Télécharger en tant que PDF, PPTX




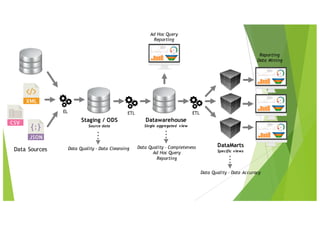
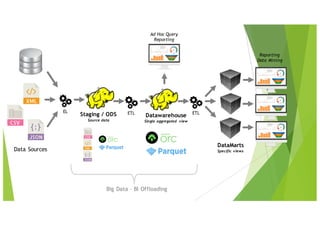
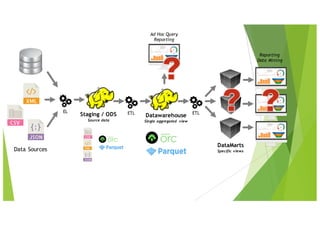
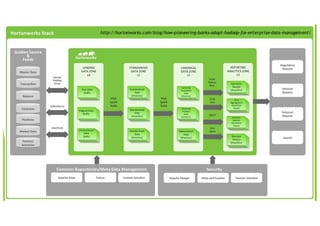







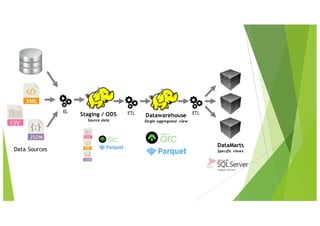



Le document traite des applications pratiques de la Business Intelligence (BI) et du Big Data, en se concentrant sur la gestion des données et les défis rencontrés avec l'intégration de différentes technologies. Il aborde divers aspects techniques tels que l'ETL, la qualité des données, la compatibilité des drivers ODBC, et les performances des outils analytiques face à des volumes de données importants. Les limitations de certaines solutions, ainsi que des recommandations pour des outils spécifiques, sont également discutées.




![[JSS2015] Azure SQL Data Warehouse - Azure Data Lake](https://cdn.slidesharecdn.com/ss_thumbnails/jss2015-sqldwh-adl-151211085004-thumbnail.jpg?width=640&height=640&fit=bounds)



















![[HUBFORUM] DATAWORDS - SOCIAL MEDIA & CULTURES LOCALES](https://cdn.slidesharecdn.com/ss_thumbnails/plenierehubforum20151001-151008094716-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)






















