Télécharger pour lire hors ligne



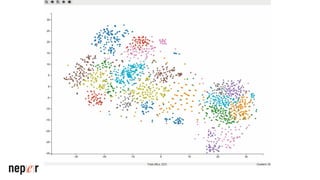




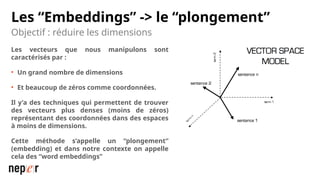
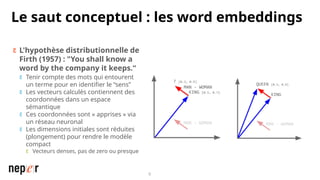
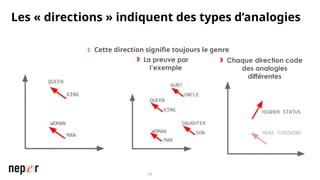
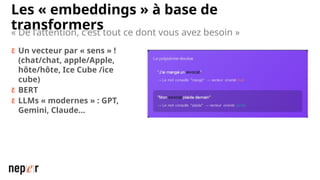


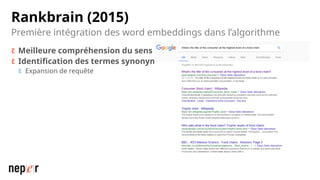

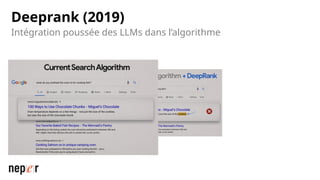
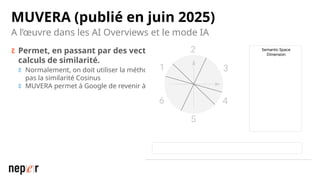




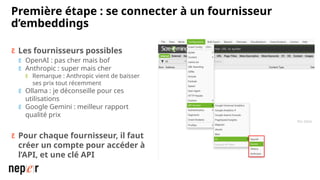
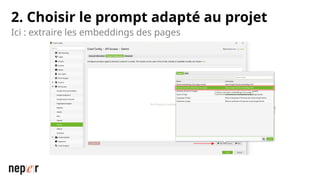
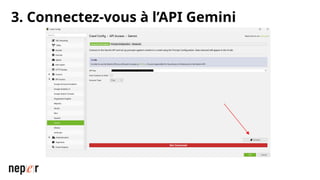
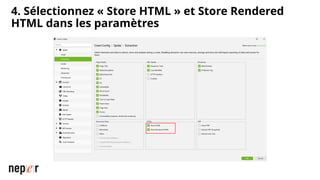

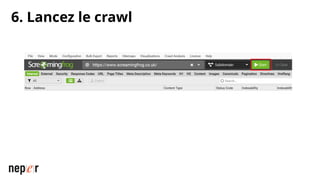
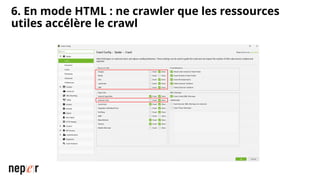
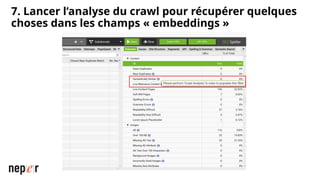
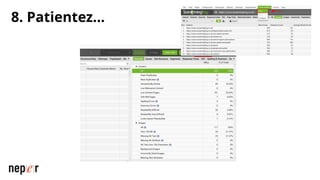
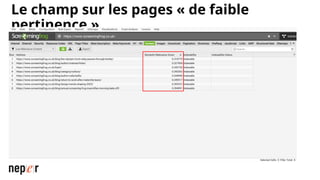


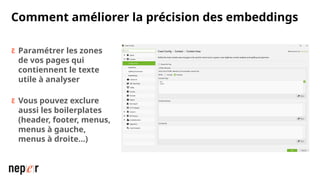



On parle beaucoup de GEO, mais une bonne compréhension des LLMs permet aussi d'améliorer considérablement l'efficacité et la précision de ce que l'on peut faire avec des modèles de langue de dernière génération. Voici un cas d'usage avec Screaming Frog





































