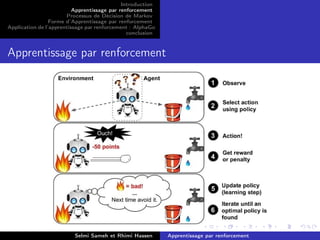
Ce document traite de l'apprentissage par renforcement (AR) et de son application au travers de l'exemple d'Alphago. Il explique les concepts fondamentaux de l'AR tels que les processus de décision markoviens, les différentes formes d'apprentissage (passif et actif), ainsi que les techniques employées pour maximiser les récompenses. Enfin, il souligne l'importance de l'équilibre entre exploration et exploitation dans le cadre de l'apprentissage autonome de systèmes intelligents.