Télécharger pour lire hors ligne













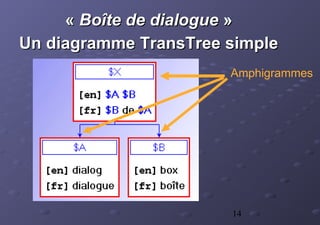









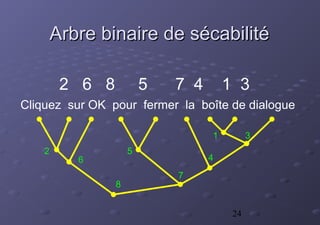



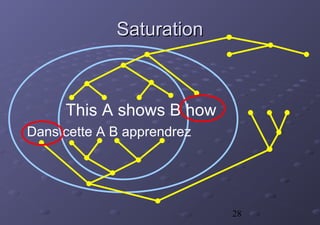




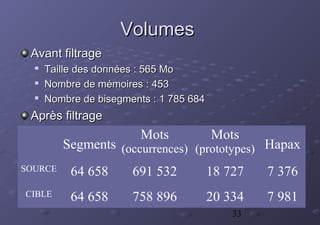








La thèse de Christophe Chenon présente un modèle d'alignement sous-phrastique pour améliorer l'utilisabilité des mémoires de traduction en se basant sur des segments traduits. Le système, destiné aux traducteurs, intègre la réutilisation des traductions précédentes afin d'accroître la cohérence et la productivité. Un cadre statistique et des méthodes algorithmiques sont également proposés pour l'acquisition et l'application des données de traduction.


























