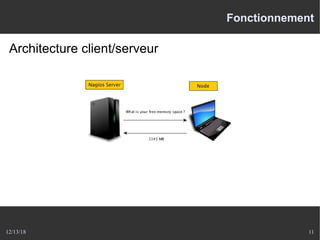
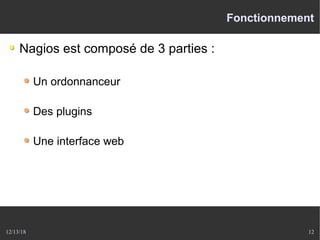
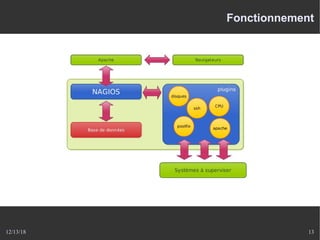
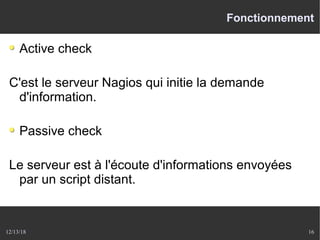
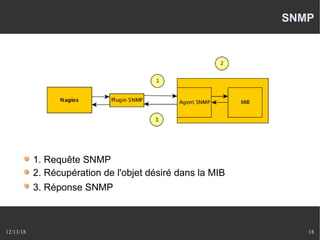
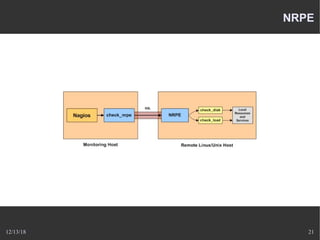
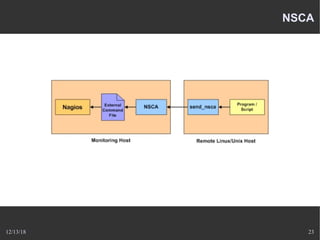
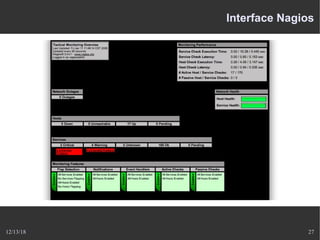
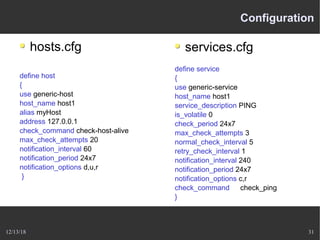
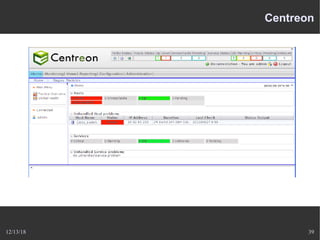
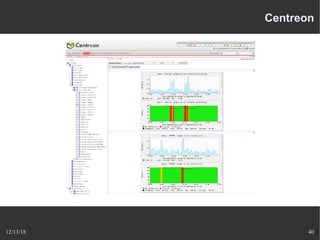
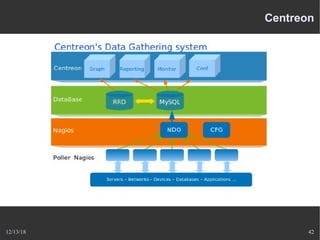
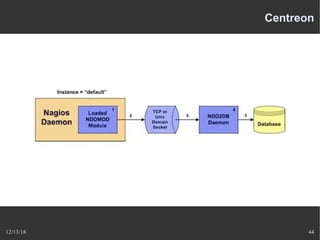
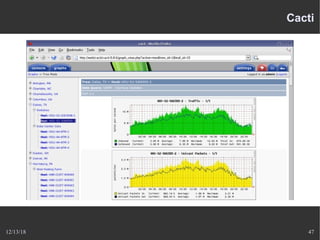
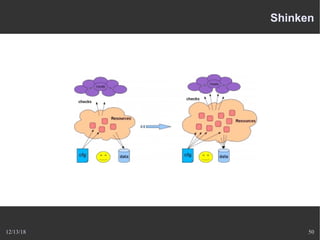
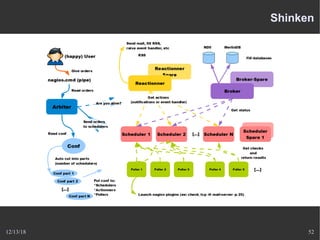
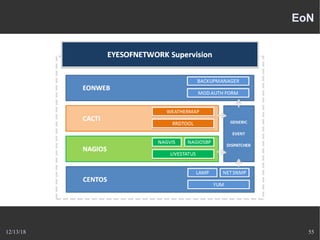
Le document présente Nagios, un système de supervision permettant de surveiller le fonctionnement des systèmes informatiques à travers des plugins et une interface web. Il décrit le fonctionnement de Nagios, y compris les méthodes de vérification, ainsi que des outils complémentaires comme Centreon, Cacti, Shinken, et Eon pour étendre ses capacités. Des aspects de configuration, de notifications et l'architecture client/serveur sont également abordés.









































![[SINS] Présentation de Nagios](https://cdn.slidesharecdn.com/ss_thumbnails/sins-pres-nagios-110411032549-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
































