Télécharger pour lire hors ligne





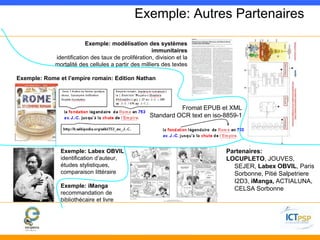



![Application [DÉMO]: Fleuve d’entités nommées
pendant la première guerre mondiale](https://image.slidesharecdn.com/yd4wtcmrtd6jskojgau8-signature-b6f6a5acdb1c911e98b14c1474bf2d399c253eb2ca38031654e435a325a5d551-poli-141215062058-conversion-gate02/85/Presentation-of-Alaa-Abi-Haidar-at-the-BnF-Information-Day-11-320.jpg)
![Application [DÉMO]:
Soulignement automatique d’entités nommées](https://image.slidesharecdn.com/yd4wtcmrtd6jskojgau8-signature-b6f6a5acdb1c911e98b14c1474bf2d399c253eb2ca38031654e435a325a5d551-poli-141215062058-conversion-gate02/85/Presentation-of-Alaa-Abi-Haidar-at-the-BnF-Information-Day-12-320.jpg)
![Outil d’annotation [DÉMO]:](https://image.slidesharecdn.com/yd4wtcmrtd6jskojgau8-signature-b6f6a5acdb1c911e98b14c1474bf2d399c253eb2ca38031654e435a325a5d551-poli-141215062058-conversion-gate02/85/Presentation-of-Alaa-Abi-Haidar-at-the-BnF-Information-Day-13-320.jpg)
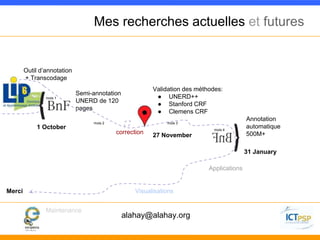
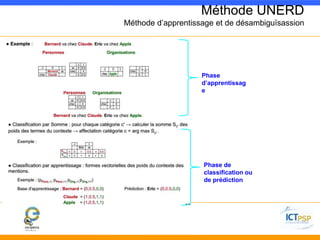
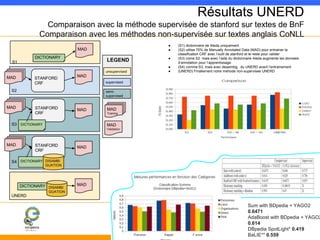
Ce document présente la reconnaissance d'entités nommées (NER) et son application sur les données de la BNF, en mettant en avant des exemples et des partenaires. Il aborde des méthodes comme UNERD pour la désambiguïsation contextuelle, tout en discutant des défis et des solutions à cette problématique. Les applications envisagées incluent des outils d'annotation et la visualisation des données à des fins d'analyse et de recherche.










































