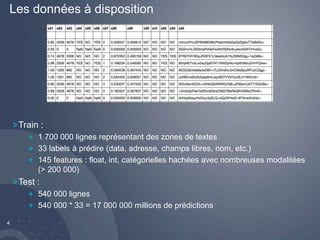
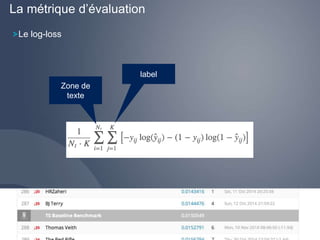
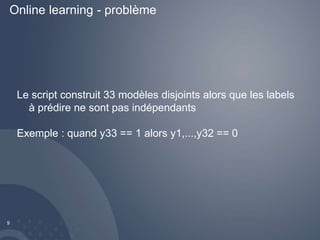
Téléchargé 11 fois






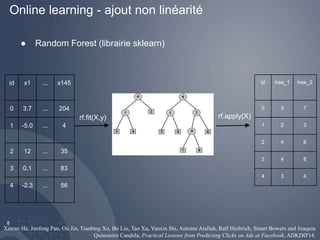

![Un peu différent de sklearn
12
[Label] [Importance [Tag]]|Namespace Features |Namespace
Features ... |Namespace Features
rf.fit(X_train, y_train)
Focus sur une dizaine de labels seulement](https://image.slidesharecdn.com/parismlmeetup-rextradeshift-141125043434-conversion-gate01/85/Kaggle-Tradeshift-Challenge-12-320.jpg)

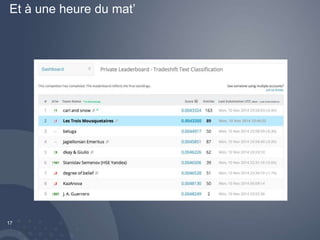
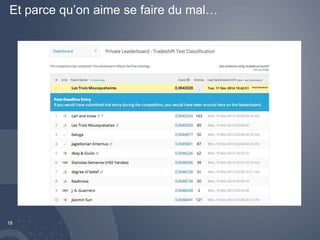


Le document traite du challenge Tradeshift à Paris, où les participants doivent prédire 33 labels à partir de 1,7 million de lignes de données textuelles. Il présente les techniques de modélisation utilisées, notamment l'apprentissage en ligne et l'apprentissage en deux étapes, avec des références à des outils comme Vowpal Wabbit et Random Forest. Enfin, il mentionne les résultats obtenus et des observations sur la performance des modèles.



























