reliablity and validity in social sciences research
•
2 j'aime•530 vues

Reliability and validity in educational research, internal and external validity , threats to validity and reliability.

Recommandé
Contenu connexe
Tendances
Tendances (20)
Similaire à reliablity and validity in social sciences research
Similaire à reliablity and validity in social sciences research (20)
Dernier
Dernier (20)
reliablity and validity in social sciences research
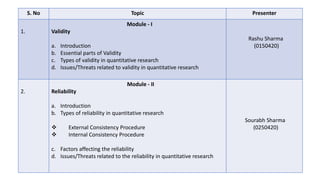
- 1. S. No Topic Presenter 1. Module - I Validity a. Introduction b. Essential parts of Validity c. Types of validity in quantitative research d. Issues/Threats related to validity in quantitative research Rashu Sharma (0150420) 2. Module - II Reliability a. Introduction b. Types of reliability in quantitative research ❖ External Consistency Procedure ❖ Internal Consistency Procedure c. Factors affecting the reliability d. Issues/Threats related to the reliability in quantitative research Sourabh Sharma (0250420)
- 2. Module - I Validity a. Introduction b. Essential parts of Validity c. Types of validity in quantitative research d. Issues/Threats related to validity in quantitative research
- 3. Validity: (Introduction) • A measure of the truthfulness of a measuring instrument. It indicates whether the instrument measures what it claims to measure. • refers to the degree to which the results are truthful or genuine. • According to Kerlinger, “ the commonest definition of the validity is epitomized by the question: Are we measuring what we think we are measuring? ’’
- 4. Validity (Essential parts of validity) • In research, validity has two essential parts: • a) internal (credibility), and • b) external (transferability). • Internal validity indicates whether the results of the study are legitimate because of the way the groups were selected, data were recorded or analyses were performed. It refers to whether a study can be replicated [Willis, 2007]. • To assure it, the researcher can describe appropriate strategies, such as triangulation, prolonged contact, member checks, saturation, reflexivity, and peer review.
- 5. Validity (Essential parts of validity) • External validity shows whether the results given by the study are transferable to other groups of interest [Last, 2001] • A researcher can increase external validity by: • i) achieving representation of the population through strategies, such as, random selection, • ii) using heterogeneous groups, • iii) using non-reactive measures, and • iv) using precise description to allow for study replication or replicate study across different populations, settings, etc.
- 6. Validity (Types of validity in quantitative research) • Face Validity • Content validity; • Criterion Validity • Concurrent and predictive validity; • Construct validity.
- 7. Validity (Face validity) • The extent to which a measuring instrument appears valid on its surface. • The judgement that an instrument is measuring what it is supposed to is primarily based upon the logical link between the questions and the objectives of the study. • Each question or item on the research instrument must have a logical link with an objective. • Establishment of this link is called face validity. • Hence, one of the main advantages of this type of validity is that it is easy to apply. • For example, does the test selected by the school board to measure student achievement “appear” to be an actual measure of achievement?
- 8. Validity (Content validity) • The extent to which a measuring instrument covers a representative sample of the domain of behaviors to be measured. • A systematic examination of the test content to determine whether it covers a representative sample of the domain of behaviors to be measured assesses content validity. • In other words, a test with content validity has items that satisfactorily assess the content being examined. • To determine whether a test has content validity, you should consult experts in the area being tested.
- 9. Validity (Criterion Validity) • The extent to which a measuring instrument accurately predicts behavior or ability in a given area establishes criterion validity. • Two types of criterion validity may be used, • depending on whether the test is used to estimate present performance (concurrent validity) or • to predict future performance (predictive validity). • The SAT and GRE are examples of tests that have predictive validity because performance on the tests correlates with later performance in college and graduate school, respectively. • The tests can be used with some degree of accuracy to “predict” future behavior. • A test used to determine whether or not someone qualifies as a pilot is a measure of concurrent validity. • We are estimating the person’s ability at the present time, not attempting to predict future outcomes. Thus, concurrent validation is used for diagnosis of existing status rather than prediction of future outcomes.
- 10. Validity (Construct Validity) • Construct validity is considered by many to be the most important type of validity. • The construct validity of a test assesses the extent to which a measuring instrument accurately measures a theoretical construct or trait that it is designed to measure. • Some examples of theoretical constructs or traits are verbal fluency, neuroticism, depression, anxiety, intelligence, and scholastic aptitude. • One means of establishing construct validity is by correlating performance on the test with performance on a test for which construct validity has already been determined.
- 11. Review
- 12. Validity (Threats/ issues to internal validity in quantitative research)
- 13. Validity (Threats/ issues to external validity in quantitative research)
- 14. Module - II Reliability a. Introduction b. Types of reliability in quantitative research ❖ External Consistency Procedure ❖ Internal Consistency Procedure c. Factors affecting the reliability d. Issues/Threats related to the reliability in quantitative research
- 15. Reliability (Introduction) • Reliability refers to the consistency or stability of a measuring instrument. In other words, we want a measure to measure exactly the same way each time it is used. This means that individuals should receive a similar score each time they use the measuring instrument.
- 16. Reliability (Types) • Test/Retest Reliability, • Alternate-forms Reliability, • Split-half Reliability, and • Interrater Reliability.
- 17. Reliability External consistency procedures Test/ Retest Alternate forms Internal consistency Procedures Split half technique Reliability (External & Internal consistency procedures)
- 18. Reliability (Test-Retest) • Test/retest reliability: A reliability coefficient determined by assessing the degree of relationship between scores on the same test administered on two different occasions. • One of the most often used and obvious ways of establishing reliability is to repeat the same test on a second occasion-test/retest reliability. • The obtained correlation coefficient is between the two scores of each individual on the same test administered on two different occasions. If the test is reliable, we expect the two scores for each individual to be similar, and thus the resulting correlation coefficient will be high (close to 1.00). • This measure of reliability assesses the stability of a test over time.
- 19. • Naturally, some error will be present in each measurement (for example, an individual may not feel well at one testing or may have problems during the testing session such as a broken pencil). Thus, it is unusual for the correlation coefficient to be 1.00, but we expect it to be .80 or higher. • Issues: • A problem related to test/retest measures is that on many tests, there will be practice effects—some people will get better at the second testing, which lowers the observed correlation. • A second problem may occur if the interval between test times is short: Individuals may remember how they answered previously, both correctly and incorrectly. • Absence: People remaining absent for re-tests Reliability (Test-Retest)
- 20. Reliability (Alternate forms) • Alternate-Forms Reliability. One means of controlling for test/retest problems is to use alternate-forms reliability—using alternate forms of the testing instrument and correlating the performance of individuals on the two different forms. • In this case, the tests taken at times 1 and 2 are different but equivalent or parallel (hence, the terms equivalent-forms reliability and parallel-forms reliability are also used). Alternate forms reliability establishes the stability of the test over time and also the equivalency of the items from one test to another. • ISSUES:- • One problem with alternate-forms reliability is making sure that the tests are truly parallel. To help ensure equivalency, the tests should have the same number of items, the items should be of the same difficulty level, and instructions, time limits, examples, and format should all be equal—often difficult if not impossible to accomplish. • Second, if the tests are truly equivalent, there is the potential for practice effects, although not to the same extent as when exactly the same test is administered twice.
- 21. • Split-Half Reliability. A third means of establishing reliability is by splitting the items on the test into equivalent halves and correlating scores on one half of the items with scores on the other half. • This split-half reliability gives a measure of the equivalence of the content of the test but not of its stability over time as test/retest and alternate-forms reliability do. • ISSUES • The biggest problem with split-half reliability is determining how to divide the items so that the two halves are, in fact, equivalent. • For example, it would not be advisable to correlate scores on multiple-choice questions with scores on short-answer or essay questions. What is typically recommended is to correlate scores on even- numbered items with scores on odd-numbered items. Thus, if the items at the beginning of the test are easier or harder than those at the end of the test, the half scores are still equivalent. Reliability (Split Half )
- 22. • Interrater Reliability. Finally, to measure the reliability of observers rather than tests, you can use interrater reliability. • Interrater reliability is a measure of consistency that assesses the agreement of observations made by two or more raters or judges. • Let’s say that you are observing play behavior in children. Rather than simply making observations on your own, it’s advisable to have several independent observers collect data. The observers all watch the children playing but independently count the number and types of play behaviors they observe. • After the data are collected, interrater reliability needs to be established by examining the percentage of agreement between the raters. If the raters’ data are reliable, then the percentage of agreement should be high. If the raters are not paying close attention to what they are doing, or if the measuring scale devised for the various play behaviors is unclear, the percentage of agreement among observers will not be high. • Thus, if your observers agree 45 times out of a possible 50, the interrater reliability is 90%—fairly high. However, if they agree only 20 times out of 50, then the interrater reliability is low (40%). Reliability (Inter-rater)
- 23. Review
- 24. • The wording of questions – A slight ambiguity in the wording of questions or statements can affect the reliability of a research instrument as respondents may interpret the questions differently at different times, resulting in different responses. • The physical setting – In the case of an instrument being used in an interview, any change in the physical setting at the time of the repeat interview may affect the responses given by a respondent, which may affect reliability. • The respondent’s mood – A change in a respondent’s mood when responding to questions or writing answers in a questionnaire can change and may affect the reliability of that instrument. • The interviewer’s mood – As the mood of a respondent could change from one interview to another so could the mood, motivation and interaction of the interviewer, which could affect the responses given by respondents thereby affecting the reliability of the research instrument. • The nature of interaction – In an interview situation, the interaction between the interviewer and the interviewee can affect responses significantly. During the repeat interview the responses given may be different due to a change in interaction, which could affect reliability. • The regression effect of an instrument – When a research instrument is used to measure attitudes towards an issue, some respondents, after having expressed their opinion, may feel that they have been either too negative or too positive towards the issue. The second time they may express their opinion differently, thereby affecting reliability. Reliability (Factors affecting the reliability of the test)