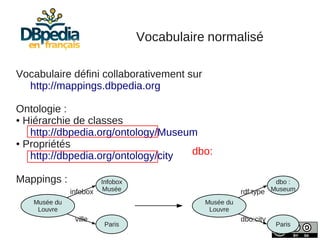
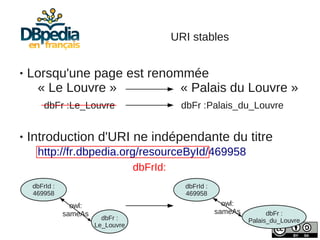
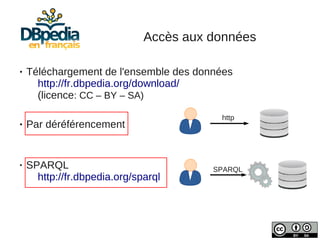
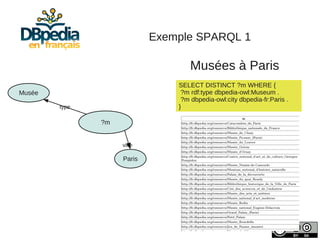
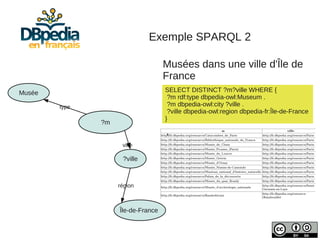
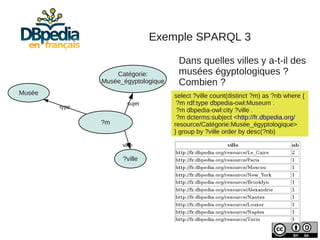
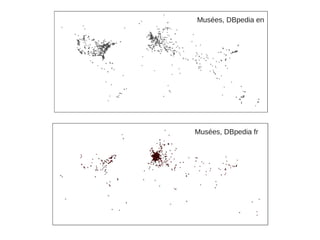
Julien Cojan, membre de l'équipe Wimmics à Inria, traite de l'extraction de données depuis Wikipédia, notamment pour le musée du Louvre. Le document aborde les défis liés à l'extraction textuelle, les normes de vocabulaire, ainsi que l'utilisation de l'ontologie DBpedia pour structurer ces données. Il présente également des exemples d'interrogations des données via SPARQL et l'accès à un large volume de données extraites.





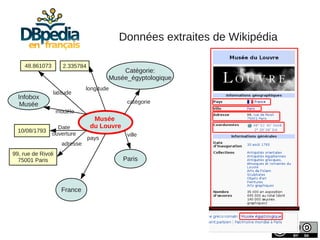
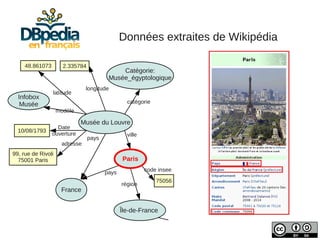
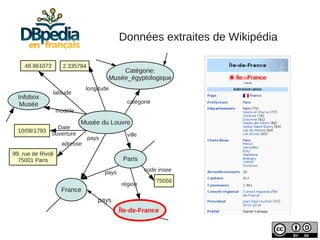
![Nommage des ressources
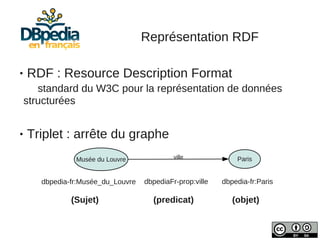
Sujet des articles de DBpedia :
Musée du Louvre
http://fr.dbpedia.org/resource/[Nom_Page]
dbFr:
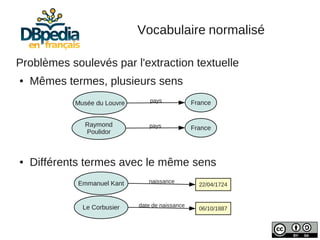
Propriétés extraites textuellement :
pays http://fr.dbpedia.org/property/[propriété]
dbFr-prop:](https://image.slidesharecdn.com/slides-dbpedia-121122034343-phpapp01/85/DBpedia-en-francais-8-320.jpg)