Télécharger en tant que PDF, PPTX


















![Skip-gram Paramètres
52J. DABOUNOU - FST DE SETTAT
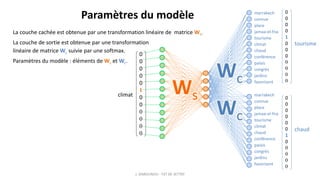
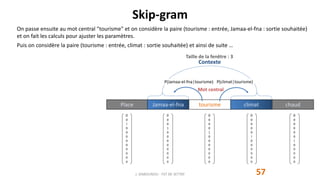
Ws
t = [v1, v2, … , vV] et Wc
t = [u1, u2, … , uV] et = {v1, v2, … , vV, u1, u2, … , uV} constitue l'ensemble des paramètres du
modèle.
Pour k=1,V on a vk est le vecteur qui représente le mot wk dans l'espace des sens et uk est le vecteur qui représente le
mot wk dans l'espace des contextes.
1.1 0.5 0.2 -0.2 0.3
0.4 0.6 -1.0 -1.1 -0.3
0.8 -0.2 0.3 -0.5 -0.3
0.8 0.2 -0.1 -1.0 0.1
-0.2 -0.3 -0.2 -0.5 -0.5
0.1 -1.1 -0.3 -1.0 0.1
-0.6 0.2 -0.1 -0.9 -0.3
-0.2 0.2 0.2 0.7 -0.3
0.1 0.1 -1.1 0.1 0.8
0.3 -0.2 0.7 0.6 0.1
0.1 0.2 0.7 0.6 0.3
-0.2 1.0 -0.3 0.7 -1.1
-0.2 0.1 -1.1 0.3 0.1
-0.3 -0.7 -1.0 0.4 0.7
0.1 -1.1 0.1 0.8 0.2
0.1 0.7 0.2 0.7 -1.0
0.2 0.7 -1.1 -0.3 0.3
-0.8 -0.2 0.3 0.4 0.5
0.1 -1.1 -0.3 -1.0 0.1
-0.5 -0.3 -0.7 -0.5 -0.5
0.4 -0.3 -0.2 -0.7 0.1
-1.0 0.1 0.8 0.2 0.7
0.1 0.2 0.7 -1.1 -0.3
0.7 0.1 0.2 0.7 0.2
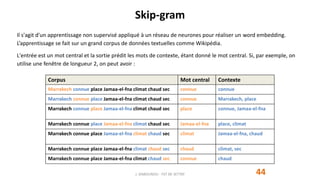
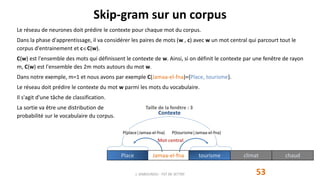
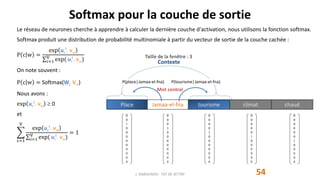
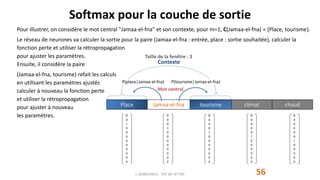
marrakech
connue
place
jamaa-el-fna
tourisme
climat
chaud
conférence
palais
congrès
jardins
favorisent
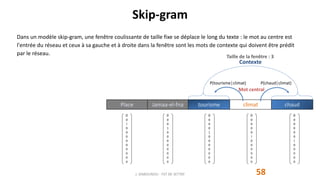
marrakech
connue
place
jamaa-el-fna
tourisme
climat
chaud
conférence
palais
congrès
jardins
favorisent
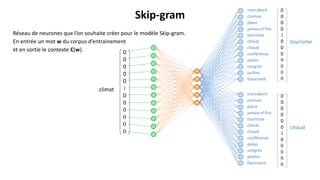
Espace des sens Espace des contextes
v6 = vclimat =
0.1
-1.1
-0.3
-1.0
0.1
u5 = utourisme =
0.2
0.7
-1.1
-0.3
0.3
v7 = vchaud =
-0.6
0.2
-0.1
-0.9
-0.3
u6 = uclimat =
-0.8
-0.2
0.3
0.4
0.5
u7 = uchaud =
0.1
-1.1
-0.3
-1.0
0.1
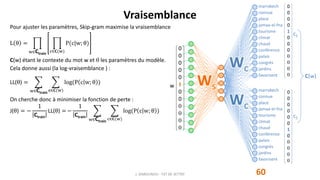
Le produit scalaire : uchaud
t
. vclimat caractérise la similarité entre les vecteurs uchaud et vclimat. Globalement, plus il est positif
et grand, plus cela signifie que cos(uchaud
t
, vclimat) est proche de 1, et donc que les vecteurs "vont dans le même sens".
Le modèle va être entrainé pour maximiser le produit scalaire uc
t
. vw lorsque le mot c apparait dans le contexte du mot w.](https://image.slidesharecdn.com/w2vec001-201214192003/85/W2-vec001-23-320.jpg)




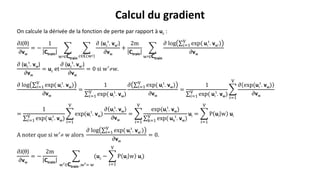






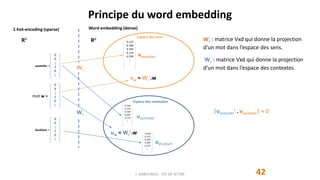
Le document présente le concept de word embedding en traitement automatique du langage naturel, en détaillant les méthodes comme le one hot encoding et l'algorithme word2vec. Il explique comment ces techniques génèrent des représentations vectorielles des mots, permettant de capturer les relations sémantiques et d'effectuer des opérations arithmétiques sur ces vecteurs. De plus, il aborde la notion d'hypothèse distributionnelle et l'utilisation de ces vecteurs dans diverses tâches de traitement de texte.

















































