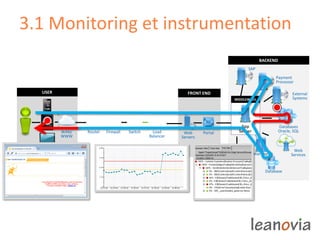
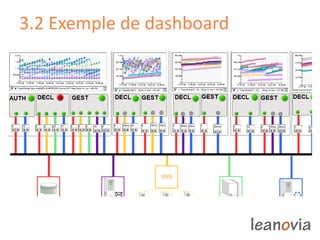
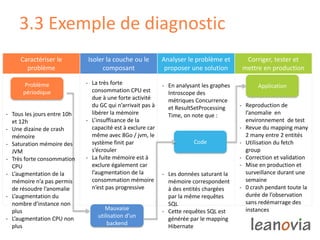
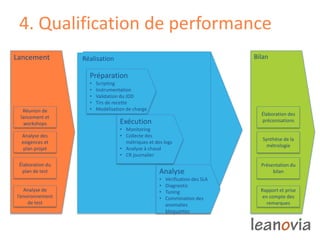
Le document présente la gestion de la performance des applications, abordant des problèmes comme la disponibilité, la rapidité et la scalabilité, ainsi que des solutions telles que le monitoring end-to-end et des infrastructures adaptées. Des exemples de diagnostic et des préoccupations de performance sont discutés, illustrant l'importance de l'analyse et de la correction des problèmes en production. Enfin, il souligne que la performance est un enjeu complexe pour les décideurs IT et introduit les opportunités de recrutement au sein de Leanovia Consulting.






































![cours raspberry [Enregistrement automatique].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/coursraspberryenregistrementautomatique-260206145736-b1015531-thumbnail.jpg?width=640&height=640&fit=bounds)



