Ce document présente les interfaces fonctionnelles introduites par Java 8, incluant les méthodes par défaut, les lambda expressions et les références de méthode. L'étude aborde leurs rôles dans la programmation fonctionnelle, ainsi que leur utilisation pour rendre le code plus concis et lisible. Des exemples illustrent l'application de ces concepts et la création d'interfaces fonctionnelles à l'aide de lambda expressions.







![Méthode par défaut : syntaxe (1)
• Pour déclarer une méthode par défaut, il suffit de faire
précéder son nom par « default » et d’en fournir une
implémentation dans l’interface.
Syntaxe :
default typeRetour nomMethode([arguments]) {
Corps
}
Exemples :
• public default boolean check(String x) { … }
• public default int addition(int a, int b) { ... }
datascience.km@gmail.comM. MICHRAFY 8](https://image.slidesharecdn.com/java8interfacefonctionlambdaexpression-160125221542/85/Interface-fonctionnelle-Lambda-expression-methode-par-defaut-reference-de-methode-avec-des-exemples-8-320.jpg)
![Méthode par défaut : syntaxe (2)
// déclaration d une interface avec méthode par défaut
public Interface nomInterface {
public default valeurRetour nomMethodeParDefaut ([arguments]){ // traitement }
public valeurRetour nomMethode([arguments])
}
// Exemple d’une interfaceavec une méthode par défaut
public interface OperationMath {
// signaturede la méthode operation avec une implémentation par défaut
public default boolean operation(intx, int y){ return x+y; }
}
datascience.km@gmail.comM. MICHRAFY 9](https://image.slidesharecdn.com/java8interfacefonctionlambdaexpression-160125221542/85/Interface-fonctionnelle-Lambda-expression-methode-par-defaut-reference-de-methode-avec-des-exemples-9-320.jpg)
![Méthode par défaut : utilisation
// déclarationd’une classeA utilisantla méthode par défaut
public classA implements OperationMath{ }
// déclaration d’une classe A qui surcharge la méthode check de l’interface A
public class B implements OperationMath{
public default int operation(nt x, int y){ return x-y ;} // soustraction
}
public static void main(String[] args) { // Appel dans une fonctionmain
A a = new A(); A b = new B(); // créationdes instances de A et B
a.operation(21, 11) ; // appel de la méthode par défaut déclarée dans OperationMath
b.operation(21,11) ; // appel le la méthode de la classe B
}
datascience.km@gmail.comM. MICHRAFY
public interface OperationMath {
// signaturede la méthode operation avec une implémentation par défaut
public default boolean operation(intx, int y){ return x+y; } // addition
}
10](https://image.slidesharecdn.com/java8interfacefonctionlambdaexpression-160125221542/85/Interface-fonctionnelle-Lambda-expression-methode-par-defaut-reference-de-methode-avec-des-exemples-10-320.jpg)

![Méthode par défaut : utilisation
public interface A { public defaultboolean check(String x){ return (x!=null && !x.isEmpty()) ; }}
public interface B extends A{ }
public interface C extends A {
public default boolean check(Stringx){
return (x!=null && !x.isEmpty()) && x.matches("[0-9]{5}"); }}
public interface D extends A { public abstract boolean check(String x); }
L’interface D ne dispose pas de méthode par défaut
L’interface C a redéfinit la méthode par défaut
L’interface B a la méthode par défaut celle qui est dans l’interface A
datascience.km@gmail.comM. MICHRAFY 12](https://image.slidesharecdn.com/java8interfacefonctionlambdaexpression-160125221542/85/Interface-fonctionnelle-Lambda-expression-methode-par-defaut-reference-de-methode-avec-des-exemples-12-320.jpg)




![Interface fonctionnelle : Déclaration
public interface NomInterface {
public valeurRetour nomMethode([Arguments]);
}
// Exemple1 d’une déclarationd’une interface fonctionnelle
public interface OperationCheck{
// signaturede la méthode check l interfacefonctionnelleOperationCheck
public boolean check(Stringa);
}
// Exemple2 d’une déclarationd’une interface fonctionnelle
public interface OperationMath {
// signaturede la méthode operation de l interface fonctionnelleOperationMath
public int operation(inta, int b);
}
datascience.km@gmail.comM. MICHRAFY 17](https://image.slidesharecdn.com/java8interfacefonctionlambdaexpression-160125221542/85/Interface-fonctionnelle-Lambda-expression-methode-par-defaut-reference-de-methode-avec-des-exemples-17-320.jpg)
![Lambda expression (1)
• Les lambda expressions permettent d’instancier les interfaces
fonctionnelles, c.-à-d. de leur fournir une implémentation.
• La déclaration d’une lambda expression nécessite de préciser
l’interface fonctionnelle associée.
• Les arguments d’entrée et la valeur de retour de la lambda
expression doivent respecter la signature de la méthode de l’interface
fonctionnelle associée.
• Le symbole « -> » sépare les arguments d’entrée et le corps du
traitement proposé par la lambda expression.
Syntaxe :
NomInterface nomLambdaExpression = ([arguments]) -> {
// traitement
};
datascience.km@gmail.comM. MICHRAFY 18](https://image.slidesharecdn.com/java8interfacefonctionlambdaexpression-160125221542/85/Interface-fonctionnelle-Lambda-expression-methode-par-defaut-reference-de-methode-avec-des-exemples-18-320.jpg)
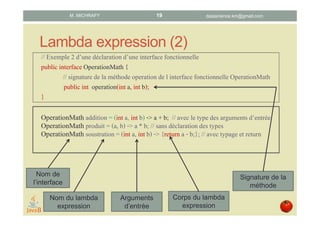
![Lambda expression : exemple
public interface OperationMath {// déclaration d’une interface fonctionnelle
public int operation(int a, int b); // la méthode à implémenter
}
public static void main(String[] args) {
A pf = new A();
OperationMath addition = (int a, int b) -> a + b;
OperationMath produit = (a, b) -> a * b;
int s = pf.apply(a, b, addition); // utilisation du lambda expression addition
int p = pf.apply(a, b, produit); // utilisation du lambda expression produit
}
public class A {// appliquer prend en un entrée l’interface fonctionnelle OperationMath
public int apply(int a, int b, OperationMath op){ return op.operation(a,b); }}
datascience.km@gmail.comM. MICHRAFY 20](https://image.slidesharecdn.com/java8interfacefonctionlambdaexpression-160125221542/85/Interface-fonctionnelle-Lambda-expression-methode-par-defaut-reference-de-methode-avec-des-exemples-20-320.jpg)

![Interface fonctionnelle : fonction d’ordre
supérieur (2)
public interface PolynomePD {
public abstract double donnerY(double x);
}
public interface FabriquePolynomePremierDegre {
public abstract PolynomePD donnerPolynome(double a, double b);
}
public static void main(String[] args) {
FabriquePolynomePremierDegre fppd = (a,b) -> {return (x) -> a*x+b;};
FabriquePolynomePremierDegre fppd1 = (a,b) -> ((x) -> (a*x+b));
PolynomePD p1 = fppd.donnerPolynome(1,1);
PolynomePD p2 = fppd.donnerPolynome(2,5);
double x = 1;
double p1_x = p1.donnerY(x); // retourne 2
double p2_x = p2.donnerY(x); // retourne 7
}
Fonction en valeur de retour
Interface fonctionnelle
2 façons de déclarer
une fonction en valeur
de retour
Construire 2 polynômes :
P1(x) : x + 1
P2(x) : 2x + 5
datascience.km@gmail.comM. MICHRAFY 22](https://image.slidesharecdn.com/java8interfacefonctionlambdaexpression-160125221542/85/Interface-fonctionnelle-Lambda-expression-methode-par-defaut-reference-de-methode-avec-des-exemples-22-320.jpg)
![Interface fonctionnelle : fonction composée
public interface ComposeFonction {
public PolynomePD compose(PolynomePD x, PolynomePD y);
}
public static void main(String[] args) {
FabriquePolynomePremierDegre fppd = (a,b) -> {return (x) -> a*x+b;};
PolynomePD p1 = fppd.donnerPolynome(1,1);
PolynomePD p2 = fppd.donnerPolynome(2,5);
// cf est le composé de f et g
ComposeFonction cf = (f,g) -> ((x)->(f.donnerY(g.donnerY(x))));
double x=1;
// calculer p1op2(x) et cf(p1,p2)(x) et comparer
double p2_x=p2.donnerY(x),p1p2x = p1.donnerY(p2_x);
double cf_x = cf.compose(p1, p2).donnerY(x);
System.out.println("p1p2x = " + p1p2x + " | cf_x = " + cf_x);
} // sortie : p1p2x = 8.0 | cf_x = 8.0
2 fonctions en entréeretour est une fonction
Expression de la
fonction composée
Appel de la fonction
composé, passage
deux fonctions
datascience.km@gmail.comM. MICHRAFY 23](https://image.slidesharecdn.com/java8interfacefonctionlambdaexpression-160125221542/85/Interface-fonctionnelle-Lambda-expression-methode-par-defaut-reference-de-methode-avec-des-exemples-23-320.jpg)




![Interface Functionnelle Function (3)
public class MainFunction {
public static void main(String[] args) {
Function<String, String> toUpper = (x) -> (x.toUpperCase());
Function<String, String> after = (x) -> (x.split("-")[0]);
Function<String, String> before = (x) -> (x.split("-")[1]);
String nomC = "Dupond-Pascal";
String nomC_format = toUpper.apply(nomC); // renvoie DUPOND-PASCAL
String nom = toUpper.andThen(after).apply(nomComplet); // renvoie DUPOND
String prenom = toUpper.compose(before).apply(nomComplet); // renvoie PASCAL
} Appel à apply de toUpper
Appel à la fonction andThen pour toUpper o after
Appel à la fonction compose before o toUpper
3 interfaces Function
datascience.km@gmail.comM. MICHRAFY 28](https://image.slidesharecdn.com/java8interfacefonctionlambdaexpression-160125221542/85/Interface-fonctionnelle-Lambda-expression-methode-par-defaut-reference-de-methode-avec-des-exemples-28-320.jpg)


![Interface fonctionnelle Predicate (3)
public static void main(String[] args) {
Predicate<String> isNull = (x) -> (x!=null);
Predicate<String> isEmpty = (x) -> (x.isEmpty()==false);
Predicate<String> isCP = (x) -> (x.matches("[0-9]{5}"));
// fonctions sont composées à partir de deux predicats
Predicate<String> isNullAndEmpty = isNull.and(isEmpty);
Predicate<String> isCPValide = isNullAndEmpty.and(isCP);
String x = "75", y="75009";
boolean rx= isNullAndEmpty.test(x);
boolean ry = isCPValide.test(y);
System.out.println("rx = " + rx + " | ry = " + ry); // retourne rx = true | ry = true
}
Création d’un nouveau prédicat en utilisant And pour les
prédicats isNull , isEmpty
Appel à la méthode test des deux prédicats
datascience.km@gmail.comM. MICHRAFY 31](https://image.slidesharecdn.com/java8interfacefonctionlambdaexpression-160125221542/85/Interface-fonctionnelle-Lambda-expression-methode-par-defaut-reference-de-methode-avec-des-exemples-31-320.jpg)


![Interface fonctionnelle : Consumer (3)
public class Climat {
double temp, lon, lat;
public Climat(double temp, double lon, double lat) {
super();
this.temp = temp; this.lon = lon; this.lat = lat;
}
public String toTemperature(){return "Climat [temp=" + temp + "]";}
public String toLonLat() {return "Climat [lon=" + lon + ", lat=" + lat + "]";}
}
public static void main(String[] args) {
Consumer<Climat> toTemp = (x) -> System.out.println(x.toTemperature());
Consumer<Climat> toXY = (x) -> System.out.println(x.toLonLat());
Consumer<Climat> toTempXY = toTemp.andThen(toXY);
Climat climat = new Climat(18, 2.3488000, 48.8534100);
toTemp.accept(climat); // Climat [temp=18.0]
toXY.accept(climat); // Climat [lon=2.3488, lat=48.85341]
toTempXY.accept(climat); // affiche les résultats donnés par toTemp et toXY
}
Deux consumers
Consumer composé à l’aide de andThen
Appel des 3 consumers
datascience.km@gmail.comM. MICHRAFY 34](https://image.slidesharecdn.com/java8interfacefonctionlambdaexpression-160125221542/85/Interface-fonctionnelle-Lambda-expression-methode-par-defaut-reference-de-methode-avec-des-exemples-34-320.jpg)


![Référence vers une méthode d’instance
interface Distancier { public double distance (Mesure m1, Mesure m2 ) ; }
classMesure{
private double x;
public Mesure (double x){ this.x = x }
public double distance1(Mesure m) { return this.x - m.x; }
public double distance2(Mesure m) { return Math.abs(this.x- m.x) ; }
}
public staticvoid main (String [] args){
Mesure m1 = new Mesure(12), m2 = new Mesure(25) ;
Distancier d1 = Mesure::distance1; // référence vers la méthode distance1
Distancier d2 = Mesure::distance2; // référence vers la méthode distance2
System.out.println("distance1 entre m1 et m2 = " + d1.distance(m1, m2)) ;
System.out.println("distance2 entre m1 et m2 = " + d2.distance(m1, m2)) ;
}
Méthode d’interface
Méthodes d’instance
Références vers des méthodes d’instance
datascience.km@gmail.comM. MICHRAFY 37](https://image.slidesharecdn.com/java8interfacefonctionlambdaexpression-160125221542/85/Interface-fonctionnelle-Lambda-expression-methode-par-defaut-reference-de-methode-avec-des-exemples-37-320.jpg)
![Référence vers un constructeur
interface Fabrique<T> { public T getInstance(double x); }
classMesure{
private double x;
public Mesure (double x){ this.x = x }
public String toString() { return "Mesure [x=" + x + "]"; }
}
public staticvoid main (String [] args){
Fabrique<Mesure> fm = Mesure::new;
Mesure m = fm.getInstance(17);
System.out.println ("dm = " + d1.toString();
}
Méthode d’interface
Constructeur
Référence vers un constructeur
datascience.km@gmail.comM. MICHRAFY 38](https://image.slidesharecdn.com/java8interfacefonctionlambdaexpression-160125221542/85/Interface-fonctionnelle-Lambda-expression-methode-par-defaut-reference-de-methode-avec-des-exemples-38-320.jpg)
![Référence vers une méthode statique
interface ICompteur { public T getCompteur(); }
classMesure{
private int compteur=0;
private double x;
public Mesure (double x){ this.x = x; compteur++;}
public staticint getNbInstance(){ return compteur; }
}
public static void main (String [] args){
ICompteur compt = Mesure::getNbInstance ;
Mesure m1 = new Mesure(3), m2=new Mesure(7);
System.out.println ("nombre d instance = " + compt.getCompteur()) ;
}
Méthode d’interface
Méthode statique
Référence vers une méthode statique
datascience.km@gmail.comM. MICHRAFY 39](https://image.slidesharecdn.com/java8interfacefonctionlambdaexpression-160125221542/85/Interface-fonctionnelle-Lambda-expression-methode-par-defaut-reference-de-methode-avec-des-exemples-39-320.jpg)