Téléchargé 16 fois










![Composantes principales
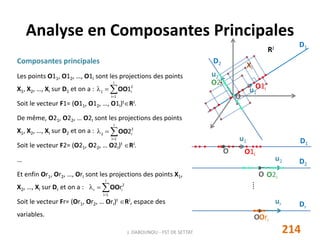
Les vecteurs F1, F2,…, Fr sont appelés composantes
principales. On a
F1 = X u1, F2 = X u2, …, Fr = X ur.
La matrice X peut être remplacée, dans la base orthonormée
(u1, u2, …, ur) par la matrice de composantes principales
C = [ F1 F2 … Fr ]
Ce qui permet de réduire la dimension des données puisque
rJ sans perte d’information (Inertie globale).
En effet:
trace(XtX) = 1 + 2 +…+ r = u1
tXtXu1 + u2
tXtXu2 + …+ ur
tXtXur
= F1t F1 + F2t F2 + …+ Frt Fr = trace(Ct C)
Analyse en Composantes Principales
215J. DABOUNOU - FST DE SETTAT
D1
O O1i
u1
O2i
Ori
O
RJ
u1
Xi
O1i
D1
u2
O2i
D2
D2
u2
O
Dr
ur
O
⁞](https://image.slidesharecdn.com/analysedonneescollegues-190329072742/85/Analyse-en-Composantes-Principales-16-320.jpg)
![Analyse en Composantes Principales
216J. DABOUNOU - FST DE SETTAT
D1
O O1i
u1
O2i
Ori
D2
u2
O
Dr
ur
O
⁞
Réduction de la dimensionnalité
Il arrive souvent que pour s très inférieur au rang r on ait :
Cela exprime le fait qu’à partir de s << r la variance des composantes principales (ou, autrement dit
les valeurs propres) devient négligeable (voir figure ci-dessous).
Dans ce cas La matrice X peut être remplacée, sans risque de perte d’information significative, par la
matrice C = [ F1 F2 … Fs ] dans le sous-espace engendré par la famille orthonormée (u1, u2, …, us).
Ce qui permet de réduire la dimension des données puisque s << r J.
1
...
...
r21
s21
Dans le contexte du machine learning, la contribution
des composantes principales de faible variance est
souvent considérée comme un bruit. Le fait de les
négliger améliore l’apprentissage en réduisant le risque
d’overfitting (surappretissage).](https://image.slidesharecdn.com/analysedonneescollegues-190329072742/85/Analyse-en-Composantes-Principales-17-320.jpg)




L'analyse en composantes principales (ACP) est une méthode d'analyse de données introduite par Karl Pearson pour réduire la dimensionnalité et améliorer la performance des algorithmes d'apprentissage automatique. Elle permet de résumer des variables en composantes synthétiques tout en préservant l'information pertinente, facilitant ainsi leur interprétation et visualisation. L'ACP repose sur l'optimisation de l'inertie expliquée par les projections des données dans un espace de moindre dimension.























































