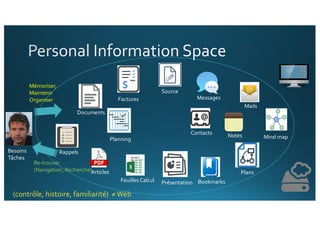
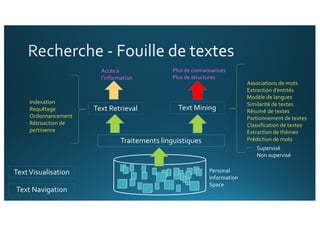
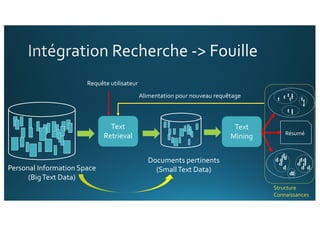
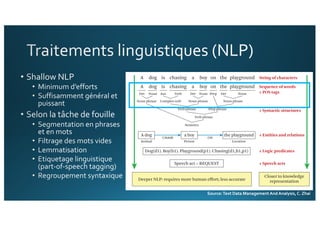
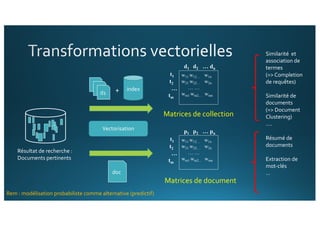
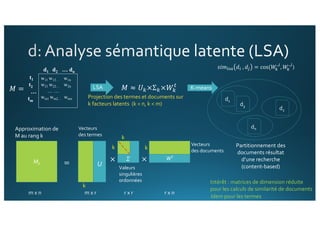
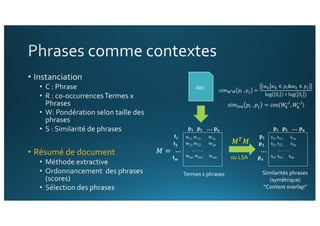
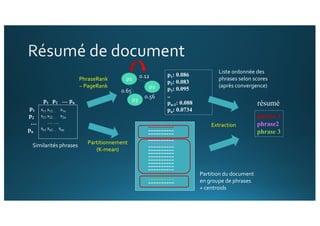
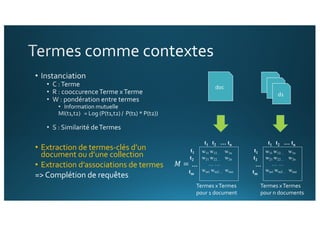
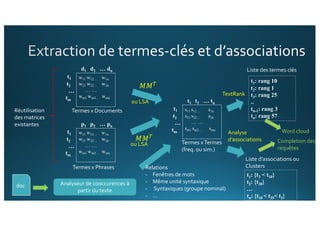
Le document traite de l'intégration de Big Data et de l'apprentissage automatique pour améliorer la recherche de documents, en explorant des techniques de traitement du langage naturel comme l'extraction d'entités et le résumé de textes. Il présente des méthodes pour indexer, requêter et visualiser des données textuelles, tout en analysant les relations entre mots et concepts pour optimiser la pertinence des résultats. Des approches de modélisation sémantique et de fouille de texte sont également discutées pour faciliter la prise de décision et l'accès à l'information.