Télécharger pour lire hors ligne







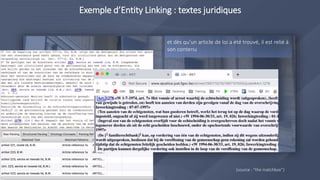




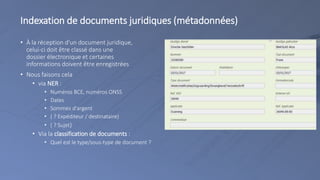


La reconnaissance d'entités nommées (NER) identifie et classe des entités précises dans des textes non structurés, utilisant des approches basées sur des règles ou des méthodes statistiques. Elle permet également l'entity linking, reliant les entités reconnues à d'autres données pour enrichir l'information, et pose des défis en matière d'adaptation au domaine et de désambiguïsation. La classification de documents juridiques utilise NER et techniques d'apprentissage automatique pour organiser efficacement les informations dans des dossiers électroniques.



























