Télécharger en tant que PDF, PPTX










...
execEnv.execute()](https://image.slidesharecdn.com/jsc2018-streamprocessingetsql-180914163524/85/Stream-processing-et-SQL-14-320.jpg)
...
execEnv.execute()](https://image.slidesharecdn.com/jsc2018-streamprocessingetsql-180914163524/85/Stream-processing-et-SQL-15-320.jpg)

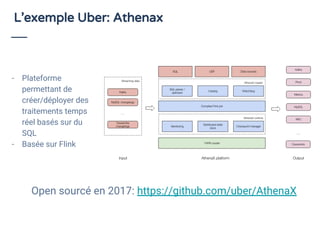






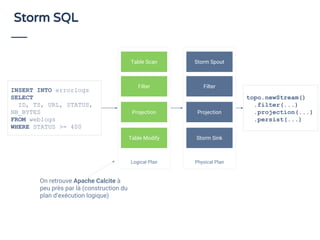

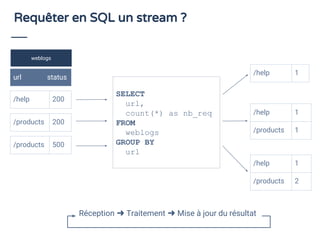
Le document aborde le traitement de flux de données en utilisant SQL, en démontrant son efficacité et son adoption croissante, même parmi les utilisateurs non techniques. Il présente Apache Calcite comme un outil pour la gestion des métadonnées et l'exécution de requêtes SQL sur des flux, et souligne l'importance de SQL pour unifier les acteurs autour de l'analyse de données en temps réel. En conclusion, une adoption accrue du streaming de données est prévue d'ici 2020, avec une attention particulière sur la nécessité d'outils accessibles pour les développeurs.

















![[USI] Lambda-Architecture : comment réconcilier BigData et temps-réel](https://cdn.slidesharecdn.com/ss_thumbnails/preslambdaarch-v3-slideshare-140617091602-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)









![[Devoxx MA 2023] R2DBC = R2D2 + JDBC (enfin presque...)](https://cdn.slidesharecdn.com/ss_thumbnails/devoxxma2023r2dbcr2d2jdbcenfinpresque-231013131604-9c258ce9-thumbnail.jpg?width=640&height=640&fit=bounds)












