Télécharger en tant que PDF, PPTX



















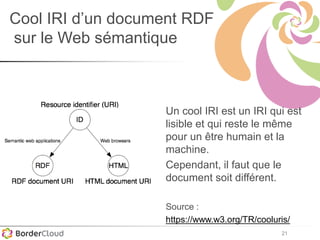
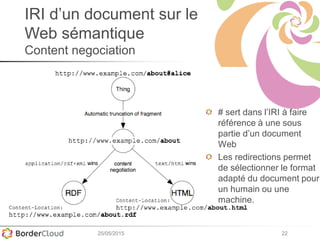
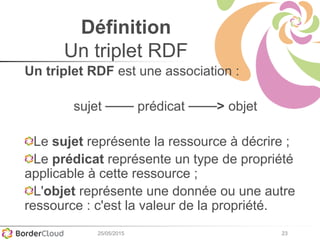




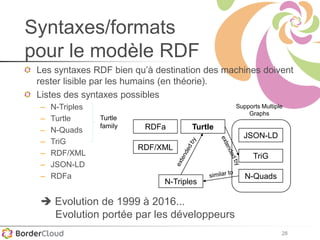











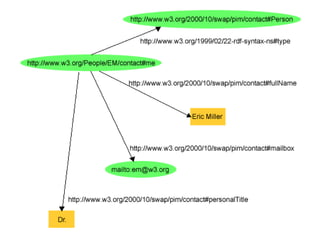
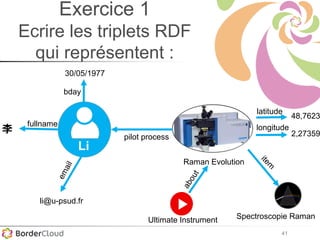


























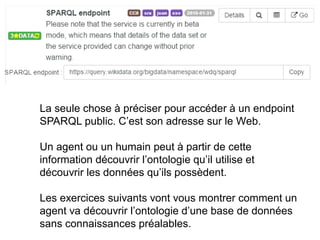




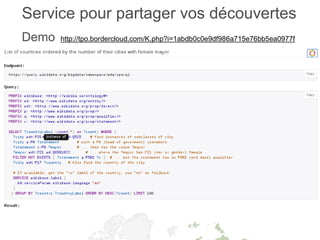



















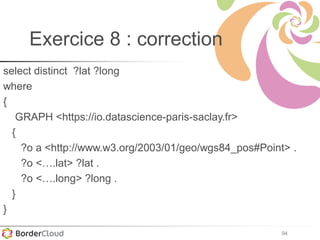






Le document présente un atelier sur SPARQL et le web sémantique animé par Karima Rafes, fondatrice de BorderCloud, qui offre des services de formation et de conseil en gestion des données. Il détaille également les compétences nécessaires pour les administrateurs de systèmes d'information et les différentes syntaxes utilisées pour le modèle RDF. En outre, plusieurs concepts essentiels comme les triplets RDF, les IRI et les formats de déclarations en RDF sont abordés pour faciliter la compréhension et l'interopérabilité des données.






![[Oracle DBA & Developer Day 2016] しばちょう先生の特別講義!!ストレージ管理のベストプラクティス ~ASMからExada...](https://cdn.slidesharecdn.com/ss_thumbnails/mktgdd2-3stragemanagementfordl2-200702092359-thumbnail.jpg?width=640&height=640&fit=bounds)








































