Télécharger en tant que PDF, PPTX








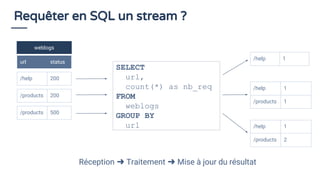

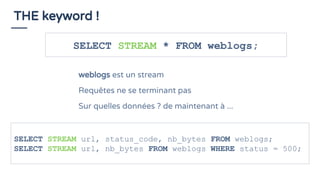



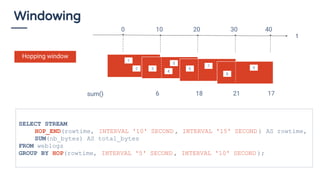



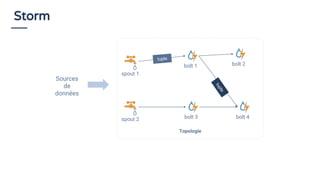
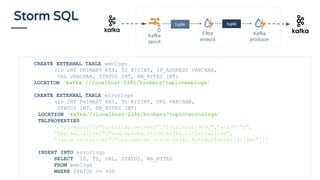
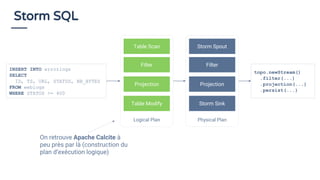


La présentation de Bruno Bonnin aborde l'utilisation de SQL dans le traitement de flux de données en temps réel, soulignant son importance en tant que standard accessible même aux non-techniciens, comme ceux d'Uber. Il explique les différences clés entre le traitement par lots et le traitement en continu, tout en présentant des exemples pratiques de requêtes SQL sur des flux de données à l'aide de la plateforme de traitement de flux Apache Flink. Enfin, il met en avant les capacités d'Apache Calcite pour optimiser et exécuter des requêtes SQL sur des données en streaming, illustrant ainsi la convergence entre le traitement de flux et SQL.





![[JSS2015] Azure SQL Data Warehouse - Azure Data Lake](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-sqldwh-adl-151211085004-thumbnail.jpg?width=640&height=640&fit=bounds)













![[Devoxx MA 2023] R2DBC = R2D2 + JDBC (enfin presque...)](https://cdn.slidesharecdn.com/ss_thumbnails/devoxxma2023r2dbcr2d2jdbcenfinpresque-231013131604-9c258ce9-thumbnail.jpg?width=640&height=640&fit=bounds)


















