Télécharger en tant que PDF, PPTX














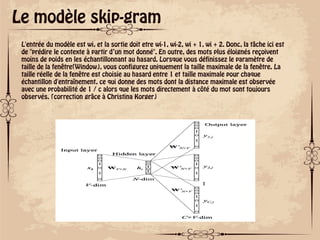



Le document traite des concepts fondamentaux du traitement du langage naturel (NLP), explorant des domaines tels que la compréhension du langage naturel (NLU) et la génération de langage naturel (NLG). Il retrace l'histoire du NLP depuis les premiers traducteurs automatiques jusqu'à l'essor des algorithmes d'apprentissage automatique, tout en abordant des techniques comme le modèle d'espace vectoriel et le TF-IDF pour la pondération des termes. Il souligne également les défis liés à l'ambiguïté linguistique et présente des méthodes modernes comme le word embedding et la bibliothèque Python Gensim pour l'extraction sémantique.






































