Téléchargé 69 fois








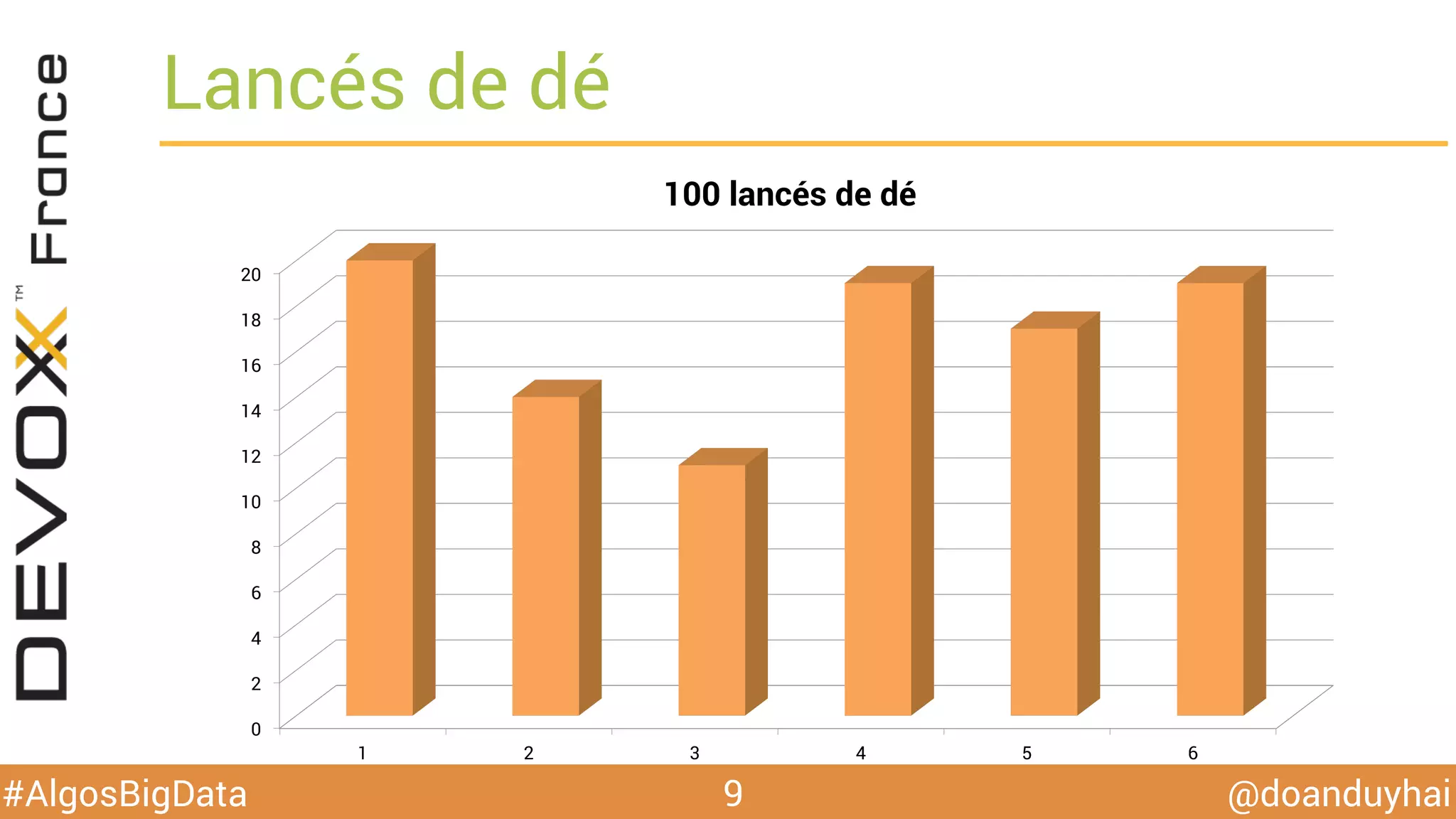
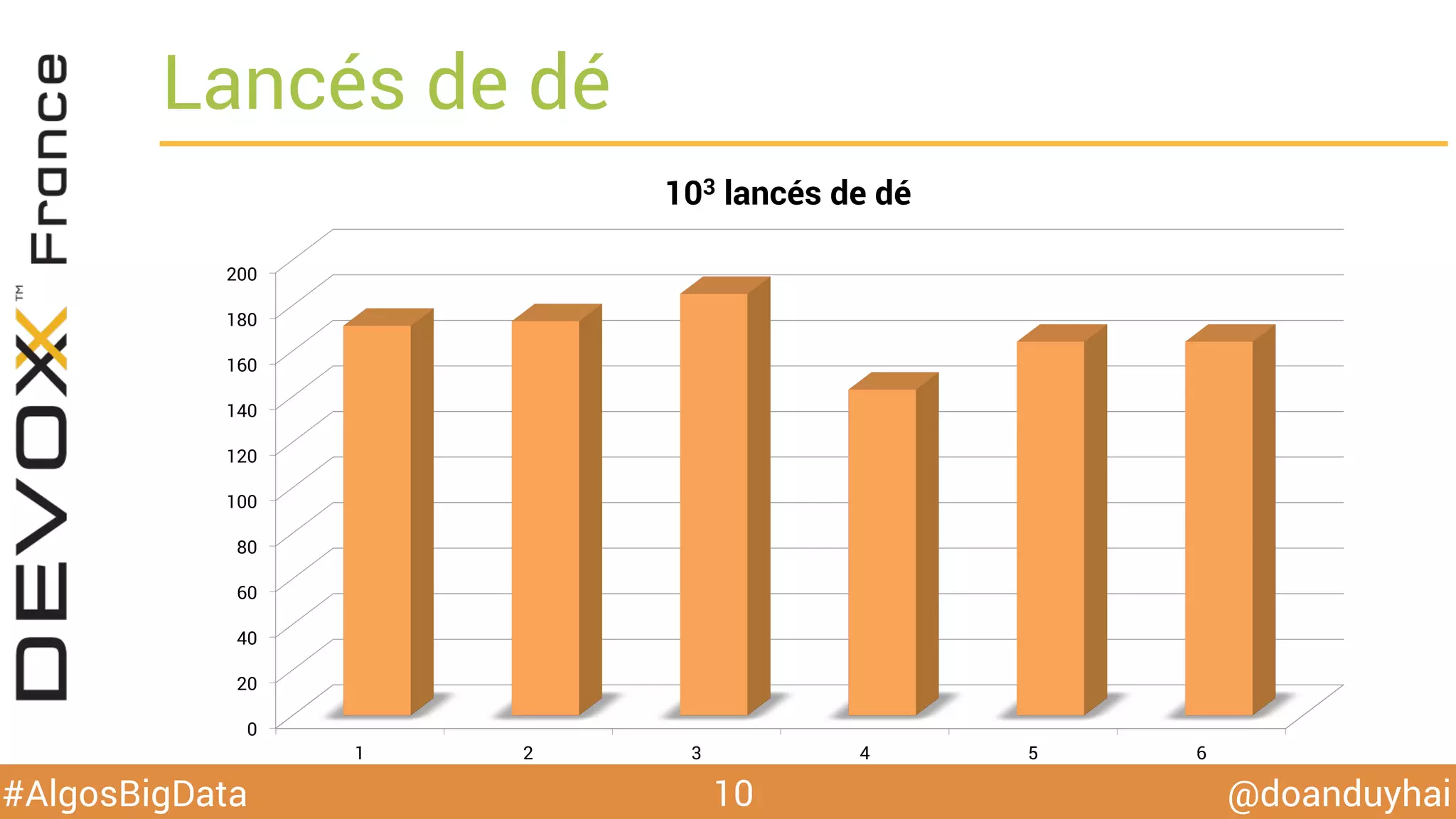
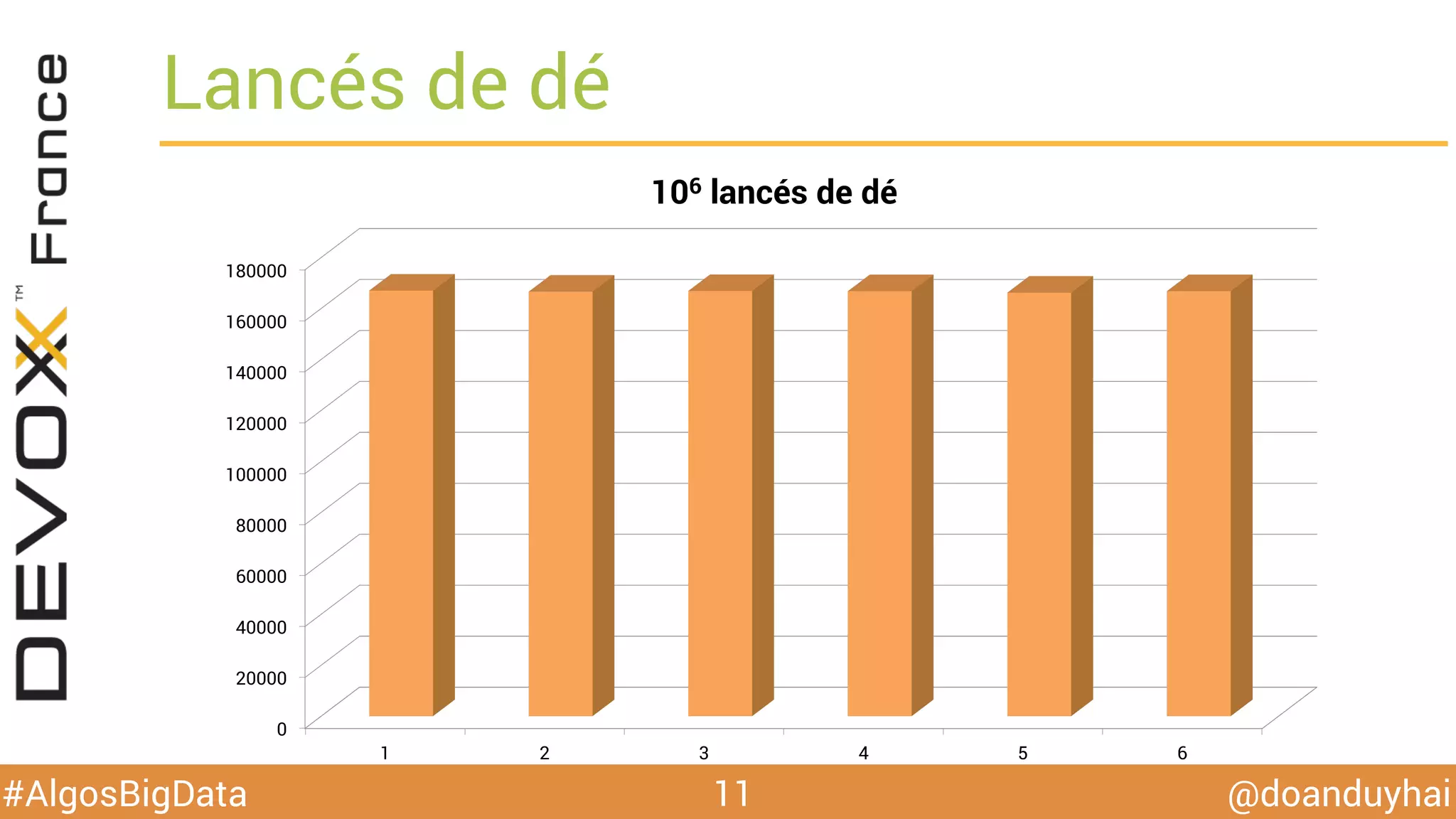













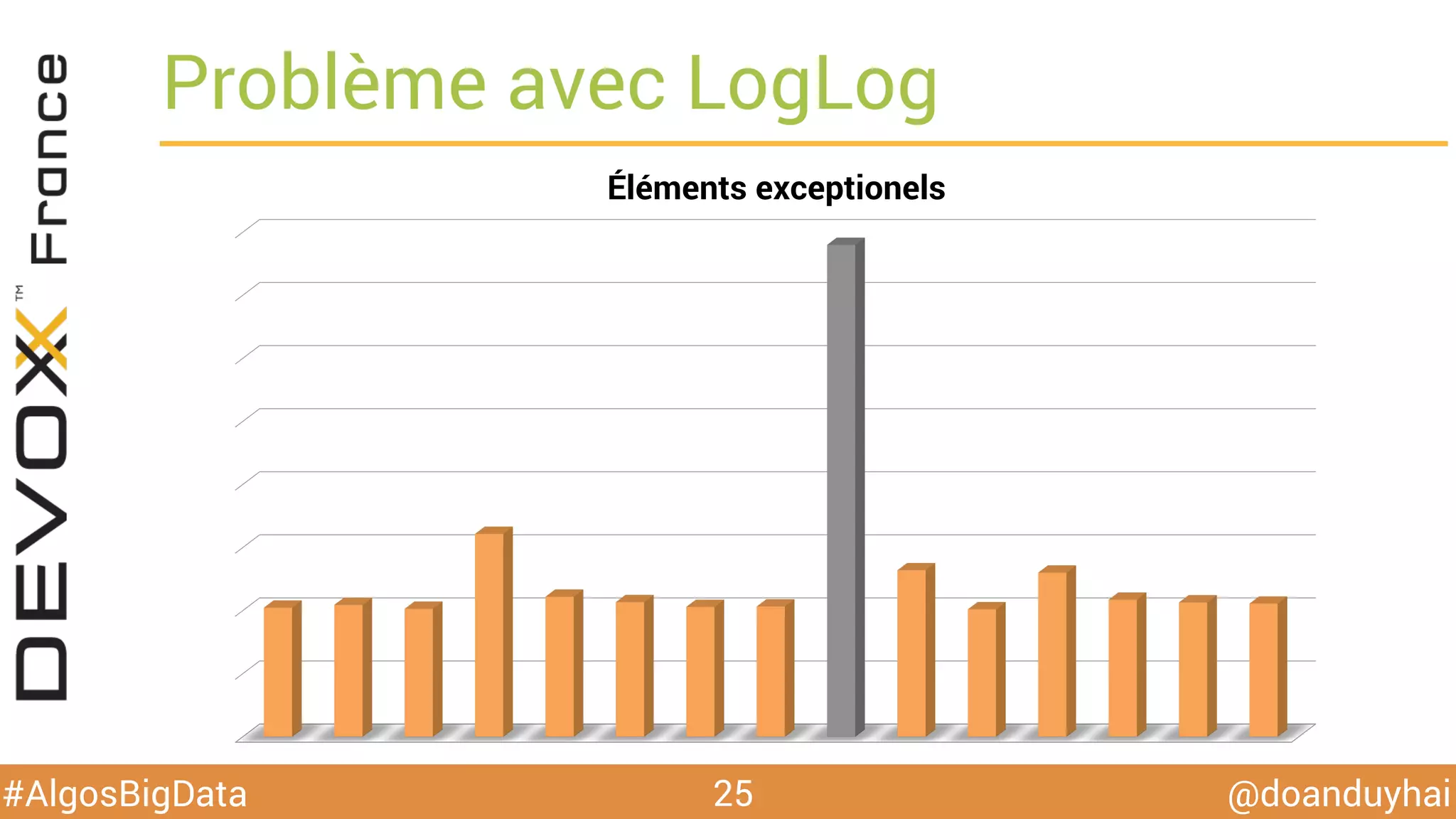



















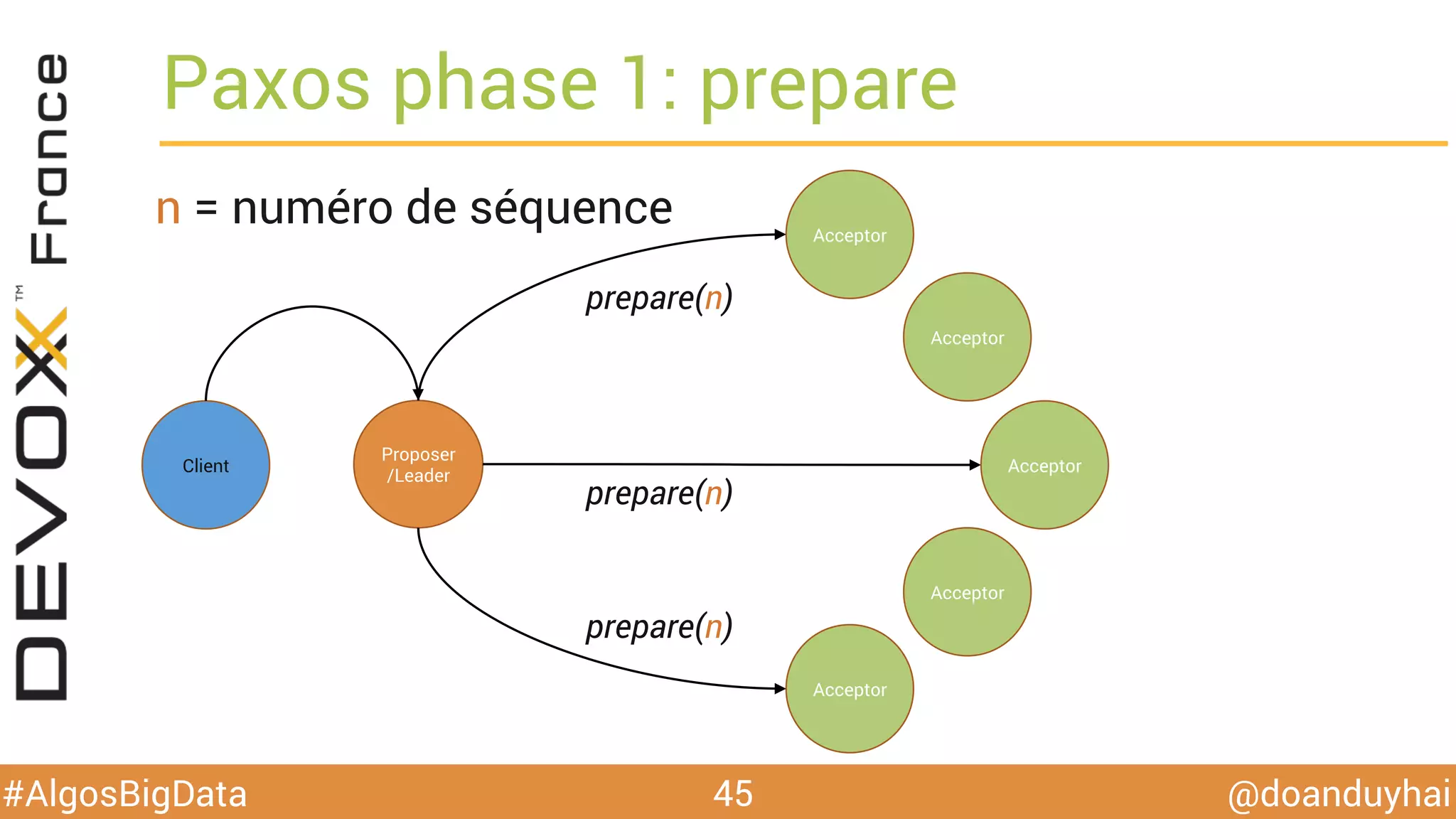
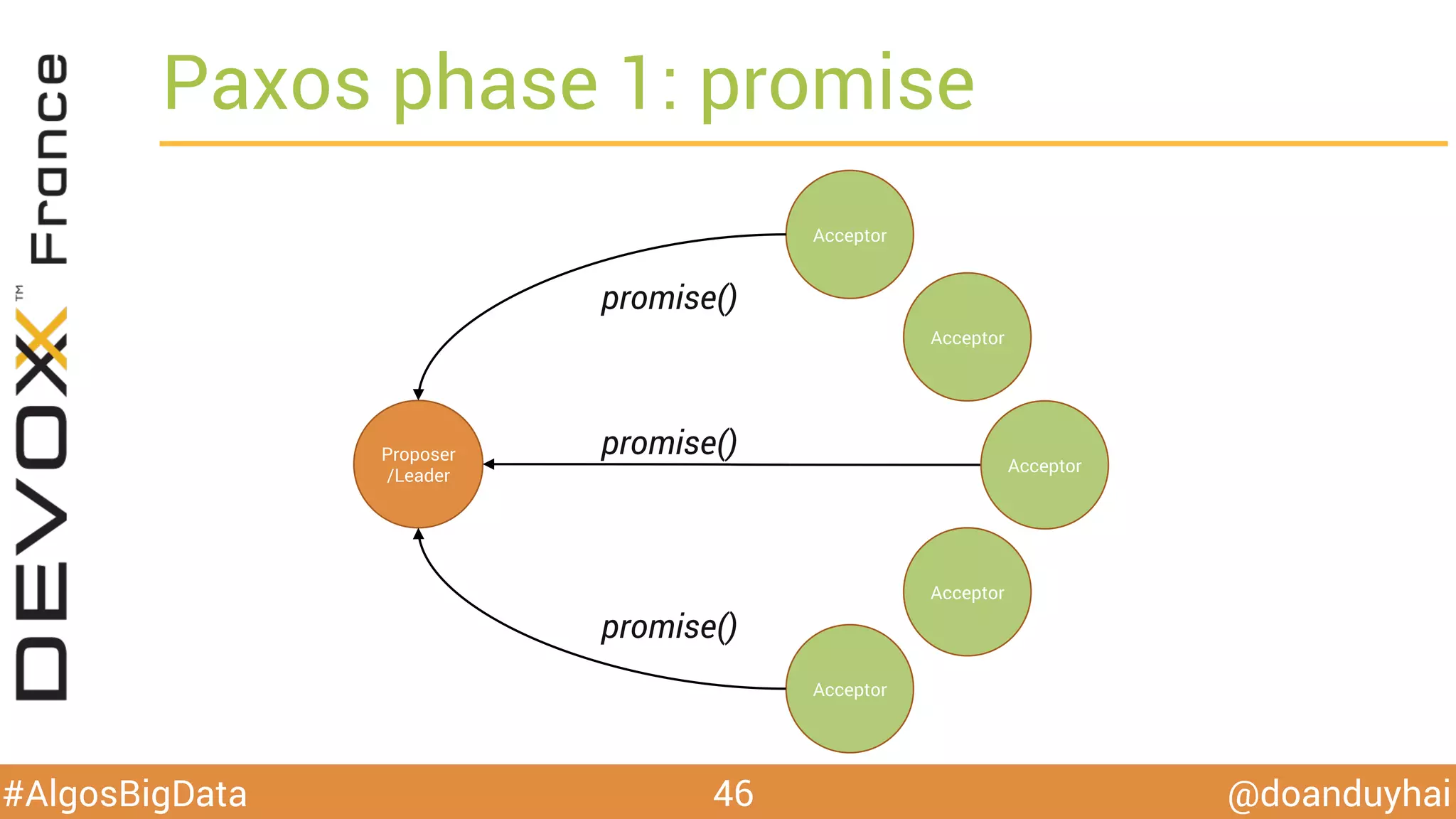
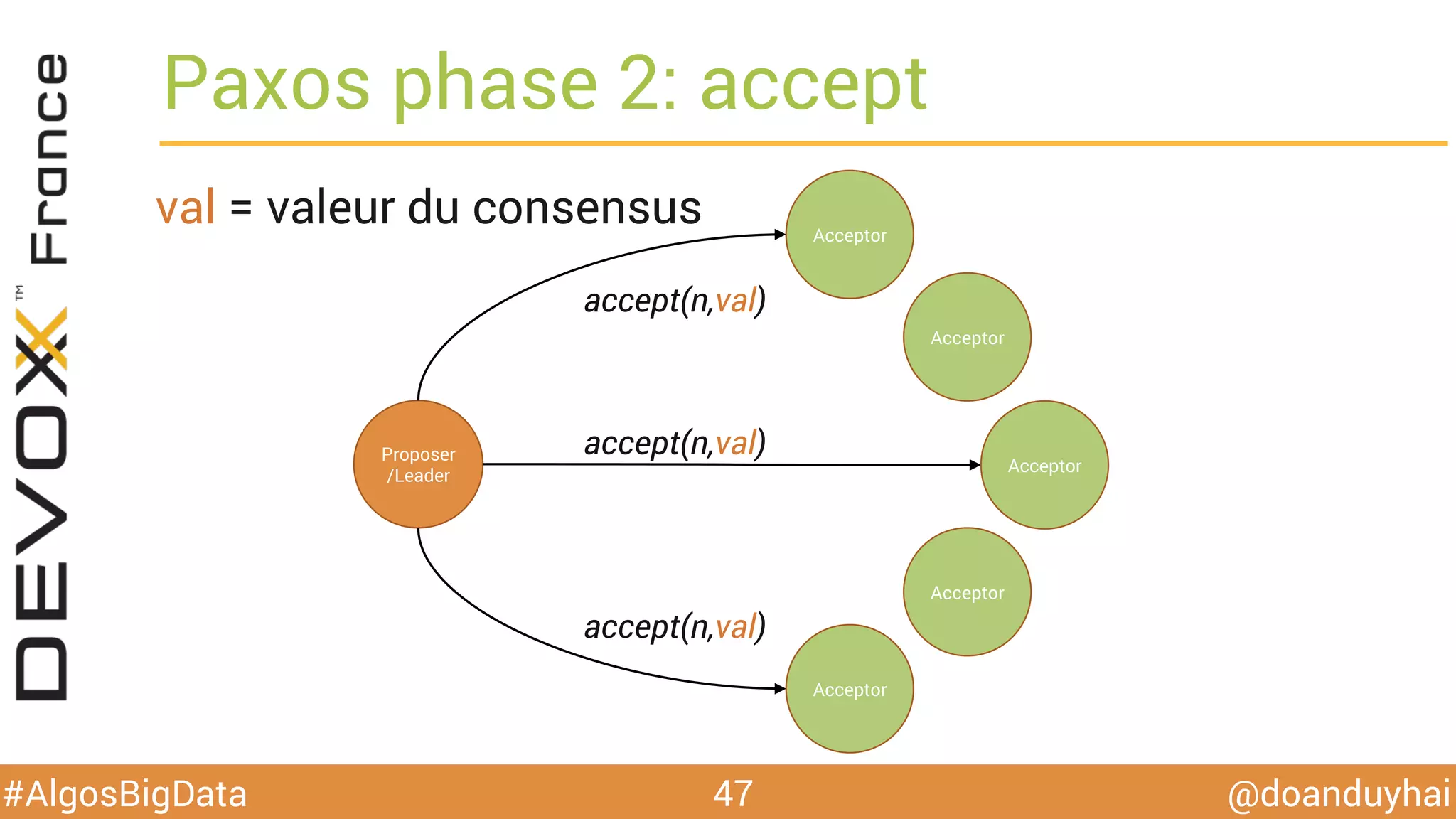
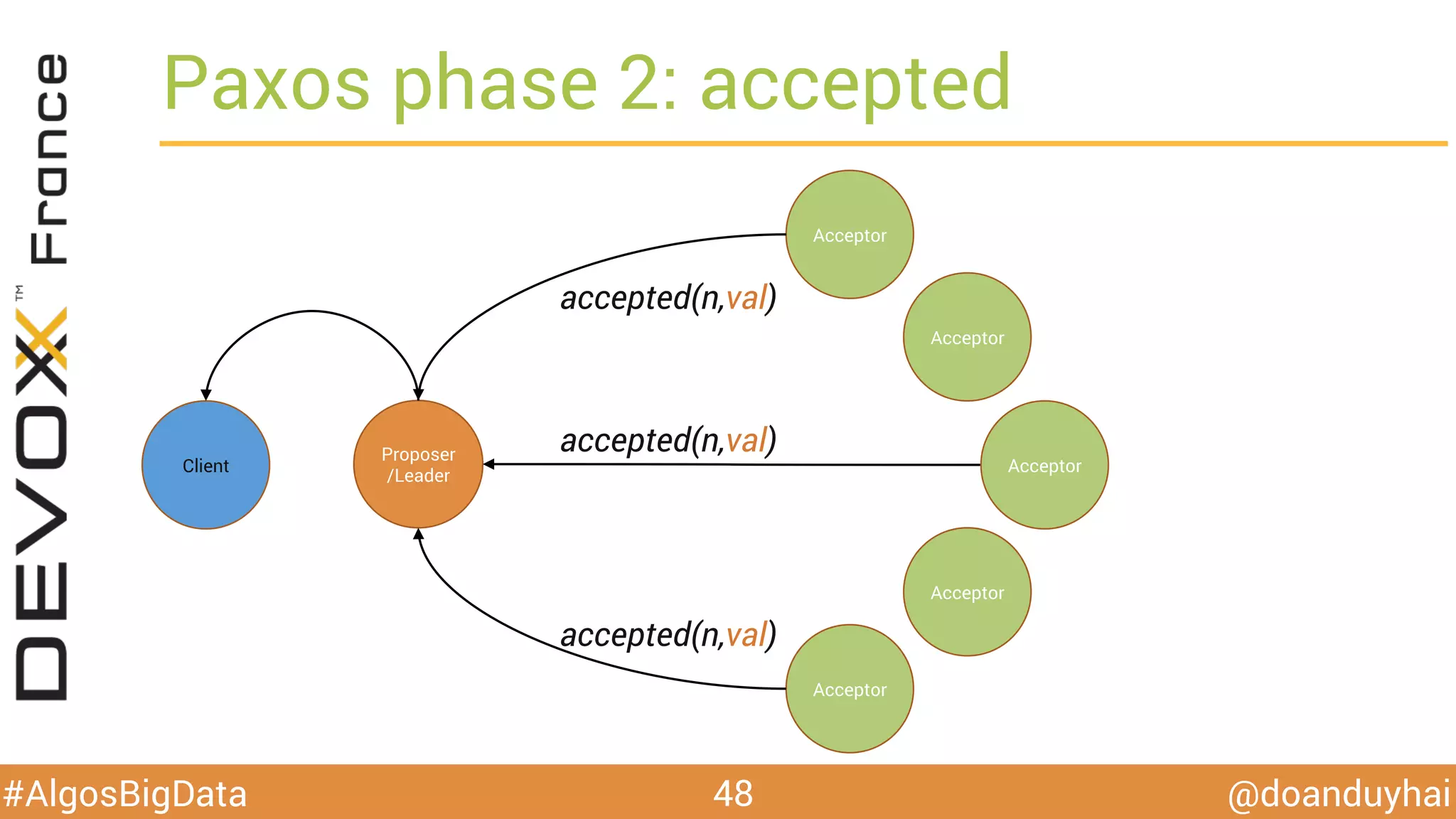
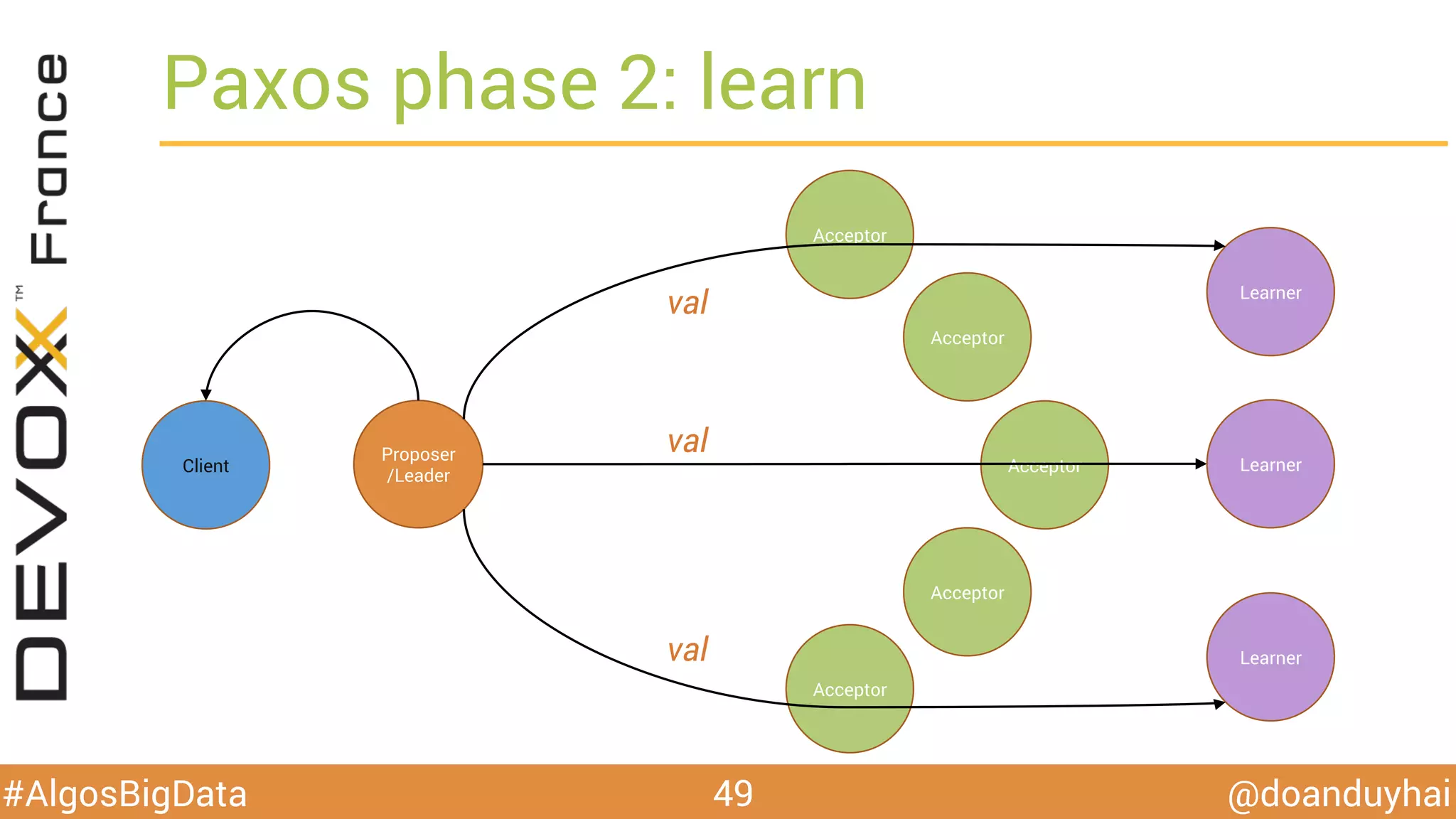
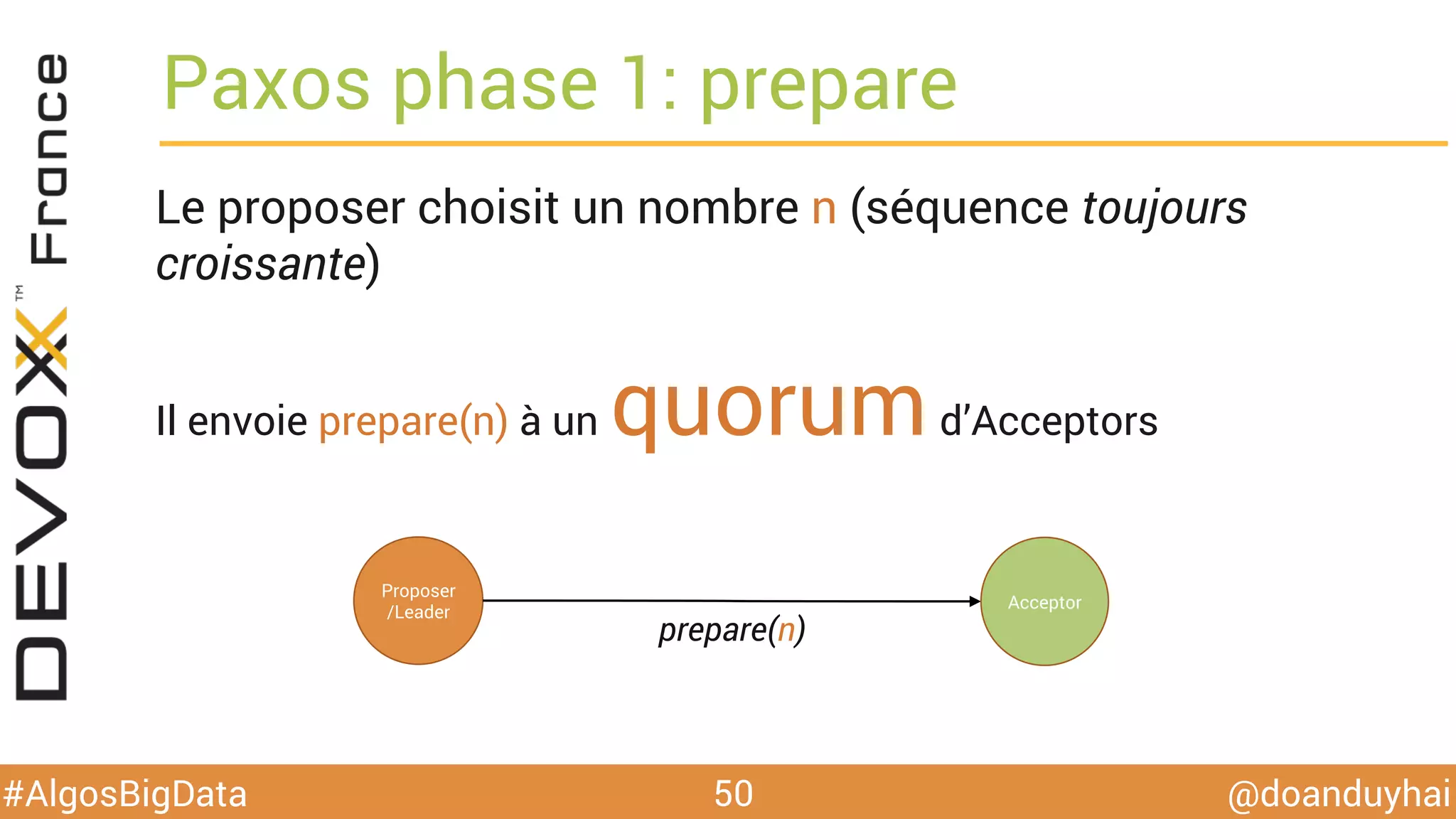
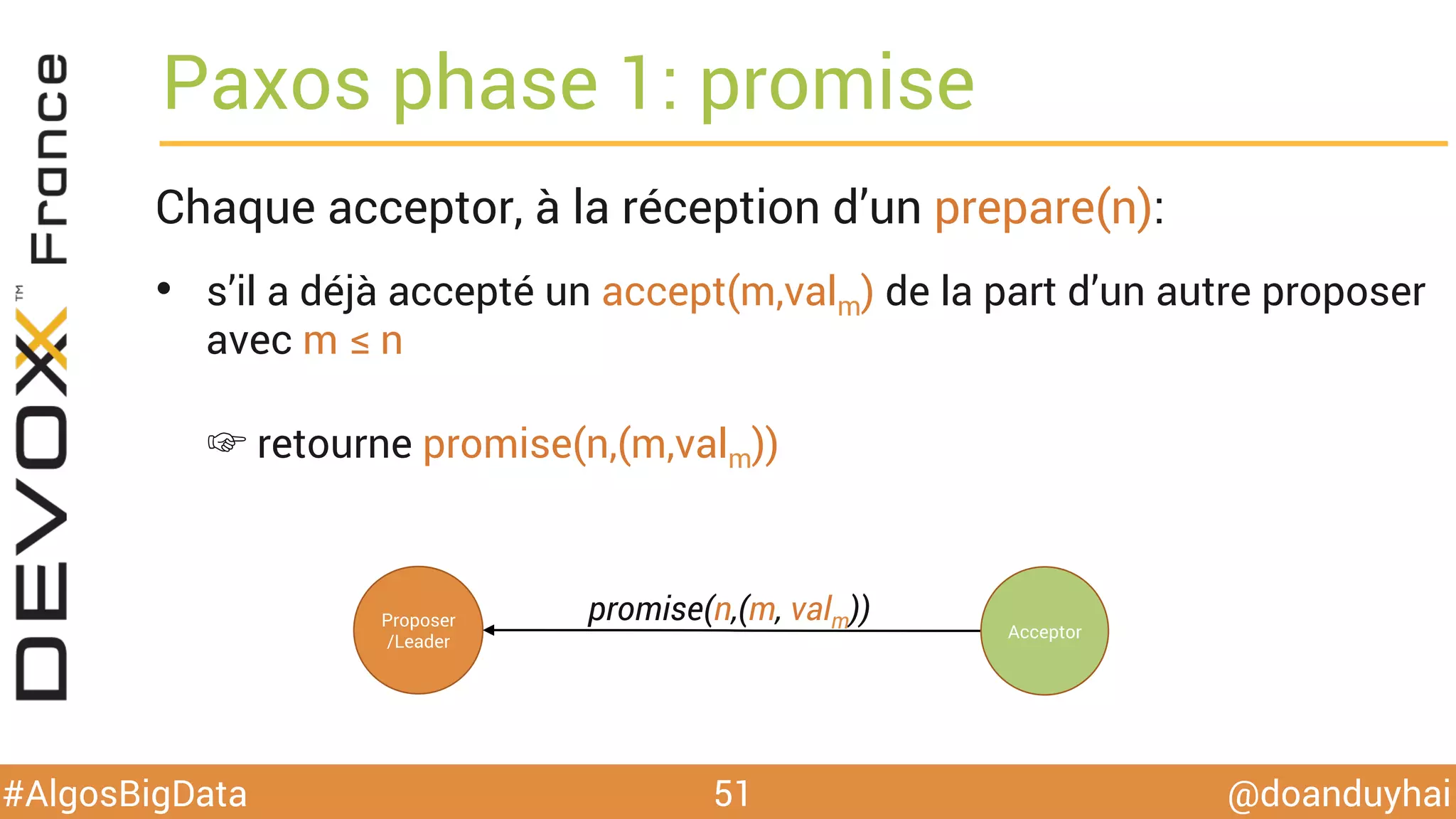
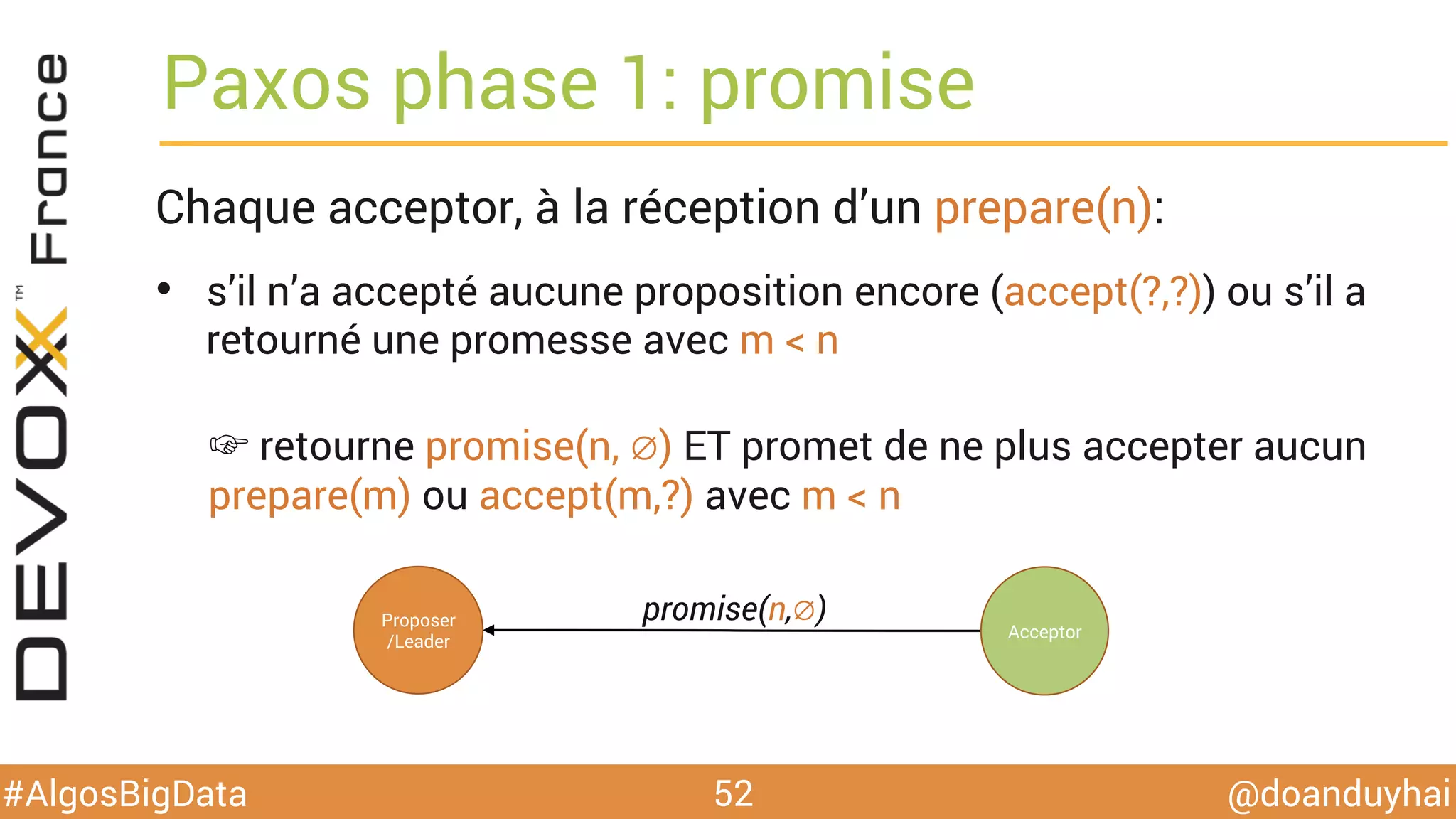
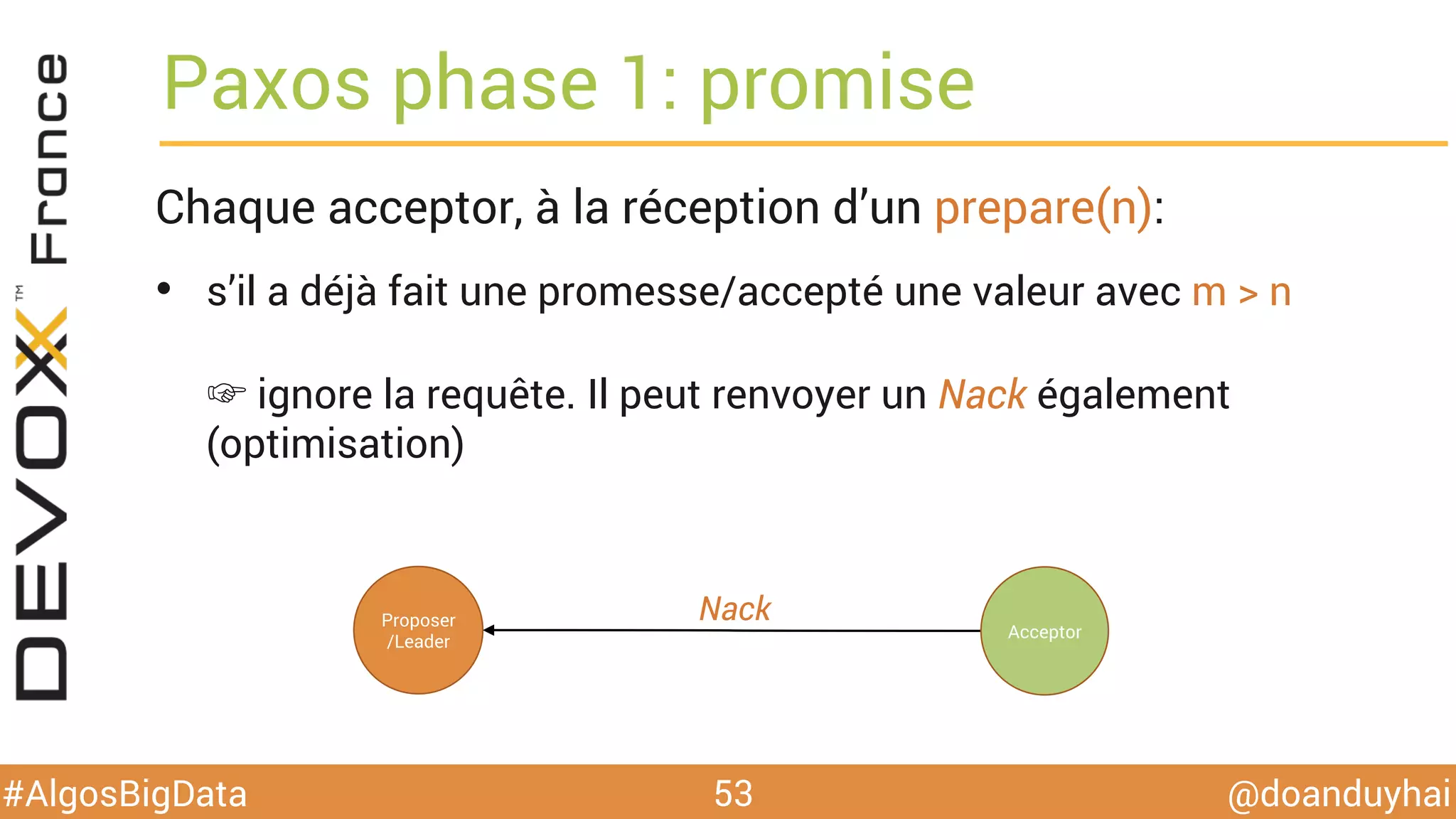

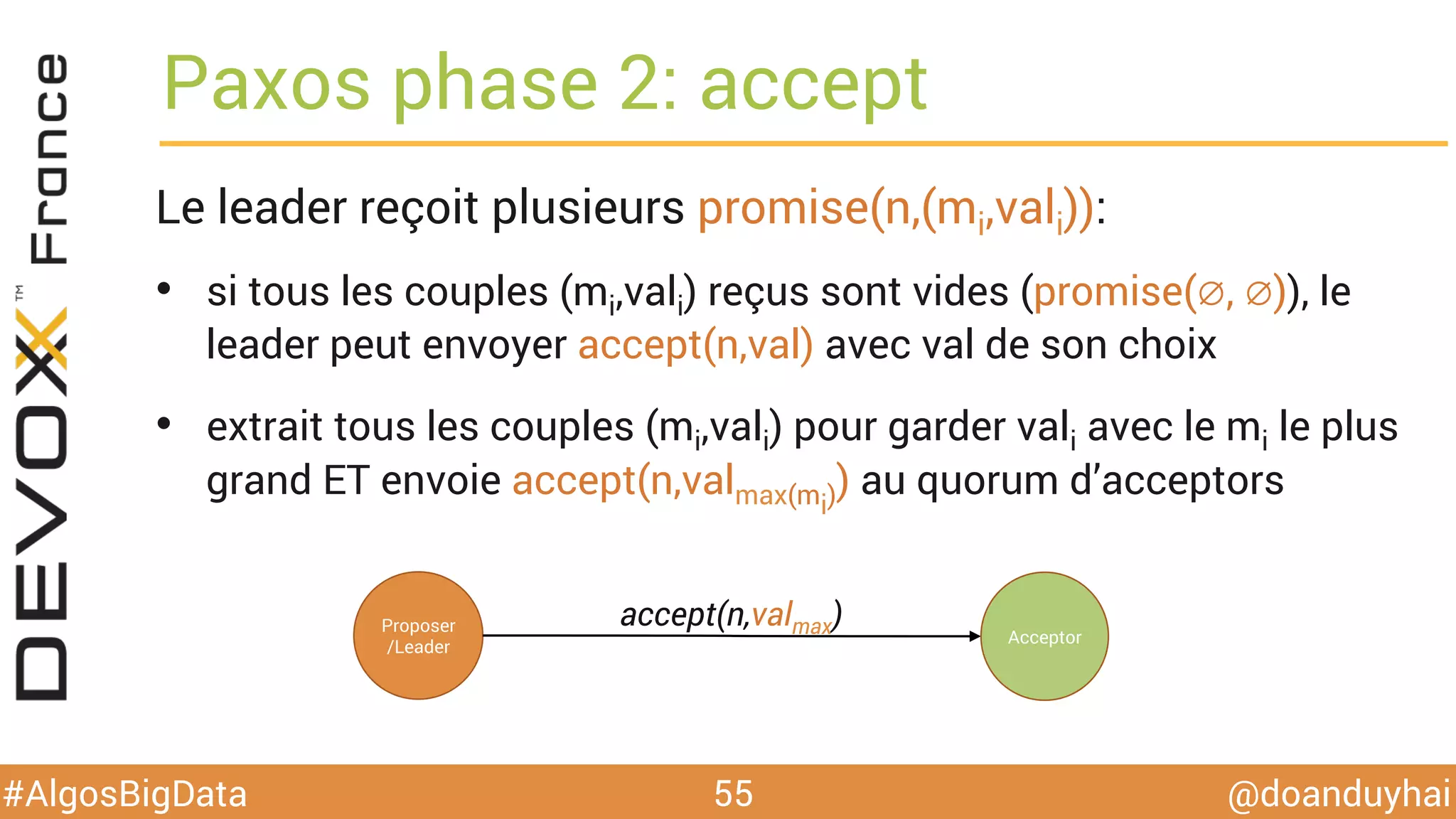
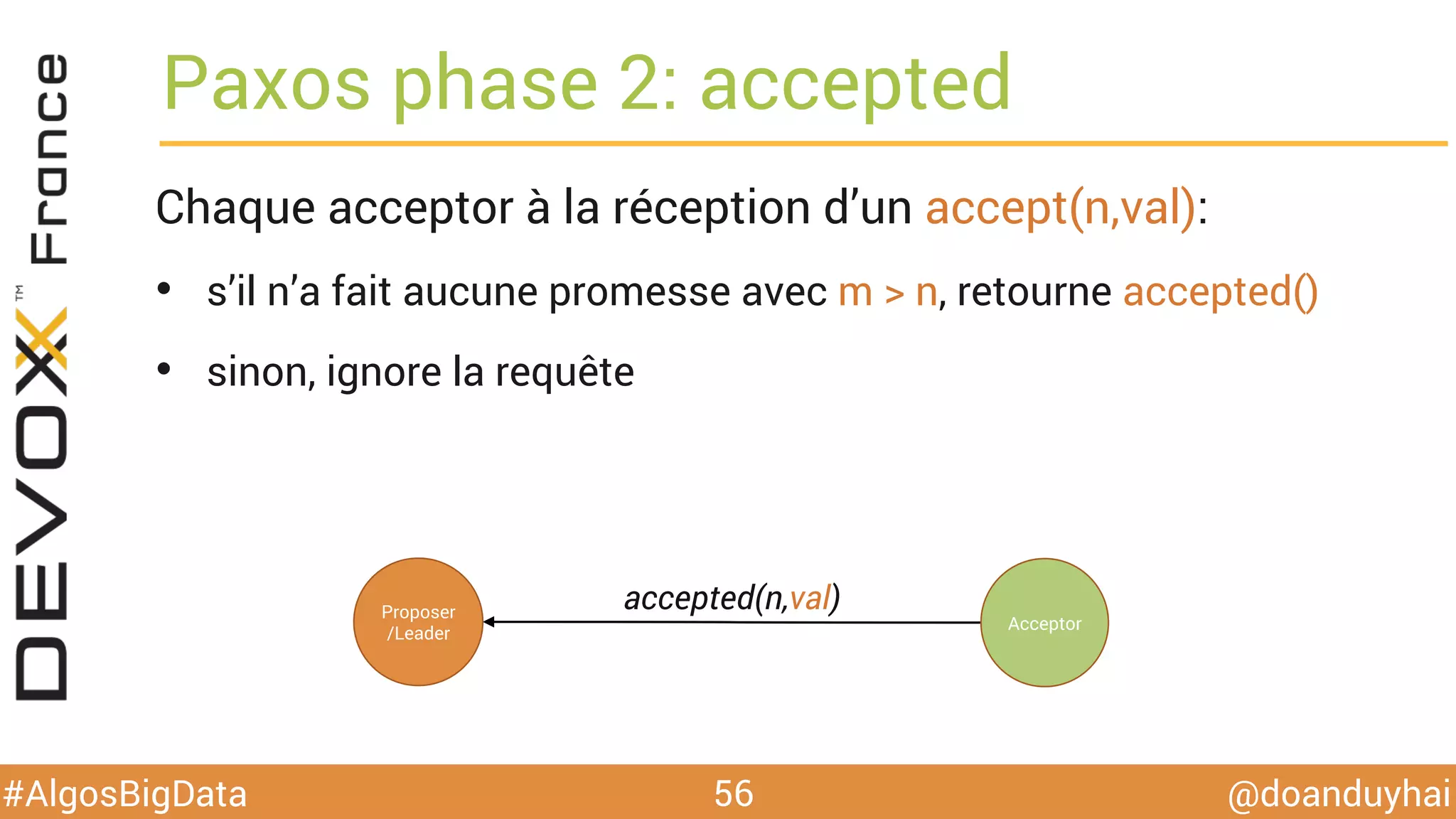


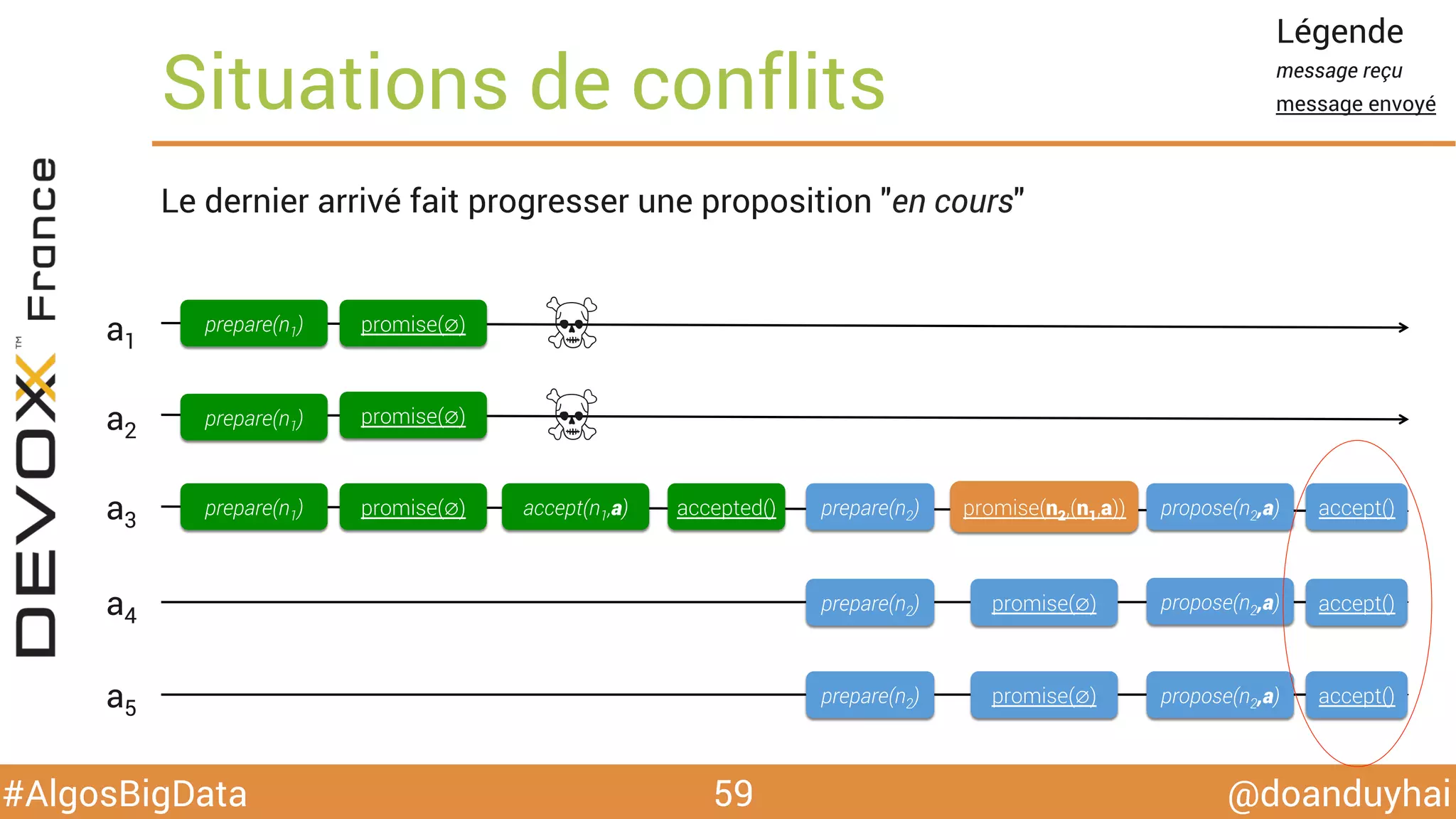
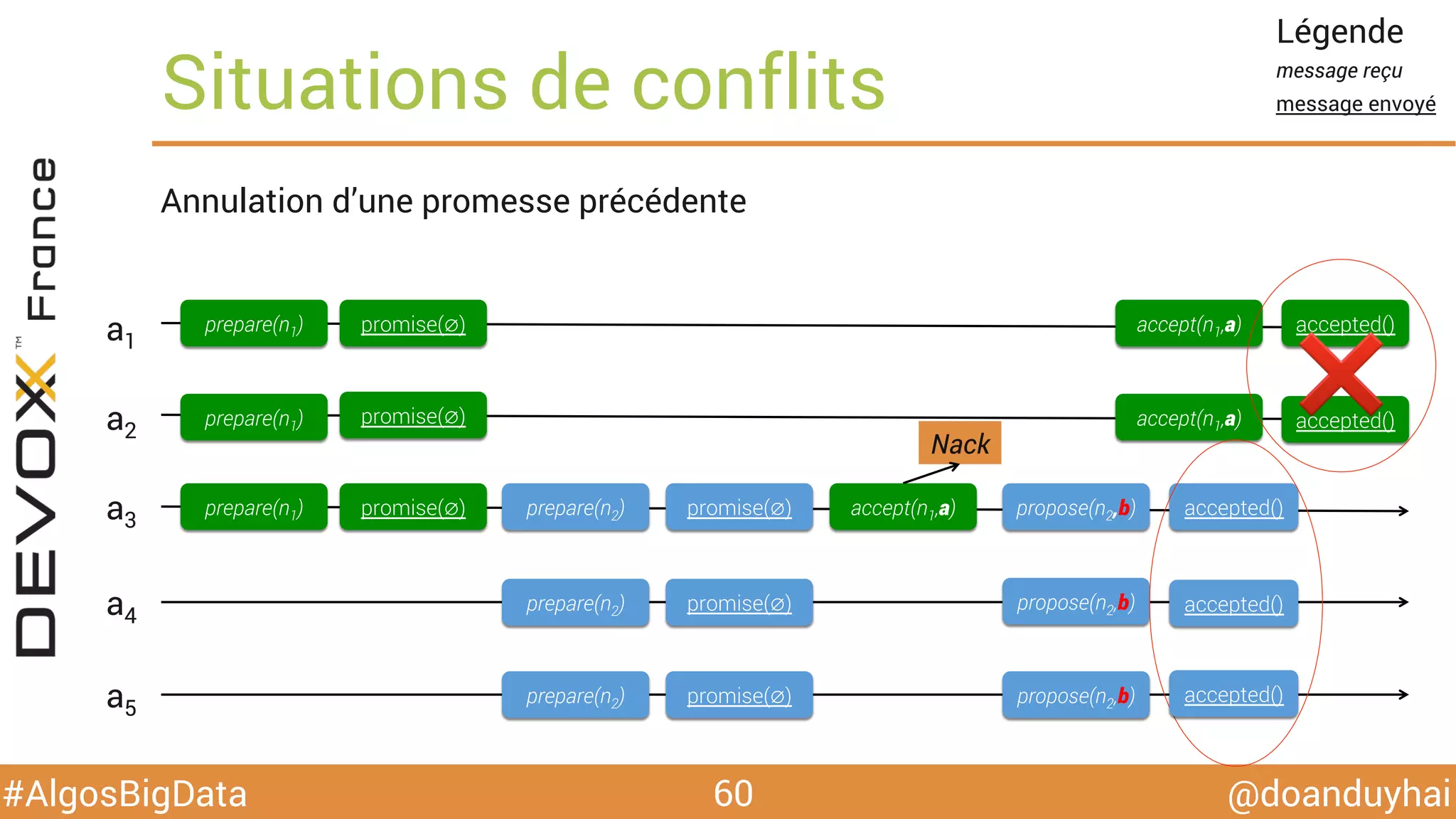
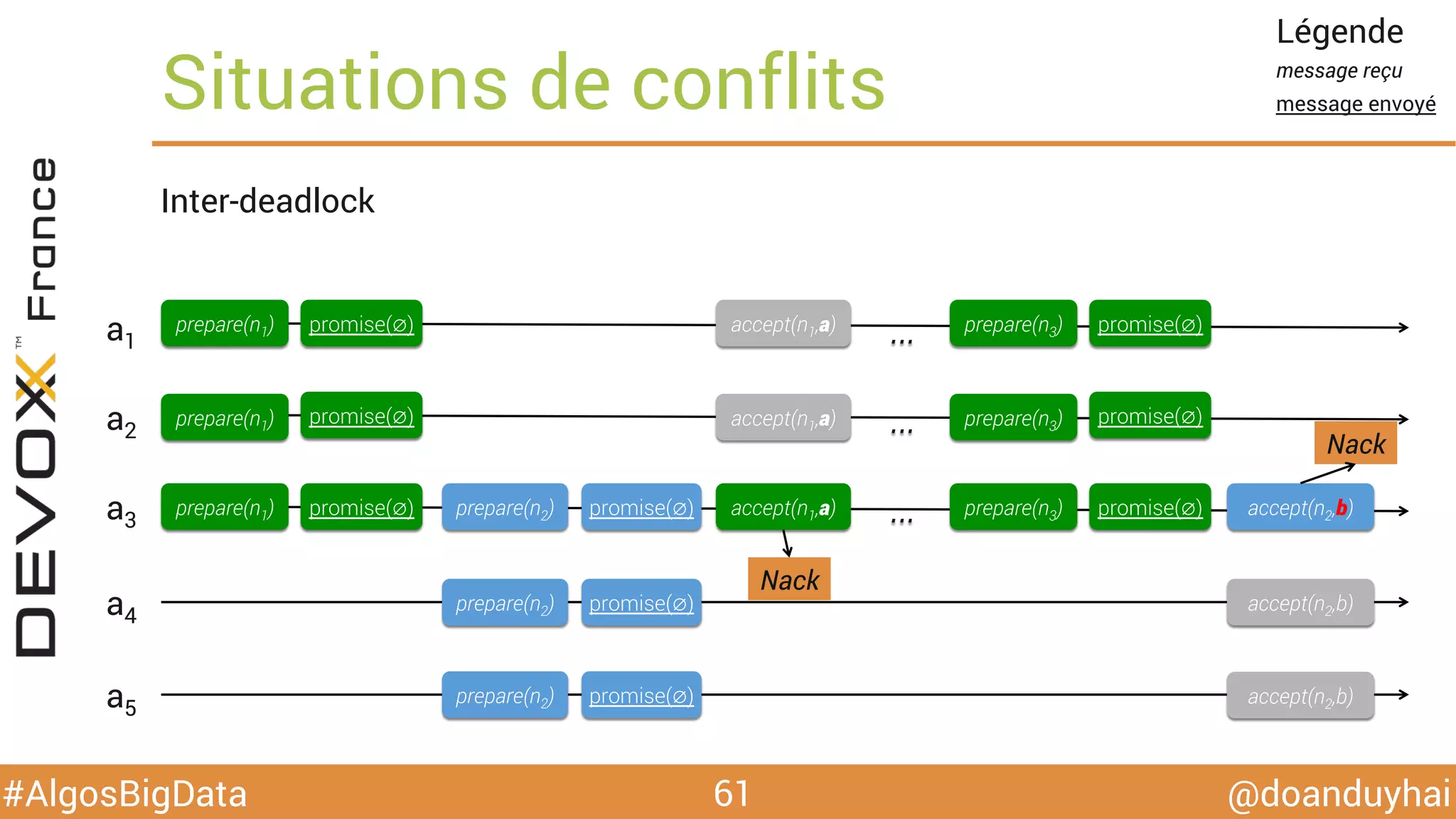
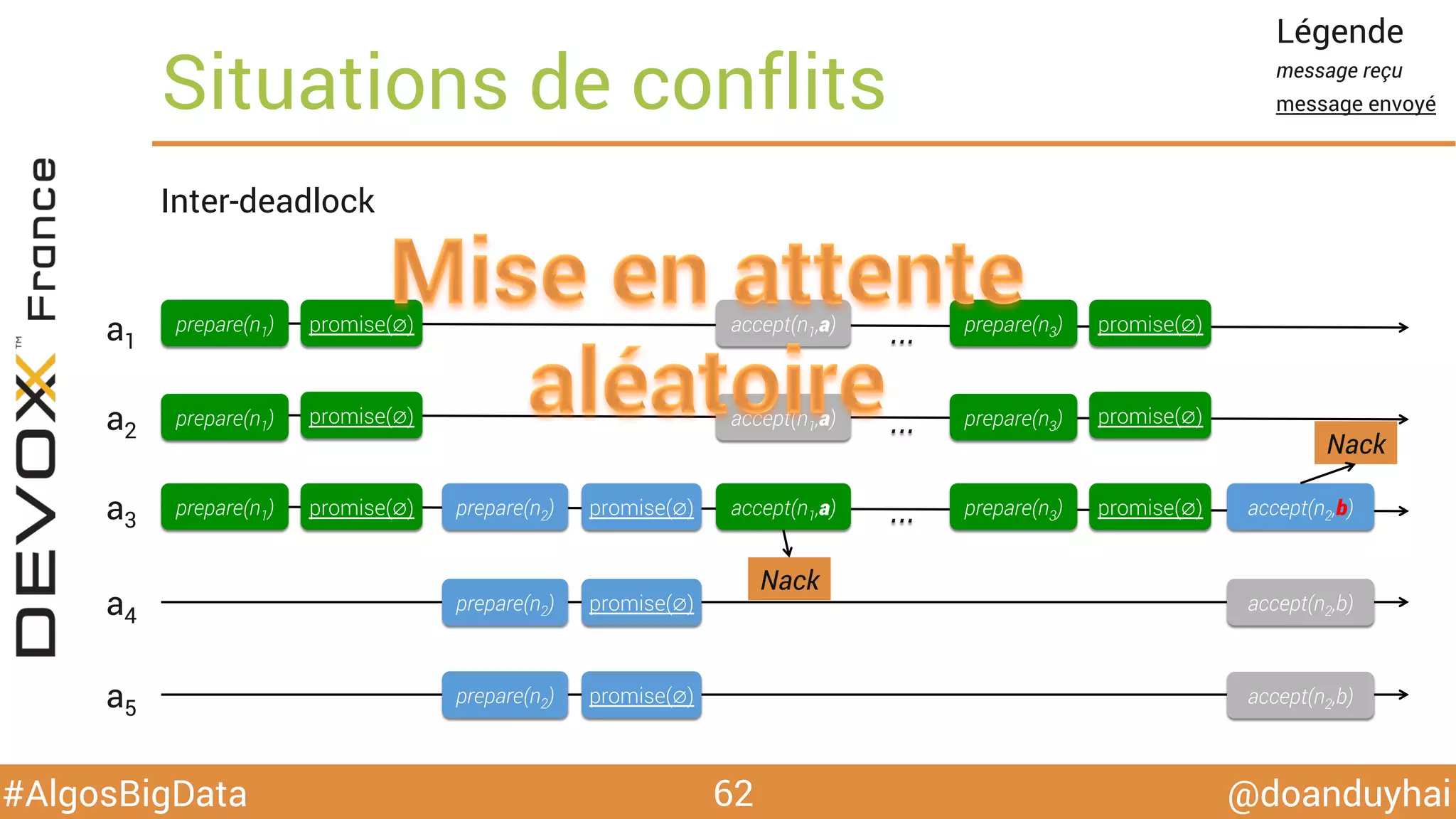









Le document traite d'algorithmes distribués appliqués au big data, incluant des techniques de comptage d'éléments distincts, en particulier l'approche HyperLogLog pour estimer la cardinalité dans de grands ensembles. Il aborde aussi le consensus distribué à travers le protocole Paxos, ses phases de promesse et d'acceptation, ainsi que les défis de gestion des pannes et de coordination dans des environnements distribués. Enfin, des exemples d'implémentation de ces algorithmes dans des systèmes comme Cassandra et Redis sont présentés.















































