Télécharger en tant que PDF, PPTX












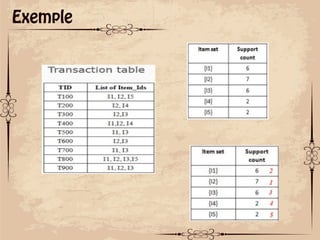
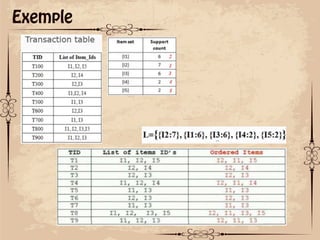
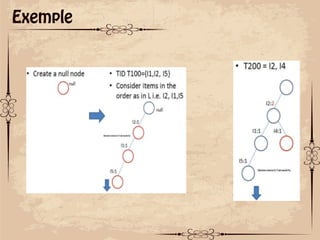
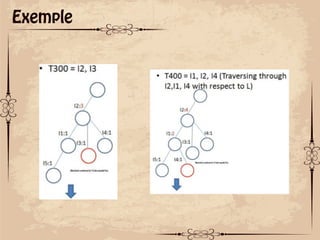
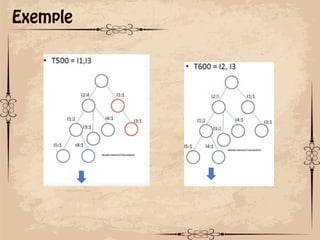
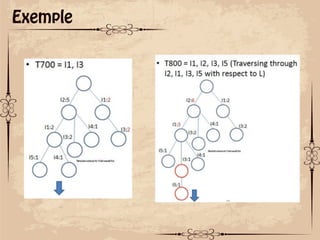
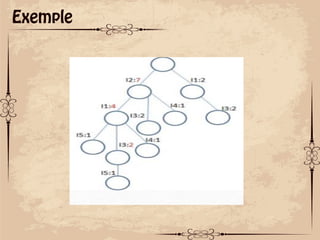





Le document présente des techniques de fouille de données, notamment l'algorithme Apriori et FP-Growth, pour identifier des motifs fréquents dans des ensembles de données. L'algorithme Apriori génère des itemsets candidats en utilisant des éléments fréquents, tandis que FP-Growth utilise une structure d'arbre compacte pour éviter des parcours répétitifs de la base de données. Ces méthodes ont des applications variées, notamment dans l'analyse de données de paniers et le marketing croisé.



























