Téléchargé 77 fois























![28Copyright © 2017 Capgemini. Tous droits réservés
CSD | Octobre 2017
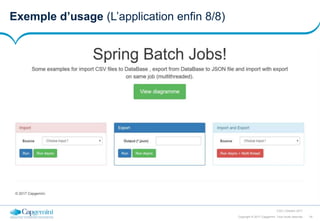
La démo (Le configuration de la solution 3/6)
<batch:job id="transformJob">
<batch:step id="deleteDir" next="cleanDB">
<batch:tasklet ref="fileDeletingTasklet" />
</batch:step>
<batch:step id="cleanDB" next="countThread">
<batch:tasklet ref="cleanDBTasklet" />
</batch:step>
<batch:step id="countThread" next="split">
<batch:tasklet ref="countThreadTasklet" />
</batch:step>
<batch:step id="split" next="partitionerMasterImporter">
<batch:tasklet>
<batch:chunk reader="largeCSVReader" writer="smallCSVWriter"
commit-interval="#{jobExecutionContext['chunk.count']}" />
</batch:tasklet>
</batch:step>
<batch:step id="partitionerMasterImporter" next="partitionerMasterExporter">
<partition step="importChunked" partitioner="filePartitioner">
<handler grid-size="10" task-executor="taskExecutor" />
</partition>
</batch:step>
<batch:step id="partitionerMasterExporter" next="concat">
<partition step="exportChunked" partitioner="dbPartitioner">
<handler grid-size="10" task-executor="taskExecutor" />
</partition>
</batch:step>
<batch:step id="concat">
<batch:tasklet ref="concatFileTasklet" />
</batch:step>
</batch:job>](https://image.slidesharecdn.com/presspringbatch-171003154506/85/Spring-SpringBatch-FR-28-320.jpg)
![29Copyright © 2017 Capgemini. Tous droits réservés
CSD | Octobre 2017
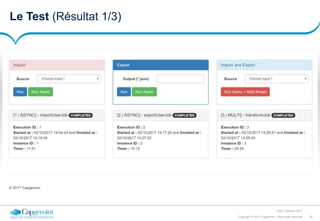
La démo (Le configuration 4/6)
<batch:step id="importChunked">
<batch:tasklet>
<batch:chunk reader="smallCSVFileReader" writer="dbWriter"
processor="importProcessor" commit-interval="500">
</batch:chunk>
</batch:tasklet>
</batch:step>
<batch:step id="exportChunked">
<batch:tasklet>
<batch:chunk reader="dbReader" writer="jsonFileWriter" processor="exportProcessor" commit-
interval="#{jobExecutionContext['chunk.count']}">
</batch:chunk>
</batch:tasklet>
</batch:step>
<bean id="jsonFileWriter" class="com.capgemini.writer.PersonWriterToFile" scope="step">
<property name="outputPath" value="csv/chunked/paged-#{stepExecutionContext[page]}.json" />
</bean>
<bean id="dbReader" class="com.capgemini.reader.PersonReaderFromDataBase" scope="step">
<property name="iPersonRepository" ref="IPersonRepository" />
<property name="page" value="#{stepExecutionContext[page]}"/>
<property name="size" value="#{stepExecutionContext[size]}"/>
</bean>
<bean id="countThreadTasklet" class="com.capgemini.tasklet.CountingTasklet" scope="step">
<property name="input" value="file:csv/input/#{jobParameters[filename]}" />
</bean>
<bean id="cleanDBTasklet" class="com.capgemini.tasklet.CleanDBTasklet" />
<bean id="fileDeletingTasklet" class="com.capgemini.tasklet.FileDeletingTasklet">
<property name="directory" value="file:csv/chunked/" />
</bean>](https://image.slidesharecdn.com/presspringbatch-171003154506/85/Spring-SpringBatch-FR-29-320.jpg)
![30Copyright © 2017 Capgemini. Tous droits réservés
CSD | Octobre 2017
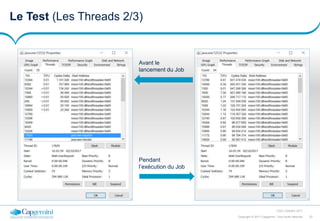
La démo (Le configuration 5/6)
<bean id="concatFileTasklet" class="com.capgemini.tasklet.FileConcatTasklet">
<property name="directory" value="file:csv/chunked/" />
<property name="outputFilename" value="csv/output/export.json" />
</bean>
<bean id="filePartitioner" class="com.capgemini.partitioner.FilePartitioner">
<property name="outputPath" value="csv/chunked/" />
</bean>
<bean id="dbPartitioner" class="com.capgemini.partitioner.DBPartitioner" scope="step">
<property name="pageSize" value="#{jobExecutionContext['chunk.count']}" />
</bean>
<bean id="largeCSVReader" class="com.capgemini.reader.LineReaderFromFile" scope="step">
<property name="inputPath" value="csv/input/#{jobParameters[filename]}" />
</bean>
<bean id="smallCSVWriter" class="com.capgemini.writer.LineWriterToFile" scope="step">
<property name="outputPath" value="csv/chunked/"></property>
</bean>
<bean id="smallCSVFileReader" class="com.capgemini.reader.PersonReaderFromFile" scope="step">
<constructor-arg value="csv/chunked/#{stepExecutionContext[file]}" />
</bean>
<bean id="importProcessor" class="com.capgemini.processor.ImportPersonItemProcessor" />
<bean id="exportProcessor" class="com.capgemini.processor.ExportPersonItemProcessor" />
<bean id="dbWriter" class="com.capgemini.writer.PersonWriterToDataBase">
<property name="iPersonRepository" ref="IPersonRepository" />
</bean>](https://image.slidesharecdn.com/presspringbatch-171003154506/85/Spring-SpringBatch-FR-30-320.jpg)









Le document présente une introduction au framework Spring et à Spring Batch, en détaillant leur utilisation pour le traitement par lots de données. Il explique le fonctionnement de Spring Batch, ses concepts, et fournit des exemples concrets d'application avec des illustrations de code. Les objectifs incluent l'assimilation de Spring Batch et l'élaboration d'applications robustes pour le traitement de gros volumes de données.

















































![cours raspberry [Enregistrement automatique].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/coursraspberryenregistrementautomatique-260206145736-b1015531-thumbnail.jpg?width=640&height=640&fit=bounds)




