Télécharger en tant que PDF, PPTX










...
execEnv.execute()](https://image.slidesharecdn.com/streamprocessingetsql-181030171404/85/Stream-processing-et-SQL-14-320.jpg)
...
execEnv.execute()](https://image.slidesharecdn.com/streamprocessingetsql-181030171404/85/Stream-processing-et-SQL-15-320.jpg)

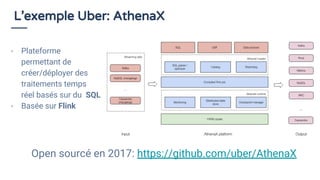




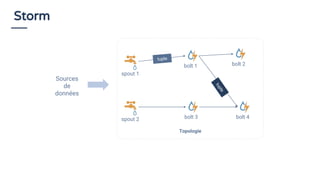
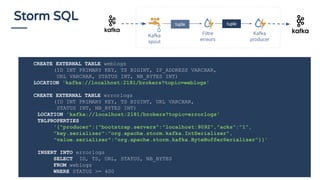
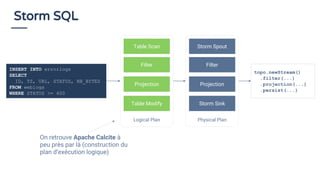

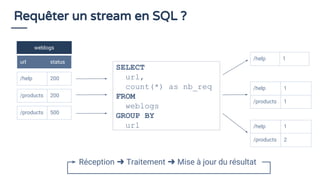
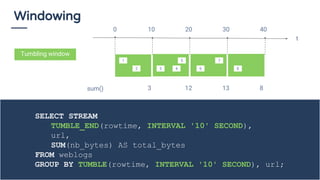
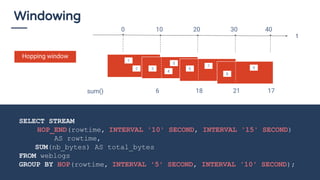
Le document traite du traitement de flux de données et de l'utilisation du SQL en 2018 pour interroger ces flux, en soulignant que le SQL reste un standard précieux. Il explore des concepts tels que la définition de fenêtres de temps et l'utilisation d'Apache Calcite pour optimiser les requêtes SQL sur des flux de données. En conclusion, il est anticipé qu'une majorité d'organisations adopteront le streaming de données pour des analyses en temps réel d'ici 2020, mettant en avant l'importance d'une approche accessible pour tous les acteurs impliqués.
















![[USI] Lambda-Architecture : comment réconcilier BigData et temps-réel](https://cdn.slidesharecdn.com/ss_thumbnails/preslambdaarch-v3-slideshare-140617091602-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










![[Devoxx MA 2023] R2DBC = R2D2 + JDBC (enfin presque...)](https://cdn.slidesharecdn.com/ss_thumbnails/devoxxma2023r2dbcr2d2jdbcenfinpresque-231013131604-9c258ce9-thumbnail.jpg?width=640&height=640&fit=bounds)


















