Télécharger en tant que PDF, PPTX


























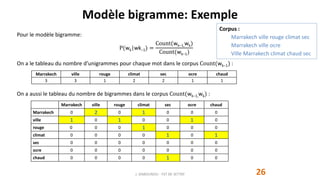















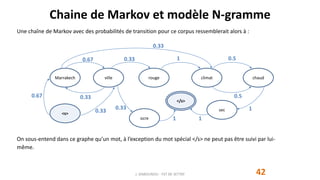



















Le document traite du traitement automatique du langage naturel (TALN) et présente les modèles de langue, incluant leurs applications dans la traduction, la correction d'erreur et l'analyse de sentiments. Il explique également comment ces modèles sont construits à partir de corpus textuels et l'importance des probabilités conditionnelles dans leur conception. Enfin, il aborde la notion d'espace sémantique et la manière dont les machines peuvent comprendre le langage à travers l'analyse des régularités linguistiques.











































