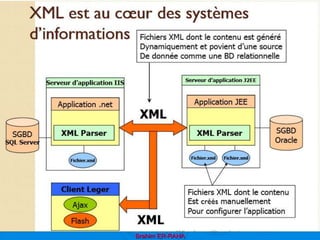
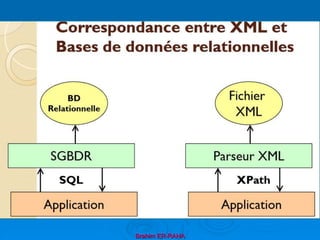
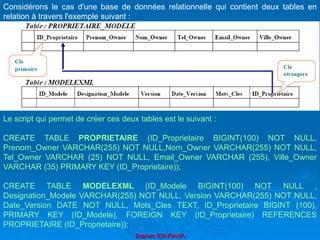
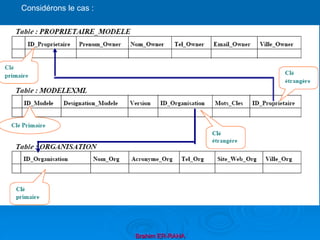
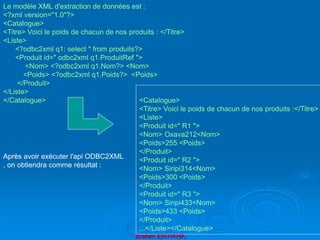
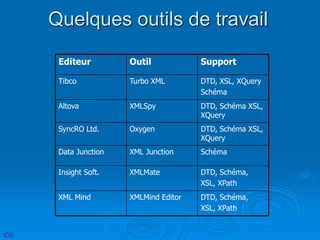
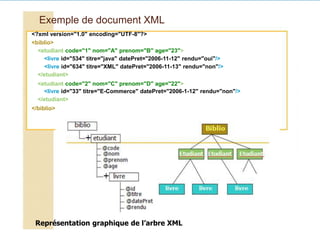
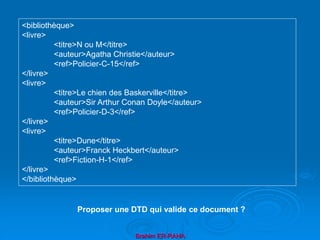
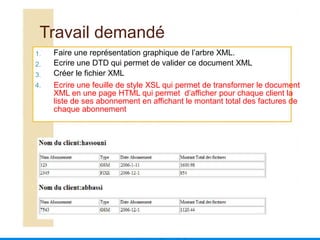
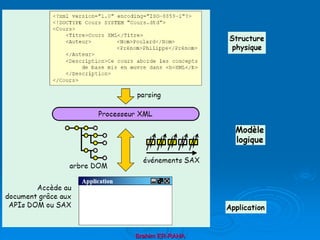
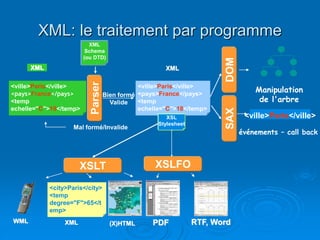
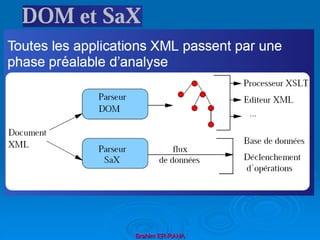
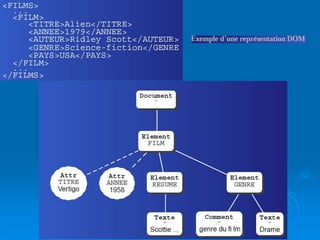
Le document présente une introduction au langage XML, en expliquant ses caractéristiques, sa structure, et ses avantages par rapport à HTML. XML permet de séparer le contenu de la présentation, facilitant ainsi l'échange de données entre différentes applications et plateformes. Il met également en lumière les outils et mécanismes nécessaires pour manipuler et valider les documents XML.



















![Brahim ER-RAHA
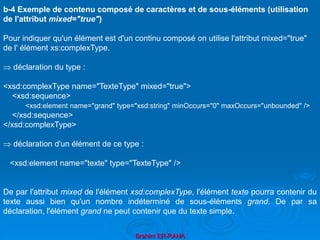
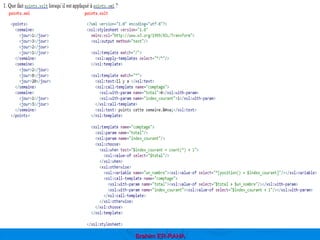
En fait, la première paire de balises d'un document XML sera considéré
comme la balise de racine [root]. Par exemple :
<racine>
suite du document XML ...
</racine>
Par exemple :
<parents>
<enfants>
<petits_enfants> ... </petits_enfants>
</enfants>
</parents>
e- Tout document XML doit comporter une racine.
Le XML peut avoir (comme le Html) des attributs avec des valeurs. En XML, les
valeurs des attributs doivent obligatoirement être entre des guillemets, au
contraire du Html où leur absence n'a plus beaucoup d'importance. Ainsi,
l'écriture suivante est incorrecte car il manque les guillemets.
<date anniversaire=071185> La bonne écriture est :
<date anniversaire="071185">
f- Les attributs des éléments](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-32-320.jpg)

![Brahim ER-RAHA
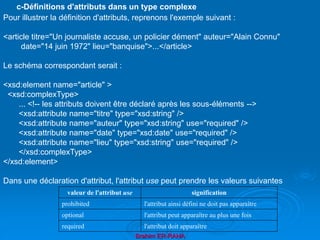
Un élément peut contenir d’autres éléments, des données, des références à des
entités, des sections littérales et des instructions de traitement.
Un élément peut avoir un contenu récursif, c’est à dire qu’il peut contenir une
instance du même type d’élément que lui-même.
Les données des éléments peuvent contenir tous les caractères autorisés sauf le
et commercial & et le inférieur <. Mais on peut toujours utilisé la section CDATA,
Par exemple :
<test>
<code><![CDATA[Ici on peut mettre ce que l'on
veut, < ou &, sans
problèmes, sauf la chaîne ]]>, bien sûr
</code>
</test>
h- Contenu d’un élément](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-34-320.jpg)



![Brahim ER-RAHA
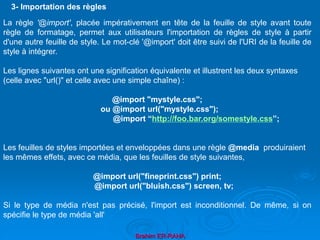
a- DTD interne
Un document valide peut inclure directement sa DTD dans sa déclaration de type.
L'attribut standalone doit prendre la valeur yes, indiquant ainsi que le document
est complet et qu'aucune déclaration externe ne doit être recherchée.
Exemple :
<?xml version="1.0" standalone="yes" ?>
<!DOCTYPE carte [
<!ELEMENT carte (#PCDATA)>
]>
<carte>As de pique</carte>
b- DTD externe
Le document peut aussi faire référence à une DTD stockée dans une entité
externe. L'avantage est alors la réutilisation possible de la DTD.
Exemple : Fichier jeu.xml
<?xml version="1.0" standalone="no" ?>
<!DOCTYPE carte SYSTEM "carte.dtd"> Fichier carte.dtd
<carte>As de pique</carte>
II-3 Utilisation des DTD](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-38-320.jpg)
![Brahim ER-RAHA
La déclaration de type de document indique, le cas échéant, la DTD à laquelle
se conforme le document. Elle permet aussi de spécifier certaines déclarations
propres au document. La syntaxe de déclarations est :
Syntaxe : <!DOCTYPE Racine [ déclarations ]>
Racin : est le nom de l’élément racine de document XML.
Déclarations : ils contient la définition de tous les éléments constituant le
document XML. Il s’agit de :
les éléments types, i.e. elle donne les noms de tous les éléments et leur
modèle de contenu ;
les attributs pour chaque élément (nom, type et valeur par défaut) ;
les entités et les notations qui servent à identifier les types spécifiques de
données externes.
1- Syntaxe d’utilisation d’une DTD](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-39-320.jpg)






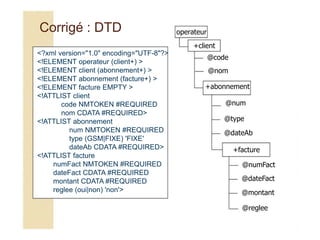



![Brahim ER-RAHA
- Entités paramètres
<!ENTITY % nom « chaîne_de_remplacement »>
Ces entités apparaissent uniquement dans les DTD. Ce sont des raccourcis vers des
parties de déclarations de la DTD.
Exemple :
<?xml version="1.0" encoding="ISO-8859-1"?>
<!DOCTYPE article [
<!ENTITY % fich-dtd-1 SYSTEM "fichier-1.dtd">
<!ENTITY % fich-dtd-2 SYSTEM "fichier-2.dtd">
%fich-dtd-1;
%fich-dtd-2;
<!ENTITY % texte "#PCDATA">
<!ELEMENT nom (%texte;)>
<!ELEMENT prénom (%texte;)>
..
]>](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-52-320.jpg)


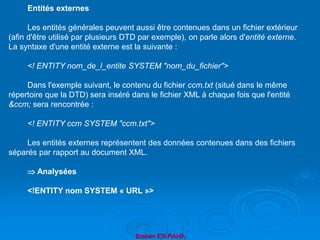
![Brahim ER-RAHA
<!DOCTYPE book SYSTEM « book.dtd »
[
<!ENTITY toc SYSTEM « toc.xml »>
<!ENTITY chap1 SYSTEM « chapters/c1.xml »>
<!ENTITY chap2 SYSTEM « chapters/c2.xml »>
<!ENTITY index SYSTEM « index.xml »>
]>
<book>
<head>&toc;</head>
<body>
&chap1;
&chap2;
&index;
</body>
</book>
Exemple :](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-56-320.jpg)


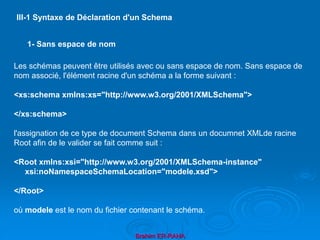



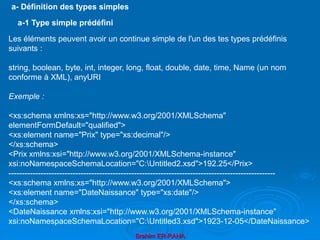




![Brahim ER-RAHA
1- Restriction
Une restriction limite les valeurs possibles d'un type donné (appelé type de base) et est
définie sur certaines propriétés du type de base, appelées facettes de contraintes
dont les valeurs les plus utilisés sont :
-length (longueur de chaîne) ou minLength et maxLength (bornes inf. et sup. de la
langueur)
- pattern (expression régulière)
- enumeration (ens. de valeurs)
- minInclusive, maxInclusive , minExclusive, maxExclusive (bornes des valeurs)
- totalDigits (nombre de chiffres d'un nb. entier)
-fractionalDigits (nombre de chiffres significatifs pour la partie décimale)
la facette pattern permet de contraindre la forme lexicale à l'aide d'une expression
régulière (en perl)
- [abc] désigne les lettres a, b, c
- [a-z] désigne les lettres allant de a à z
- ^[abc] signifie toutes les lettres sauf a, b, c
- E? signifie 0 ou 1 fois
- E* signifie 0 ou plusieurs fois
- E+ signifie 1 ou plusieurs fois
- E{n,m} signifie entre n et m fois
- E{n} signifie exactement n fois
- E|F signifie soit E soit F
- sert de caractère d'échappement](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-68-320.jpg)
![Brahim ER-RAHA
<xsd:simpleType name="Code">
<xsd:restriction base="xsd:integer">
<xsd:minInclusive value="1000" />
<xsd:maxInclusive value="9999" />
</xsd:restriction>
</xsd:simpleType>
<xsd:element name="AA" type="Code"/>
<AA> 9999 </AA>
<xsd:simpleType name="JourDeSemaine">
<xsd:restriction base="xsd:string">
<xsd:enumeration value="lundi" />
<xsd:enumeration value="mardi" />
<xsd:enumeration value="mercredi" />
<xsd:enumeration value="jeudi" />
<xsd:enumeration value="vendredi" />
<xsd:enumeration value="samedi" />
<xsd:enumeration value="dimanche" />
</xsd:restriction>
</xsd:simpleType>
<xsd:element name="AA" type="JourDeSemaine"/>
<AA> lundi </AA>
<xsd:simpleType name="Date"> <xsd:restriction
base="xsd:string"><xsd:pattern value="d{2}-
d{2}-d{4}"/>
</xsd:restriction></xsd:simpleType>
<xsd:element name="AA" type="Date"/>
<AA> 23-05-1998 </AA>
<xsd:simpleType name="code"> <xsd:restriction
base="xsd:string"><xsd:pattern value="[A-Za-z]{6}-
d{2}"/> </xsd:restriction></xsd:simpleType>
<xsd:element name="AA" type="code"/>
<AA> Agadir-25 </AA>
<xs:simpleType name="type-no-tel">
<xs:restriction base="xs:string">
<xs:pattern
value="0[1-9]{1,2} [0-9]{3} [0-9]{3}" />
</xs:restriction>
</xs:simpleType>
<xsd:element name="AA" type="type-no-yel"/>
<AA> 066 000 000 </AA>
<xs:simpleType name="AS">
<xs:restriction base="xs:float">
<xs:totalDigits value="4"/>
<xs:fractionDigits value="2"/>
</xs:restriction>
</xs:simpleType>
<xs:element name="AA" type="AS"/>
<AA> 12.56 </AA>](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-69-320.jpg)





























![Brahim ER-RAHA
Motif Signification Décrit au chapitre...
* Correspond à tout élément. Sélecteur universel
E Correspond à tout élément E (c.à.d., un élément de type E). Sélecteurs de type
E F Correspond à tout élément F qui est un descendant de l'élément E. Sélecteurs descendants
E > F Correspond à tout élément F aussi un enfant de l'élément E. Sélecteurs d'enfant
E:first-child
Correspond à un élément E aussi le premier enfant de son élément
parent.
La pseudo-classe :first-
child
E,F,G Groupement des éléments F, E et G Sélecteurs de type
E:lang(c)
Correspond à l'élément de type E qui emploie une langue c (la
détermination de cette langue est spécifique au langage du
document).
La pseudo-classe :lang()
E + F
Correspond à tout élément F immédiatement précédé par un élément
E.
Les sélecteurs adjacents
E[foo]
Correspond à tout élément E avec l'attribut "foo" (quelles qu'en
soient les valeurs).
Sélecteurs d'attribut
E[foo="warni
ng"]
Correspond à tout élément E dont l'attribut "foo" a exactement la
valeur "warning".
Sélecteurs d'attribut
E[foo~="warn
ing"]
Correspond à tout élément E dont l'attribut "foo" a pour valeur une
liste de valeurs séparées par des blancs et dont une de celles-ci est
"warning".
Sélecteurs d'attribut
E[lang|="en"]
Correspond à tout élément E dont l'attribut "lang" a pour valeur une
liste de valeurs séparées par des tirets, cette liste commençant (à
gauche) par "en".
Sélecteurs d'attribut
6- Sélecteurs d’éléments : Les sélecteurs d’éléments disponibles en CSS sont :](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-102-320.jpg)
![Brahim ER-RAHA
-Pa > el [att= "foo "] {propriété : valeur} sélectionne tout élément el ayant
l’attribut att= "foo ", et fils d’un élément pa.
- pa [att="bar"]>* {propriété : valeur}sélectionne n'importe quel élément (*), fils
d'un élément pa, et doté de l'attribut att="bar".
Exemple :
7- Propriétés
7-1 Dimension
Lorsque on exprime la dimension (hauteur, largeur, épaisseur, distance) d'une
propriété, celle-ci est généralement indiquer à l'aide d'une unités absolues ou
relatives:
Les unités absolues sont :
- in : pouce, soit 2,54 cm
- cm : centimètre
- mm : millimètre
- pt : point typographique
- pc : pica (=12 points)
Les unités relatives sont :
- em : égale à la taille de la police courante.
- ex : égale à la hauteur de glyphe dans la police
courante](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-103-320.jpg)







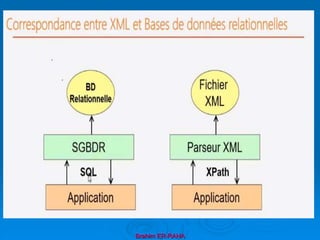
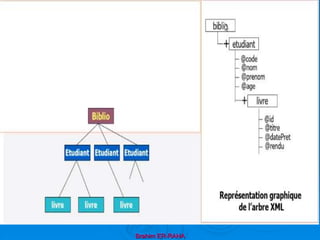
![Brahim ER-RAHA
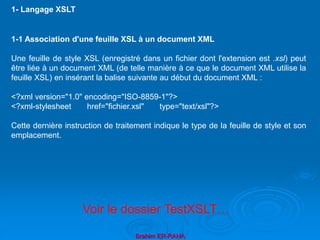
Le langage XPath est un standard du W3C pour décrire des "patterns"
(localisation de nœud) et extraire des valeurs de l'arbre du document XML. Il sert
en fait 2 autres "standards" XML :
XSLT : partie de XSL, ensemble de règles de transformation d'un document XML
vers un autre document.
XPointer : mécanisme de pointage pour les liens XLink de XML.
Un sélecteur de nœud (XPATH) est formée de trois parties :
<xsl:template match="//nom[position()=1]">
• un axe : il permet de se déplacer dans l'arbre du document
• un test : il permet de sélectionner un nœud
• un prédicat (entre crochets [xx]): il effectue une opération booléenne sur le
nœud sélectionné.
Considérons l'exemple suivant: (Fichier atome.xml)
a- Langage Xpath](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-115-320.jpg)


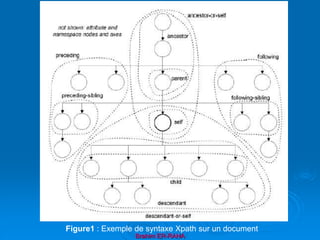


![Brahim ER-RAHA
Prédicat
Les prédicats sont utilisés dans les tests de XSLT. De plus, l'ensemble des nœuds
obtenus par un chemin XPtah peut être filtré à l'aide de prédicats entre crochets [].
Supposons que le nœud courant soit <famille type="gaz rare">
./atome[3] sélectionne le 3ème élément atome fils du nœud courant
./atome[position()=3] sélectionne l'élément atome fils du nœud courant dont le
position est en 3ème place.
atome[last()] sélectionne le dernier élément atome fils du nœud courant
atome[numero!=4] sélectionne les éléments atome fils du nœud courant dont le
numéro est différent de 4
atome[numero >= 4] Remarquons qu'il faut utiliser < (respectivement >) à la
place de < (resp. >) dans les documents XML
following-sibling :: .[@type="non métal"] sélectionne les nœuds frère (suivant dans
le document) du nœud courant dont l'attribut type vaut "non métal"
atome[masse mod 2 =1] sélectionne les éléments atome fils du nœud courant dont la
masse est impair.](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-121-320.jpg)
![Brahim ER-RAHA
../famille[(@type="non métal") and (atome/masse > 34)] sélectionne les nœuds
famille fils du père du nœud courant dont l'attribut type vaut "non
métal" et dont l'un des fils atome a un fils masse dont le
contenu est > à 34.
../famille[@type="non métal"]/atome[masse > 34] sélectionne les nœuds atome,
ayant un fils masse dont le contenu est > à 34, et qui sont fils de nœud
famille fils du nœud racine dont l'attribut type vaut "non métal".
/famille/atome[3] [masse > 34] sélectionne parmi les 3ème éléments atome des fils
famille du nœud racine ceux dont la masse est > à 34
/famille/atome[masse > 34] [3] sélectionne le 3ème élément parmi les atomes,
dont la masse est > à 34, des fils famille du nœud racine
/famille[count(atome[masse > 34]) != 0] sélectionne les nœuds famille du nœud
racine ayant au moins un fils atome de masse > à 34
/famille[not(contains(@type, 'gaz'))] sélectionne les nœuds famille du nœud racine
ayant un attribut type qui ne comporte pas la chaine 'gaz'
opérateurs : and, or, *, +, -, /, mod
fonctions numériques : number, sum, floor, ceiling, round
fonctions booléennes : not, lang](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-122-320.jpg)
![Brahim ER-RAHA
Correspondance entre syntaxe Xpath simple et étendu
Syntaxe Etendu Syntaxe Simple
/child::film/child::acteur /film/acteur
/child::cinéma/descendant::acteur /cinéma//acteur
/descendant::* //*
/descendant::film[@année=’2000’] //film[@année=’2000’]
Self .
Parent ..](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-123-320.jpg)


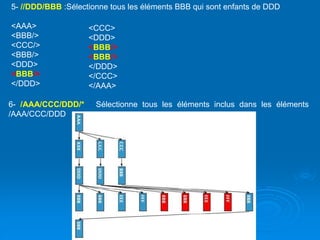
![Brahim ER-RAHA
7- /AAA/BBB[1] : Sélectionne le premier élément BBB, fils de l'élément racine AAA
<AAA>
<BBB/>
<BBB/>
<BBB/>
<BBB/>
</AAA>
8- /AAA/BBB[last()] : Sélectionne le dernier élément :BBB, fils de l'élément racine
AAA
<AAA>
<BBB/>
<BBB/>
<BBB/>
<BBB/>
</AAA>
9- //@id : Sélectionne tous les attributs id
<AAA>
<BBB id = "b1"/>
<BBB id = "b2"/>
<BBB name = "bbb"/>
<BBB/>
</AAA>](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-128-320.jpg)
![Brahim ER-RAHA
10- //BBB[@id] : Sélectionne tous les BBB qui ont un attribut id
<AAA>
<BBB id = "b1"/>
<BBB id = "b2"/>
<BBB name = "bbb"/>
<BBB/>
</AAA>
10- //BBB[@name] Sélectionne tous BBB qui ont un attribut name
<AAA>
<BBB id = "b1"/>
<BBB id = "b2"/>
<BBB name = "bbb"/>
<BBB/>
</AAA>
11- //BBB[@*] Sélectionne tous BBB qui ont un attribut
<AAA>
<BBB id = "b1"/>
<BBB id = "b2"/>
<BBB name = "bbb"/>
<BBB/>
</AAA>
12- //BBB[not(@*)] :Sélectionne
Tous les BBB qui n'ont pas d'attribut
<AAA>
<BBB id = "b1"/>
<BBB id = "b2"/>
<BBB name = "bbb"/>
<BBB/>
</AAA>](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-129-320.jpg)
![Brahim ER-RAHA
13- //BBB[@id='b1'] :Sélectionne tous les éléments BBB ayant un attribut id dont la
valeur est b1
<AAA>
<BBB id = "b1"/>
<BBB name = " bbb "/>
<BBB name = "bbb"/>
</AAA>
14- //BBB[@name='bbb'] : Sélectionne tous les éléments BBB ayant un attribut name
dont la valeur est bbb
<AAA>
<BBB id = "b1"/>
<BBB name = " bbb "/>
<BBB name = "bbb"/>
</AAA>
15- //BBB[normalize-space(@name)='bbb'] :Sélectionne tous les éléments BBB
ayant un attribut name dont la valeur est bbb. Les espaces de début et de fin sont
supprimés avant la comparaison
<AAA>
<BBB id = "b1"/>
<BBB name = " bbb "/>
<BBB name = "bbb"/>
</AAA>](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-130-320.jpg)
![Brahim ER-RAHA
16- //*[count(BBB)=2]
Sélectionne les éléments ayant deux enfants BBB
<AAA>
<CCC>
<BBB/>
<BBB/>
<BBB/>
</CCC>
<DDD>
<BBB/>
<BBB/>
</DDD>
<EEE>
<CCC/>
<DDD/>
</EEE>
</AAA>
17- //*[count(*)=2] : Sélectionne les éléments ayant
deux enfants
<AAA>
<CCC>
<BBB/>
<BBB/>
<BBB/>
</CCC>
<DDD>
<BBB/>
<BBB/>
</DDD>
<EEE>
<CCC/>
<DDD/>
</EEE>
</AAA>](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-131-320.jpg)
![Brahim ER-RAHA
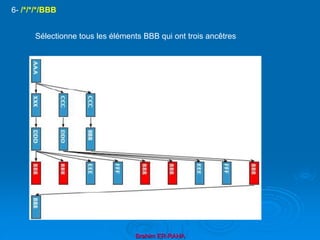
18- //*[count(*)=3] : Sélectionne les éléments ayant trois enfants](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-132-320.jpg)
![Brahim ER-RAHA
19- //*[name()='BBB']
La fonction name() retourne le nom de l'élément](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-133-320.jpg)
![Brahim ER-RAHA
21- //*[starts-with(name(),'B')] :
la fonction start-with retourne vrai si la chaîne du premier argument commence
par celle du deuxième
<AAA>
<BCC>
<BBB/>
<BBB/>
<BBB/>
</BCC>
<DDB>
<BBB/>
<BBB/>
</DDB>
<BEC>
<CCC/>
<DBD/>
</BEC>
</AAA>
22- //*[contains(name(),'C')]
<AAA>
<BCC>
<BBB/>
<BBB/>
<BBB/>
</BCC>
<DDB>
<BBB/>
<BBB/>
</DDB>
<BEC>
<CCC/>
<DBD/>
</BEC>
</AAA>](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-134-320.jpg)
![Brahim ER-RAHA
23- //*[string-length(name()) = 3]
<AAA>
<Q/>
<SSSS/>
<BB/>
<CCC/>
<DDDDDDDD/>
<EEEE/>
</AAA>
24- //*[string-length(name()) < 3]
<AAA>
<Q/>
<SSSS/>
<BB/>
<CCC/>
<DDDDDDDD/>
<EEEE/>
</AAA>
26- //CCC | //BBB : Sélectionne tous les éléments
CCC et BBB
<AAA>
<BBB/>
<CCC/>
<DDD>
<CCC/>
</DDD>
<EEE/>
</AAA>](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-135-320.jpg)


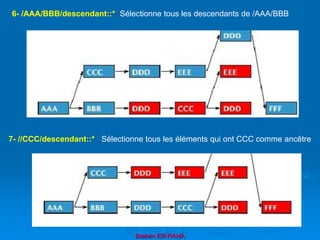
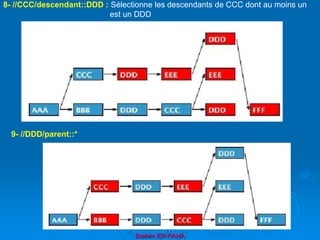
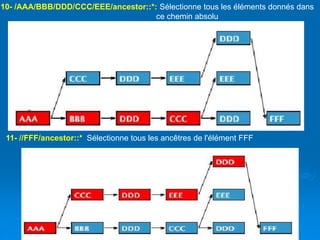
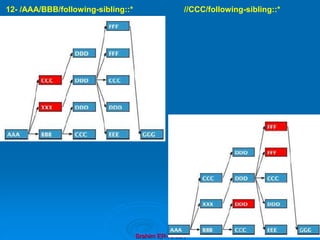
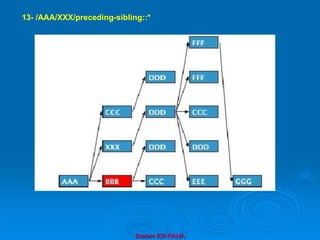
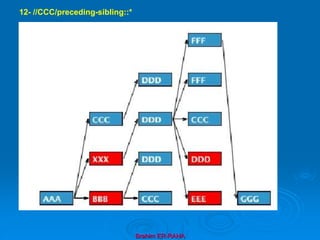
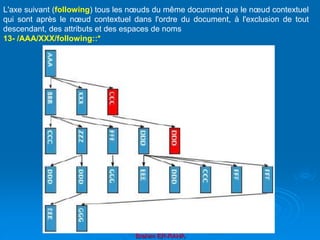
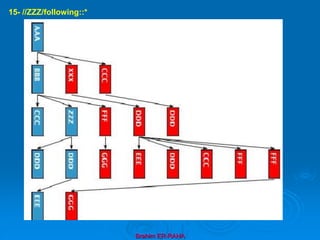
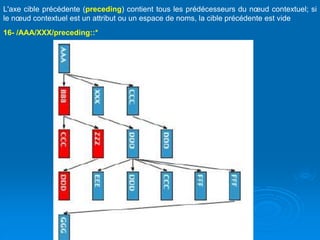
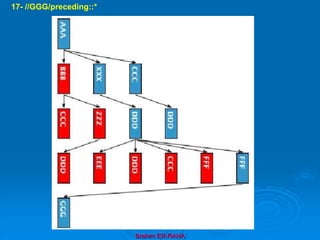
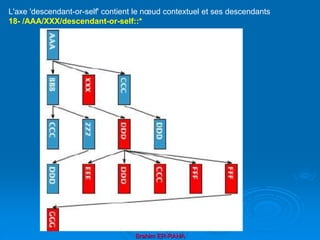
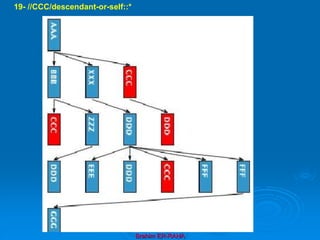
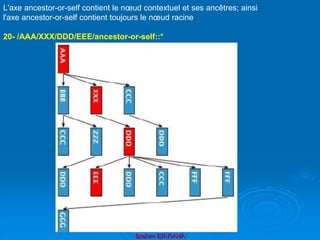
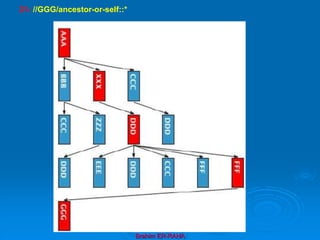
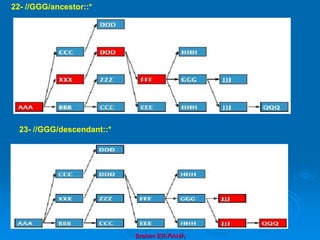
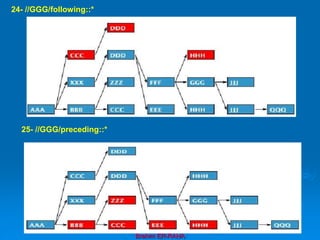
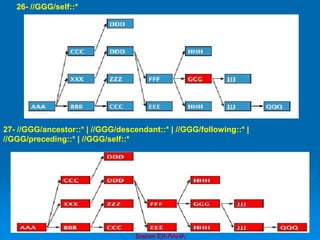
![Brahim ER-RAHA
III- les opérateurs
L'opérateur div réalise une division à virgule flottante, l'opérateur mod retourne le
reste d'une division. La fonction floor() retourne le plus grand nombre (le plus près
de l'infini positif) qui n'est pas plus grand que l'argument et qui est un entier. La
fonction ceiling() retourne le plus petit nombre (le plus près de l'infini négatif) qui
n'est pas plus petit que l'argument et qui est un entier
1- //BBB[position() mod 2 = 0 ]
<AAA>
<BBB/>
<BBB/>
<BBB/>
<BBB/>
<BBB/>
<BBB/>
<BBB/>
<BBB/>
<CCC/>
<CCC/>
<CCC/>
</AAA>](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-155-320.jpg)
![Brahim ER-RAHA
2- //BBB[ position() = floor(last() div 2 + 0.5) or position() = ceiling(last() div 2 + 0.5) ]
<AAA>
<BBB/>
<BBB/>
<BBB/>
<BBB/>
<BBB/>
<BBB/>
<BBB/>
<BBB/>
<CCC/>
<CCC/>
<CCC/>
</AAA>
3- //CCC[ position() = floor(last() div 2 + 0.5) or position() = ceiling(last() div 2 + 0.5) ]
<AAA>
<BBB/><BBB/>
<BBB/>
<BBB/>
<BBB/>
<BBB/>
<BBB/>
<BBB/>
<CCC/>
<CCC/>
<CCC/></AAA>](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-156-320.jpg)









































































![Brahim ER-RAHA
Requête:
document("bib.xml")//book/author[la eq "Scholl"]
Résultat:
<author><la>Scholl</la><fi>M.</fi></author>
Requête:
document("bib.xml")//book[author/la eq "Scholl"]
Résultat:
ERROR
L’expression author/la dans le prédicat ne retourne pas une
valeur atomique mais une séquence de valeurs.
COMPARAISON DE VALEURS ATOMIQUES](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-252-320.jpg)



![Brahim ER-RAHA
Comparaisons de noeuds
L’expression /bib/book[@id="1"] << /bib/book[@id="2"]
a la valeur true](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-256-320.jpg)
![Brahim ER-RAHA
Comparaison de l’identité de deux noeuds : s1 is s2
s1 est identique à s2
Requête:
document("bib.xml")//book[author[2] is author[last()]]
Résultat:
<book title="Comprendre XSLT">
<author><la>Amann</la><fi>B.</fi></author>
<author><la>Rigaux</la><fi>P.</fi></author>
<publisher>O’Reilly</publisher>
<price>28.95</price>
</book>
Comparaisons de noeuds](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-257-320.jpg)
![Brahim ER-RAHA
Comparaison de la position de deux noeuds : s1<<s2 (s1>>s2)
s1 apparaît avant (après) s2 dans le document.
Requête:
<livre>
{ document("bib.xml")//book[author[la="Abiteboul"] <<
author[la="Suciu"]]/@title }
</livre>
Résultat:
<livre title="Data on the Web"/>
Comparaisons par la position](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-258-320.jpg)



![Brahim ER-RAHA
Requête:
<livre>
(:Le prix suivi des auteurs:) 'commentaire
{ document("bib.xml")//book[1]/(price,author) }
</livre>
Résultat:
<livre>
Le prix suivi des auteurs:
<price>28.95</price>
<author><la>Amann</la><fi>B.</fi></author>
<author><la>Rigaux</la><fi>P.</fi></author>
</livre>
On a changé l’ordre des noeuds (#union)
CONCATÉNATION DE SÉQUENCES](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-262-320.jpg)



![Brahim ER-RAHA
Expressions de chemins
Chaque étape est une expression XQuery (XPath 2.0) :
doc(“bib.xml”)/bib/book/author
doc(“bib.xml”)/bib//book[1]/publisher
doc(“bib.xml”)//book/(author, publisher) :résultat ?
doc(“bib.xml”)/(descendant::author,descendant::publisher) :
résultat ?
doc(“bib.xml”)//book/(@title union publisher)
doc(“bib.xml”)//book[position() lt last()]](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-267-320.jpg)


![Brahim ER-RAHA
Le nom et le contenu sont calculés:
element { expr-nom } { expr-contenu }
attribute { expr-nom } { expr-contenu }
Requête:
element { document("bib.xml")//book[1]/name(*[1]) } {
attribute { document("bib.xml")//book[1]/name(*[3]) } {
document("bib.xml")//book[1]/*[3]
}
}
Résultat:
<title publisher="Addison-wesley"/>](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-270-320.jpg)

![Brahim ER-RAHA
La clause for $var in exp affecte la variable $var successivement avec
chaque item dans la séquence retournée par exp.
La clause let $var := exp affecte la variable $var avec la séquence
“entière” retournée par exp.
Requête:
for $b in document("bib.xml")//book[1]
let $al := $b/author
return <livre nb_auteurs="{count($al)}">
{ $al }
</livre>
Résultat:
<livre nb_auteurs="2">
<author><la>Amann</la><fi>B.</fi></author>
<author><la>Rigaux</la><fi>P.</fi></author>
</livre>
Affectation de variables: for et let (FLWOR)](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-272-320.jpg)


![Brahim ER-RAHA
La clause where exp permet de filtrer le résultat par rapport au résultat
booléen de l’expression exp (= prédicat dans l’expression de chemin).
Requête:
<livre>
{ for $a in document("bib.xml")//book
where $a/author[1]/la eq "Abiteboul"
return $a/@title
}
</livre>
Résultat:
<?xml version="1.0"?>
<livre title="Data on the Web"/>
SÉLECTION: WHERE](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-275-320.jpg)





![Brahim ER-RAHA
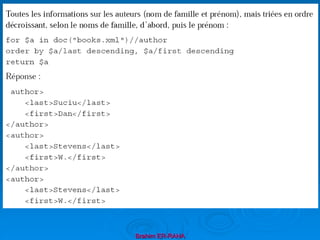
some $var in expr1 satisfies expr2 il existe au moins un noeud
retourné par l’expression expr1 qui satisfait l’expression expr2.
every $var in expr1 satisfies expr2 tous les nœuds retournés
par l’expression expr1 satisfont l’expression expr2
Requête:
for $a in document("bib.xml")//author
where every $b
in document("bib.xml")//book[author/la = $a/la]
satisfies $b/publisher="Morgan Kaufmann Publishers"
return string($a/la)
Résultat:
Scholl, Voisard, Abiteboul, Buneman, Suciu
QUANTIFICATION](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-282-320.jpg)


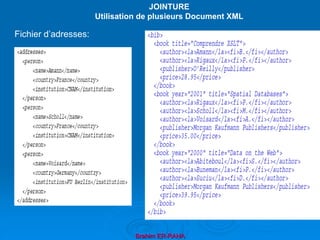






![Déclaration de variables externes
Les variables externes sont déclarées de
la manière suivante :
◦ declare variable $v [as type] external;
◦ Exemple :
◦ declare variable $v as xs:double external;
Les types de variables
Les types, aussi bien pour les variables que
pour les signatures des fonctions, sont ceux
de XSD avec, en plus, des types spécifiques.
La figure(http://www.w3.org/TR/xpath-
functions/type-hierarchy.png ). les rappelle](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-292-320.jpg)





















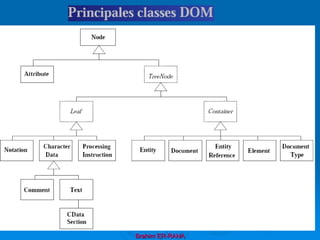










![org.w3c.dom.CDATASection
Hérite de Text
Représente une section littérale
Ne contient pas les balises
<![CDATA[
]]>
Brahim ER-RAHA](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-329-320.jpg)











![Interpréter un fichier XML
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
// Fin de chaque élément
}
@Override
public void endDocument() throws SAXException {
// Fin du document
}
public static void main(String[] args) {
new SaxParser();
}
}](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-343-320.jpg)



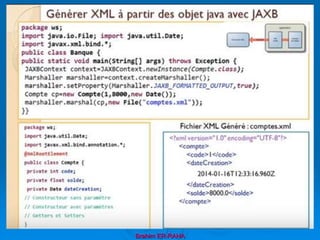
![Exemple d’application pour la création d’un document XML avec JDOM
import java.io.*;import org.jdom.*;
import org.jdom.output.*;
public class App1 {
public static void main(String[] args) throws IOException {
/*Créer l’élément racine */
Element racine = new Element("personnes");
/*Créer un document JDOM basé sur l’élément racine*/
Document document = new Document(racine);
/*Créer un nouveau Element xml etudiant */
Element etudiant = new Element("etudiant");
/* Ajouter cet élément à la racine */
racine.addContent(etudiant);
/*Créer un nouveau attribut classe dont la valeur est P2 */
Attribute classe = new Attribute("classe","P2");
/* Ajouter cet attrubut à l’élément etudiant */
etudiant.setAttribute(classe);
Element nom = new Element("nom"); /* Créer l’élément nom */
nom.setText("Katib"); /* Définir le texte de nom */
etudiant.addContent(nom); /* ajouter nom à etudiant */
/* Afficher et enregistrer le fichier XML */
XMLOutputter sortie=new XMLOutputter(Format.getPrettyFormat());
sortie.output(document, System.out);
sortie.output(document, new FileOutputStream("EX1.xml"));
}}](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-347-320.jpg)

![Afficher les noms des étudiants du fichier XML
import java.io.*;import java.util.List;
import org.jdom.*;import org.jdom.input.SAXBuilder;
public class App2 {
public static void main(String[] args) throws Exception {
/* On crée une instance de SAXBuilder */
SAXBuilder sb=new SAXBuilder();
/* On crée un nouveau document JDOM avec en argument le fichier XML */
Document document=sb.build(new File("EX2.xml"));
/*On initialise un nouvel élément racine avec l'élément racine du
document.*/
Element racine=document.getRootElement();
/* On crée une List contenant tous les noeuds "etudiant" de l'Element
racine */
List<Element> etds=racine.getChildren("etudiant");
/* Pour chaque Element de la liste etds*/
for(Element e:etds){
/*Afficher la valeur de l'élément nom */
System.out.println(e.getChild("nom").getText());
}
}
}](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-349-320.jpg)



![Fichier XSL pour générer une sortie HTML
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:template match="/">
<html>
<head></head>
<body>
<table border="1" width="80%">
<tr>
<th>Nom</th><th>Prénoms</th>
</tr>
<xsl:for-each select="personnes/etudiant">
<tr>
<td><xsl:value-of select="nom"/></td>
<td><xsl:value-of select="prenoms/prenom[1]"/></td>
</tr>
</xsl:for-each>
</table>
</body>
</html>
</xsl:template>
</xsl:stylesheet>](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-353-320.jpg)
![Exemple de transformation XSL avec
JDOM
import java.io.*; import org.jdom.*;
import org.jdom.input.SAXBuilder;
import javax.xml.transform.*;
import javax.xml.transform.stream.StreamSource;
public class JDOM4{
public static void main(String[] args) {
SAXBuilder sb=new SAXBuilder();
try {
Document jDomDoc=sb.build(new
File("Exercice2.xml"));
outputXSLT(jDomDoc, "classe.xsl");
} catch (Exception e) {
e.printStackTrace();
}
}](https://image.slidesharecdn.com/coursxml2019final1-230331235216-fffba734/85/Cours-XML_2019_final-1-ppt-354-320.jpg)