






![#JSS2014
Map Reduce
class CompositeKeyWritableRSJ implements Writable,
WritableComparable<CompositeKeyWritableRSJ> {
// Data members
private String joinKey;// EmployeeID
private int sourceIndex;// 1=Employee data; 2=Salary (current) data; 3=Salary historical data
public CompositeKeyWritableRSJ() {
}
public CompositeKeyWritableRSJ(String joinKey, int sourceIndex) {
this.joinKey = joinKey;
this.sourceIndex = sourceIndex;
}
@Override
public String toString() {
return (new StringBuilder().append(joinKey).append("t").append(sourceIndex)).toString();
}
public void readFields(DataInput dataInput) throws IOException {
joinKey = WritableUtils.readString(dataInput);
sourceIndex = WritableUtils.readVInt(dataInput);
}
public void write(DataOutput dataOutput) throws IOException {
WritableUtils.writeString(dataOutput, joinKey);
WritableUtils.writeVInt(dataOutput, sourceIndex);
}
public int compareTo(CompositeKeyWritableRSJ objKeyPair) {
int result = joinKey.compareTo(objKeyPair.joinKey);
if (0 == result) {
result = Double.compare(sourceIndex, objKeyPair.sourceIndex);
}
return result;
}
public String getjoinKey() {
return joinKey;
}
public void setjoinKey(String joinKey) {
this.joinKey = joinKey;
}
public int getsourceIndex() {
return sourceIndex;
}
public void setsourceIndex(int sourceIndex) {
this.sourceIndex = sourceIndex;
}
}
public class MapperRSJ extends
Mapper<LongWritable, Text, CompositeKeyWritableRSJ, Text> {
CompositeKeyWritableRSJ ckwKey = new CompositeKeyWritableRSJ();
Text txtValue = new Text("");
int intSrcIndex = 0;
StringBuilder strMapValueBuilder = new StringBuilder("");
List<Integer> lstRequiredAttribList = new ArrayList<Integer>();
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
// {{
// Get the source index; (employee = 1, salary = 2)
// Added as configuration in driver
FileSplit fsFileSplit = (FileSplit) context.getInputSplit();
intSrcIndex = Integer.parseInt(context.getConfiguration().get(
fsFileSplit.getPath().getName()));
// }}
// {{
// Initialize the list of fields to emit as output based on
// intSrcIndex (1=employee, 2=current salary, 3=historical salary)
if (intSrcIndex == 1) // employee
{
lstRequiredAttribList.add(2); // FName
lstRequiredAttribList.add(3); // LName
lstRequiredAttribList.add(4); // Gender
lstRequiredAttribList.add(6); // DeptNo
} else // salary
{
lstRequiredAttribList.add(1); // Salary
lstRequiredAttribList.add(3); // Effective-to-date (Value of
// 9999-01-01 indicates current
// salary)
}
// }}
}
public class ReducerRSJ extends
Reducer<CompositeKeyWritableRSJ, Text, NullWritable, Text> {
StringBuilder reduceValueBuilder = new StringBuilder("");
NullWritable nullWritableKey = NullWritable.get();
Text reduceOutputValue = new Text("");
String strSeparator = ",";
private MapFile.Reader deptMapReader = null;
Text txtMapFileLookupKey = new Text("");
Text txtMapFileLookupValue = new Text("");
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
// {{
// Get side data from the distributed cache
Path[] cacheFilesLocal = DistributedCache.getLocalCacheArchives(context
.getConfiguration());
for (Path eachPath : cacheFilesLocal) {
if (eachPath.getName().toString().trim()
.equals("departments_map.tar.gz")) {
URI uriUncompressedFile = new File(eachPath.toString()
+ "/departments_map").toURI();
initializeDepartmentsMap(uriUncompressedFile, context);
}
}
// }}
}](https://image.slidesharecdn.com/s143-hive-141231034716-conversion-gate01/85/JSS2014-Hive-ou-la-convergence-entre-datawarehouse-et-Big-Data-7-320.jpg)

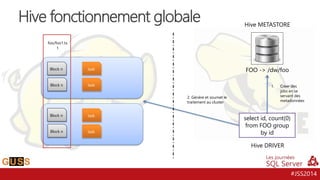
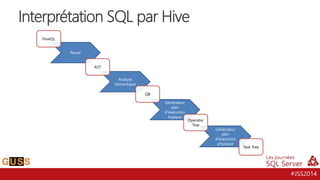
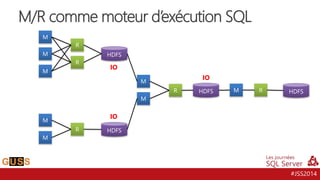

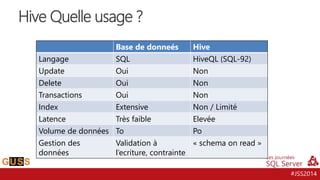
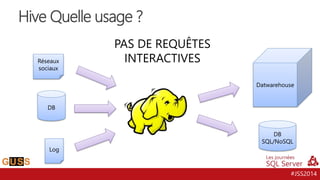



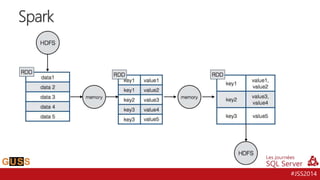

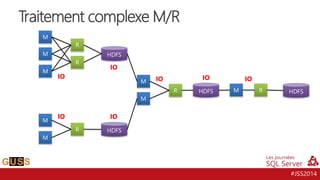
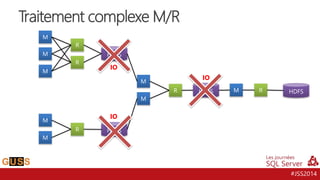
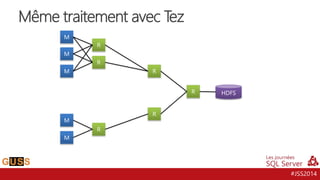



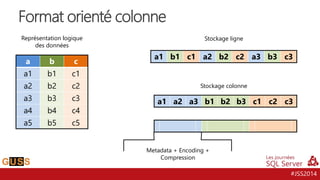





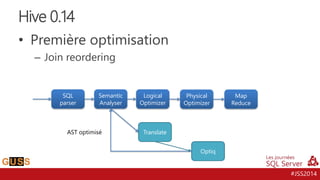







Le document présente un aperçu des Journées SQL Server 2014, mettant l'accent sur l'intégration de Hive avec Hadoop pour le traitement de données Big Data. Il aborde l'historique, la structure et les fonctionnalités de Hive, ainsi que les évolutions récentes telles que l'optimisation des performances via des formats de stockage en colonnes et la vectorisation. La conversation tourne autour de la convergence entre les technologies SQL et Big Data, avec des références à divers outils et méthodologies comme Impala et Tez.





































![[JSS2015] Azure SQL Data Warehouse - Azure Data Lake](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-sqldwh-adl-151211085004-thumbnail.jpg?width=640&height=640&fit=bounds)






















![[JSS2015] Power BI Dev](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-powerbiapirest-151211085002-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] Nouveautés SQL Server 2016:Sécurité,Temporal & Stretch Tables](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-sql2016-151211084830-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] Query Store](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-querystore-151211084816-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] 3 DMV's pour evaluer les indexs](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-indexdmv-final-151211084704-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] Power BI: Nouveautés archi et hybrides](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-powerbi-151211084523-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] Infra bi#4 - le scale out](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-infrabi4-lescaleout-151211084516-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] In memory and operational analytics](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-inmemoryandoperationalanalytics-151211084342-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] Eradiction des deadlocks](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-eradictiondesdeadlocks-151211084151-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] Architectures Lambda avec Azure Stream Analytics](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-streamanalytics-151211084144-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] - Azure automation](https://cdn.slidesharecdn.com/ss_thumbnails/azureautomation-151211083408-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] AlwaysOn 2016](https://cdn.slidesharecdn.com/ss_thumbnails/alwayson2016-151211083219-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] - Document db et nosql](https://cdn.slidesharecdn.com/ss_thumbnails/documentdbetnosql-151211083215-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] x events](https://cdn.slidesharecdn.com/ss_thumbnails/20151201-jss2015-xevents-151211083007-thumbnail.jpg?width=640&height=640&fit=bounds)
![[JSS2015] Nouveautés SSIS SSRS 2016](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015nouveautsssisssrs2016-151211082823-thumbnail.jpg?width=640&height=640&fit=bounds)
