Le document traite de l'intelligence artificielle (IA), de ses concepts de base, de ses disciplines connexes, et de son évolution historique. Il aborde les différentes approches en IA, les tests d'intelligence comme le test de Turing, et la conception d'agents intelligents, tout en présentant des applications concrètes dans divers domaines. Enfin, il souligne l'importance de la modélisation de problèmes et l'utilisation de recherches dans les graphes pour la résolution de problèmes complexes.







![Perspective historique de l’IA
“The proposal [for the meeting] is to proceed on the basis of the conjecture that
every aspect of . . . intelligence can in principle be so precisely described that a
machine can be made to simulate it”
8](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-8-320.jpg)
![Perspective historique de l’IA
● De 1956 jusqu’au milieu des années 1980, les recherches en IA sont dominées
par des approches à base de connaissances (knowledge based).
◆ Critique : L’IA conventionnelle [knowledge based] n’est qu’une « application de
règles », mais l’intelligence [humaine] ne l’est pas (Haugeland)
● Dès les années 1980, les approches comportementales deviennent populaire
(behaviour based ou situated AI).
◆ Leitmotiv : La représentation des connaissances n’est pas nécessaire, elle est
même nuisible (Brooks)
● Dès les années 1990, les approches probabilistes deviennent populaire
(Markov decision processes, Hidden Markov Models, Bayesian networks)
◆ Leitmotiv : L’inférence nécessaire [pour l’IA] est probabiliste, mais pas logique.
● Aujourd’hui, les approches connexionnistes
◆ Leitmotiv : Orienté-données, mieux représentatifs de la réalité du domaine
d’application.](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-9-320.jpg)

















![Exemple : Aspirateur robotisé
● Observations (données sensorielles) : position et état des lieux
Par exemple : [A,Clean],
[A,Dirty],
[B,Clean],
● Actions : Left, Right, Suck, NoOp
27](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-27-320.jpg)
![Exemple : Aspirateur robotisé
● f :
[A,Clean] → Right
[A,Dirty] → Suck
…
[A,Clean] [A,Clean] [A,Dirty] → Suck
[A,Clean] [A,Clean] [A,Clean] → Right
…
28](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-28-320.jpg)

































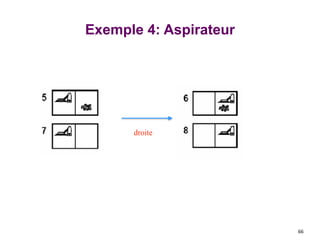
![Exemple 4: Aspirateur
● une connaissance complète:
l’agent connait exactement un
état physique.
● start : [5].
● solution : <droite, aspirer>
62](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-62-320.jpg)







![Recherche en profondeur d’abord
function depth-first-search
begin
Open := [Start]; Closed := []; % initialize
while Open != [] do begin % while there are states to be tried
remove leftmost state from open, called it X;
if X is a goal then return SUCCESS % goal found
else begin
generate children of X;
put X on closed;
discard children of X if already on open or closed;
end
put remaining children on left end of open %heap
end
return FAIL % no states left
End.
71](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-71-320.jpg)
![Trace d’exécution
1. open = [A]; closed = []
2. open = [B, C, D]; closed = [A]
3. open = [E, F
, C, D]; closed = [B, A]
4. open = [K, L, F
, C, D]; closed = [E, B, A]
5. open = [S, L, F
, C, D]; closed = [K, E, B, A]
6. open = [L, F
, C, D]; closed = [S, K, E, B, A]
7. open = [T, F
, C, D]; closed = [L, S, K, E, B, A]
8. open = [F
, C, D]; closed = [T, L, S, K, E, B, A]
9. open = [M,C,D]; as L is already on closed; closed =
[F
,T,L,S,K,E,B,A]
10. open = [C,D]; closed = [M,F
,T,L,S,K,E,B,A]
11. open = [G,H,D]; closed = [M,F
,T,L,S,K,E,B,A]
72](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-72-320.jpg)
![Recherche en largeur d’abord
function breadth-first-search
begin
Open := [Start]; Closed := []; % initialize
while Open != [] do begin % while there are states to be tried
remove leftmost state from open, called it X;
if X is a goal then return SUCCESS % goal found
else begin
generate children of X;
put X on closed;
discard children of X if already on open or closed; %loops
check
put remaining children on right end of open %queue
end
end
return FAIL % no states left
End.
73](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-73-320.jpg)
![Trace d’exécution
open = [A]; closed = []
open = [B, C, D]; closed = [A]
open = [C, D, E, F]; closed = [B, A]
open = [D, E, F
, G, H]; closed = [B, A]
open = [E, F
, G, H, I, J]; closed = [D, C, B, A]
open = [F
, G, H, I, K, L]; closed = [E, D, C, B, A]
open = [G, H, I, K, L, M]; (as L is already on
open) closed = [F
, E, D, C, B, A]
open = [H, I, K, L, M, N]; closed = [G, F
, E, D, C, B,
A]
and so on until either U is found or open = []
74](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-74-320.jpg)













































![Exemple d’Alpha-beta pruning
Valeur initial de α, β
α=−∞
β =+∞
α=−∞
β =+∞
α, β, transmis aux successeurs
[−∞,+∞]
Entre croches [, ]: Intervalle
des valeurs possibles pour le
nœud visité.
Faire une recherche en profondeur
jusqu’à la première feuille
120](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-120-320.jpg)
![α=−∞
β =+∞
α=−∞
β =3 [−∞,3]
[−∞,+∞]
MIN met à jour β, basé
sur les successeurs
121
Exemple d’Alpha-beta pruning](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-121-320.jpg)
![α=−∞
β =3
MIN met à jour β, basé
sur les successeurs.
Aucun changement.
α=−∞
β =+∞
[−∞,+∞]
[3,+∞]
122
Exemple d’Alpha-beta pruning](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-122-320.jpg)
![MAX met à jour α, basé sur les successeurs.
α=3
β =+∞
3 est retourné comme valuer
du noeud.
[3, +∞]
[3, 3]
123
Exemple d’d’Alpha-beta pruning](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-123-320.jpg)
![α=3
β =+∞
α=3
β =+∞
α, β, passés aux
successeurs
[3,+∞]
[3, 3]
[−∞,+∞]
124
Exemple d’d’Alpha-beta pruning](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-124-320.jpg)
![α=3
β =+∞
α=3
β =2
MIN met à jour β,
Basé sur les successeurs.
[3,+∞]
[3,3] [−∞,2]
125
Exemple d’d’Alpha-beta pruning](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-125-320.jpg)
![α=3
β =2
v =2
v≤α,
alors couper.
α=3
β =+∞
[−∞,2]
[3, 3]
126
Exemple d’d’Alpha-beta pruning](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-126-320.jpg)
![2 retourné comme
valeur du noeud.
MAX met à jour α, basé sur les enfants.
Pas de changement. α=3
β =+∞
[−∞,2]
[3, 3]
127
Exemple d’d’Alpha-beta pruning](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-127-320.jpg)
![,
α=3
β =+∞
α=3
β =+∞
α, β, passés aux enfants
[−∞,2]
[3,+∞]
[- ∞,+∞]
[3, 3]
128
Exemple d’d’Alpha-beta pruning](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-128-320.jpg)
![,
α=3
β =14
α=3
β =+∞
[−∞,2]
[3, 3]
[3,+∞]
[−∞,14]
MIN met à jour β,
Basé sur les enfants .
129
Exemple d’d’Alpha-beta pruning](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-129-320.jpg)
![,
α=3
β =5
α=3
β =+∞
[−∞,2]
[3, 3] [−∞,5]
[3,+∞]
MIN met à jour β,
Basé sur les enfants .
130
Exemple d’d’Alpha-beta pruning](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-130-320.jpg)
![α=3
β =+∞ 2 retourné comme
valeur du nœud.
2
[−∞,2]
[3, 3]
α=3
β =2
[2,2]
[3, 3]
131
Exemple d’d’Alpha-beta pruning](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-131-320.jpg)
![132
Exemple d’d’Alpha-beta pruning
Max calcule la valeur du nœud,
et se déplace vers le nœud ayant
cette valeur!
[2,2]
[−∞,2]](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-132-320.jpg)
















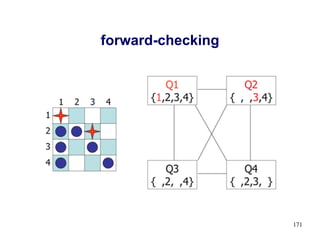
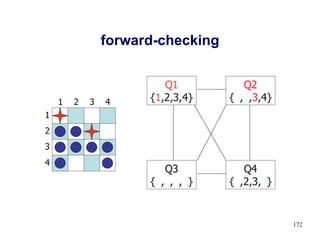
![Exemple: Sodoku
● Variables: V11, V12, …, V21, V22, …, V91, …, V99
● Domaines:
◆ Dom[Vij] = {1-9} pour les cellules vides
◆ Dom[Vij] = {k} une valeur fixe k pour les cellules pleines
149
V33=4
V88 = 3](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-149-320.jpg)





























































![Formules du Calcul Propositionnel …
213
Les formules (ou formules bien formées FBF) du calcul propositionnel,
notées par les lettres majuscules de l’alphabet (A, B, C …), sont définies par :
☯
1) Les atomes (vrai, P
, Q, R, …) sont des formules.
2) Si A et B sont deux formules, alors (A → B), (A ≡ B), (A ∧ B) et
(A ∨ B) sont des formules.
3) Si A est une formule, alors (⎤ A) est une formule.
Symboles ( ) et [ ] : utilisés pour grouper des formules.
☯
(P ∨ Q) ≡ R ≠ P ∨ (Q ≡ R)](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-213-320.jpg)

























































![Preuve par Résolution
Pour prouver que la formule f implique la formule g
• Transformer f en un ensemble de clauses
• Transformer ¬ g en un autre ensemble de clauses
• Combiner les 2 ensembles de clauses pour obtenir un seul ensemble
• Appliquer répétitivement la règle de résolution et la factorisation à cet
ensemble jusqu’à générer la clause vide, notée aussi [].
À chaque étape appliquer la règle de résolution à 2 clauses de l’ensemble courant ou
la factorisation à une clause de l’ensemble courant. Ajouter la clause résolvante
résultat ou le facteur à l’ensemble courant pour obtenir un nouvel ensemble, qui
devient l’ensemble courant de la prochaine étape. Arrêter quand l’ensemble contient la
clause vide.
271](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-271-320.jpg)


















![Example: air cargo transport
Init(At(C1, SFO) ∧ At(C2,JFK) ∧ At(P1,SFO) ∧ At(P2,JFK) ∧ Cargo(C1) ∧ Cargo(C2) ∧
Plane(P1) ∧ Plane(P2) ∧ Airport(JFK) ∧ Airport(SFO))
Goal(At(C1,JFK) ∧ At(C2,SFO))
Action(Load(c,p,a)
PRECOND: At(c,a) ∧At(p,a) ∧Cargo(c) ∧Plane(p) ∧Airport(a)
EFFECT: ¬At(c,a) ∧In(c,p))
Action(Unload(c,p,a)
PRECOND: In(c,p) ∧At(p,a) ∧Cargo(c) ∧Plane(p) ∧Airport(a)
EFFECT: At(c,a) ∧ ¬In(c,p))
Action(Fly(p,from,to)
PRECOND: At(p,from) ∧Plane(p) ∧Airport(from) ∧Airport(to)
EFFECT: ¬ At(p,from) ∧ At(p,to))
[Load(C1,P1,SFO), Fly(P1,SFO,JFK), Load(C2,P2,JFK), Fly(P2,JFK,SFO)]
290](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-290-320.jpg)















































![Probability
● Given a set U (universe), a probability function is a function
defined over the subsets of U that maps each subset to the real
numbers and that satisfies the Axioms of Probability
● Pr(U) = 1
● Pr(A) ∈ [0,1]
● Pr(A ∪ B) = Pr(A) + Pr(B) – Pr(A ∩ B)
» P(A) = P(A ∩ B) + P(A ∩ ~B)](https://image.slidesharecdn.com/introia-230531095051-99a666ed/85/Intro-IA-pdf-338-320.jpg)

























































































































