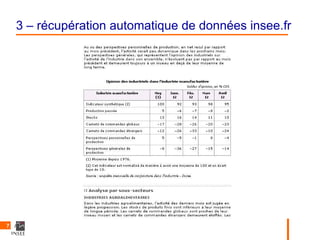
Tableaux
$tableau1
Soldes dÂ’opinion, en % CVS NA NA NA NA NA 1
Industrie manufacturière Moy (1) Janv. 12 Fév. 12 Mars 12 Avril 12
2 Indicateur synthétique (2) 100 92 93 98 95
3 Production passée 5 –6 –7 –8 –2
4 Stocks 13 16 14 11 10
5 Carnets de commandes globaux –17 –28 –26 –20 –23
6 Carnets de commandes étrangers –12 –26 –33 –10 –24
7 Perspectives personnelles de production 5 –5 –1 8 –4
8 Perspectives générales de production –8 –36 –27 –15 –14
tableaux$tableau2[5,5]
[1] –20
13](https://image.slidesharecdn.com/gurfltaur-webscrapping-2mai2012v2-120508110602-phpapp02/85/Premier-pas-de-web-scrapping-avec-R-13-320.jpg)

![3 – récupération automatique de données insee.fr
rev_tableau1 <- paste(mois_revision, "- révision de", tableaux$tableau1[,1],":",
tableaux$tableau1[,5],"/", tableaux_moisprec$tableau1[,6])
rev_tableaux1_mf<-rev_tableau1[2:8]
rev_tableaux1_mf
[1] "mars 2012 - révision de Indicateur synthétique (2) : 98 / 96"
[2] "mars 2012 - révision de Production passée : –8 / –10"
[3] "mars 2012 - révision de Stocks : 11 / 9"
[4] "mars 2012 - révision de Carnets de commandes globaux : –20 / –23"
[5] "mars 2012 - révision de Carnets de commandes étrangers : –10 / –15"
[6] "mars 2012 - révision de Persp. personnelles de production : 8 / 6"
[7] "mars 2012 - révision de Persp. générales de production : –15 / –15"
15](https://image.slidesharecdn.com/gurfltaur-webscrapping-2mai2012v2-120508110602-phpapp02/85/Premier-pas-de-web-scrapping-avec-R-15-320.jpg)
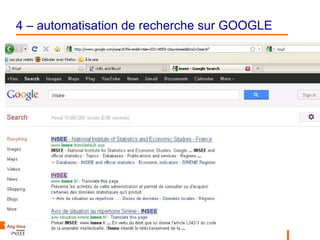




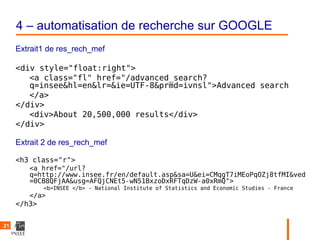



Le document présente une introduction au web scraping, expliquant sa définition, son fonctionnement et les outils disponibles en R pour extraire et manipuler des données. Il propose des exemples pratiques d'automatisation de la récupération de données d'INSEE et d'effectuer des recherches sur Google. Enfin, il aborde les possibilités et les défis associés au web scraping, ainsi que des considérations éthiques.

































































