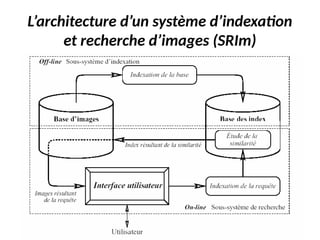
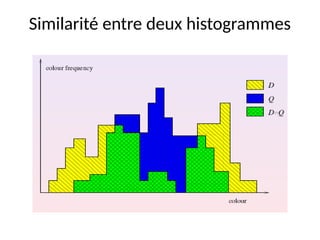
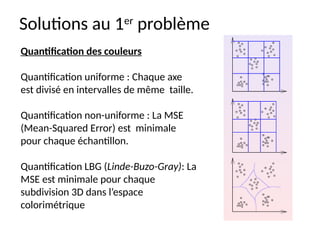
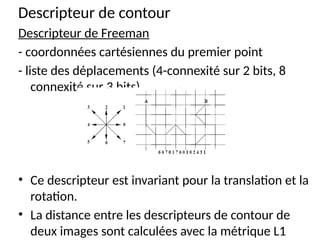
Le chapitre présente plusieurs approches pour la recherche et l'indexation d'images, allant des attributs de base aux techniques avancées utilisant la reconnaissance d'images et l'annotation manuelle. Il explore des descripteurs tels que les histogrammes de couleur, les descripteurs de forme et de texture, en abordant leurs avantages et limitations ainsi que des solutions aux problèmes rencontrés dans l'indexation. Finalement, il souligne l'importance de rendre ces techniques applicables aux images comprimées pour une meilleure efficacité de recherche.



















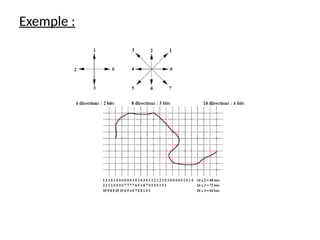
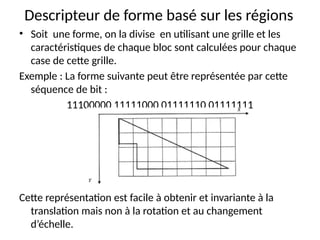

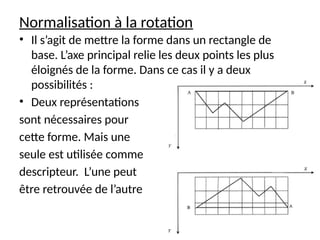






































![cours raspberry [Enregistrement automatique].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/coursraspberryenregistrementautomatique-260206145736-b1015531-thumbnail.jpg?width=640&height=640&fit=bounds)




