Téléchargé 19 fois














![Le requêtage
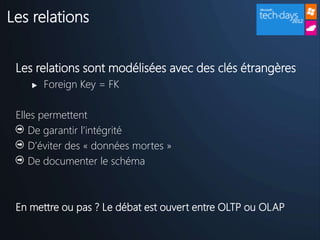
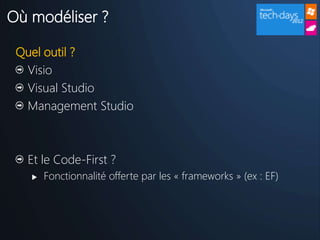
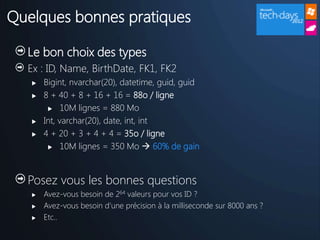
Un réel paradigme
Row by Row Logique ensembliste
for (int i=0; i++; i<maCol.Count)
{
Update maTable
if (maCol[i].PropertyB = "val") Set colonneA = 1
{
Where colonneB = 'val'
maCol[i].PropertyA = 1;
maCol[i].Update();
}
}](https://image.slidesharecdn.com/sqlserveretlesdveloppeurs-130411030928-phpapp01/85/SQL-Server-et-les-developpeurs-17-320.jpg)
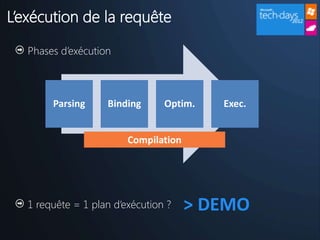




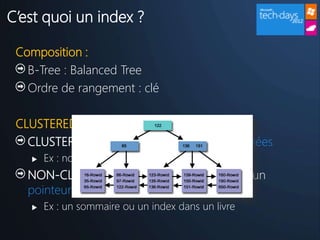




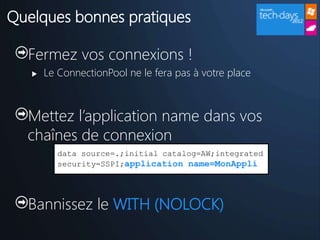






Le document présente l'utilisation de SQL Server dans les projets de développement, les avantages de la modélisation de données, et l'importance de l'indexation et de la sécurité. Il souligne également les défis liés à l'administration d'une base de données et propose des bonnes pratiques pour optimiser les performances. Enfin, il encourage les participants à se connecter avec des experts et à explorer les nouvelles offres de Microsoft sur SQL Server.















































