Téléchargé 29 fois









 restrict(amp)
{ {
pC[i] = pA[i] + pB[i]; c[i] = = pA[i] + pB[i];
pC[i] a[i] + b[i];
} }
);
} }
Fondamentaux](https://image.slidesharecdn.com/lan401-130416042426-phpapp01/85/La-programmation-GPU-avec-C-AMP-pour-les-performances-extremes-10-320.jpg)
 restrict(amp)
pour exécuter {
l’expression lambda c[i] = a[i] + b[i];
}
); Les variables array_view sont
capturées par valeur et leurs
index: le thread ID qui exécute l’expression
} données associées sont copiées
lambda, est utilisé pour retrouver les données
dans l’accélérateur à la demande
Fondamentaux](https://image.slidesharecdn.com/lan401-130416042426-phpapp01/85/La-programmation-GPU-avec-C-AMP-pour-les-performances-extremes-11-320.jpg)
 restrict(amp)
c[1] = a[1] + b[1]
c[0] = a[0] + b[0]
c[2] = a[2] + b[2]
c[3] = a[3] + b[3]
c[4] = a[4] + b[4]
c[5] = a[5] + b[5]
c[6] = a[6] + b[6]
c[7] = a[7] + b[7]
{
Code noyau
c[idx] = a[idx] + b[idx];
}
);
}
0 1 2 3 4 5 6 7
Fondamentaux](https://image.slidesharecdn.com/lan401-130416042426-phpapp01/85/La-programmation-GPU-avec-C-AMP-pour-les-performances-extremes-12-320.jpg)


 restrict(amp)
{
//…
double d0 = c[idx];
double d1 = bar(d0); // ok, bar supporte amp aussi
double d2 = cos(d0); // ok, sélection de la surcharge amp
//…
});
}
Fondamentaux](https://image.slidesharecdn.com/lan401-130416042426-phpapp01/85/La-programmation-GPU-avec-C-AMP-pour-les-performances-extremes-15-320.jpg)

![Le conteneur: array_view<T, N>
• Vue sur les données stockées dans la mémoire CPU ou
la mémoire GPU
• Capture par valeur [=] dans l’expression lambda
• De type T et de rang N
• Réclame un extent
vector<int> v(10);
• Rectangulaire extent<2> e(2,5); array_view<int,2> a(e, v);
• Accès aux éléments déclenchent
• des copies implicites
index<2> i(3,9); // Les 2 lignes peuvent aussi s’écrire
// array_view<int,2> a(2,5,v);
int o = a[i]; // ou a[i] = 16;
// ou int o = a(3, 9);
Fondamentaux](https://image.slidesharecdn.com/lan401-130416042426-phpapp01/85/La-programmation-GPU-avec-C-AMP-pour-les-performances-extremes-17-320.jpg)
![Le second conteneur: array<T, N>
• Tableau multidimensionnel qui contient des éléments de type T de dimension N
• Les données sont stockées dans la mémoire de l'accélérateur
• Capture par référence [&] dans l’expression lambda
• Copie explicit
• Presque identique à l’interface array_view<T,N>
vector<int> v(8 * 12); parallel_for_each(e, [&](index<2> idx) restrict(amp)
extent<2> e(8,12); {
a[idx] += 1;
array<int,2> a(e); });
copy_async(v.begin(), v.end(), a); copy(a, v.begin());
Fondamentaux](https://image.slidesharecdn.com/lan401-130416042426-phpapp01/85/La-programmation-GPU-avec-C-AMP-pour-les-performances-extremes-18-320.jpg)


 restrict(amp) {
for (int col = 0; col < N; col++){ int row = idx[0]; int col = idx[1];
float sum = 0.0f; float sum = 0.0f;
for(int i = 0; i < W; i++) for(int i = 0; i < W; i++)
sum += vA[row * W + i] * vB[i * N + col]; sum += a(row, i) * b(i, col);
vC[row * N + col] = sum; c[idx] = sum;
} }
} );
} }
Fondamentaux](https://image.slidesharecdn.com/lan401-130416042426-phpapp01/85/La-programmation-GPU-avec-C-AMP-pour-les-performances-extremes-22-320.jpg)



![parallel_for_each: surcharge pour les tuiles
• Orchestrer des threads array_view<int,1> data(12, my_data);
dans des tuiles
– La version de base ne
le permet pas parallel_for_each(data.extent,
• parallel_for_each version [=] (index<1> idx) restrict(amp)
tuile accepte ces { … });
surcharges
– tiled_extent<D0> ou
tiled_extent<D0, D1> ou parallel_for_each(data.extent.tile<6>(),
tiled_extent<D0, D1, D2>
• L’expression lambda [=] (tiled_index<6> t_idx) restrict(amp)
accepte { … });
– tiled_index<D0> ou
tiled_index<D0, D1> ou
tiled_index<D0, D1, D2>
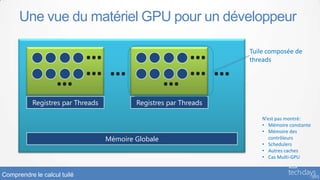
Comprendre le calcul tuilé](https://image.slidesharecdn.com/lan401-130416042426-phpapp01/85/La-programmation-GPU-avec-C-AMP-pour-les-performances-extremes-28-320.jpg)

![tiled_index
• Soit col 0 col 1 col 2 col 3 col 4 col 5
array_view<int,2> data(2, 6, p_my_data); row
parallel_for_each( 0
data.extent.tile<2,2>(),
[=] (tiled_index<2,2> t_idx)… { … });
row
1
T
• Lorsque la lambda est exécutée par T
– t_idx.global // index<2> (1,3)
– t_idx.local // index<2> (1,1)
– t_idx.tile // index<2> (0,1)
– t_idx.tile_origin // index<2> (0,2)
Comprendre le calcul tuilé](https://image.slidesharecdn.com/lan401-130416042426-phpapp01/85/La-programmation-GPU-avec-C-AMP-pour-les-performances-extremes-30-320.jpg)


 restrict(amp)
4 {
5 tile_static int t[TS][TS];
6 t[t_idx.local[0]][t_idx.local[1]] = av[t_idx.global];
7
8 if (t_idx.local == index<2>(0,0)) {
9 int temp = t[0][0] + t[0][1] + t[1][0] + t[1][1];
10 av[t_idx.tile_origin] = temp;
11 }
12 });
13 int sum = av(0,0) + av(0,2) + av(0,4); //the three tile_origins
Comprendre le calcul tuilé](https://image.slidesharecdn.com/lan401-130416042426-phpapp01/85/La-programmation-GPU-avec-C-AMP-pour-les-performances-extremes-33-320.jpg)
 restrict(amp)
4 {
5 tile_static int t[TS][TS];
6 t[t_idx.local[0]][t_idx.local[1]] = av[t_idx.global];
7
8 if (t_idx.local == index<2>(0,0)) {
9 int temp = t[0][0] + t[0][1] + t[1][0] + t[1][1];
10 av[t_idx.tile_origin] = temp;
11 }
12 });
13 int sum = av(0,0) + av(0,2) + av(0,4); //the three tile_origins
Comprendre le calcul tuilé](https://image.slidesharecdn.com/lan401-130416042426-phpapp01/85/La-programmation-GPU-avec-C-AMP-pour-les-performances-extremes-34-320.jpg)
 restrict(amp)
4 {
5 tile_static int t[TS][TS];
6 t[t_idx.local[0]][t_idx.local[1]] = av[t_idx.global];
7 tile_barrier.wait();
8 if (t_idx.local == index<2>(0,0)) {
9 int temp = t[0][0] + t[0][1] + t[1][0] + t[1][1];
10 av[t_idx.tile_origin] = temp;
11 }
12 });
13 int sum = av(0,0) + av(0,2) + av(0,4); //the three tile_origins
Comprendre le calcul tuilé](https://image.slidesharecdn.com/lan401-130416042426-phpapp01/85/La-programmation-GPU-avec-C-AMP-pour-les-performances-extremes-35-320.jpg)

![Multiplication Matricielle – Exemple (tuilée)
void MatrixMultSimple(vector<float>& vC, const vector<float>& vA, const void MatrixMultTiled(vector<float>& vC, const vector<float>& vA, const
void
vector<float>& vB, int M, int N, int W ) vector<float>& vB, int M, int N, W)
const vector<float>& vB, int M, int N, int W )
{ {
static const int TS = 16;
const int TS = 16;
array_view<const float,2> a(M, W, vA), b(W, N, vB); array_view<const float,2> a(M, W, vA), b(W, N, vB);
array_view<float,2> c(M,N,vC); c.discard_data(); array_view<float,2> c(M,N,vC); c.discard_data();
parallel_for_each(c.extent, parallel_for_each(c.extent.tile< TS, TS >(),
TS, TS >(),
[=] (index<2> idx) restrict(amp) { [=] (tiled_index<TS, TS> t_idx) restrict(amp) { {
(tiled_index< TS, TS> t_idx) restrict(amp)
int row = idx[0]; int col = idx[1]; int row = t_idx.local[0]; int col = t_idx.local[1];
t_idx.local[1];
float sum = 0.0f; float sum = 0.0f;
for (int i = 0; ii < W; ii += TS) {{
0; < W; += TS)
tile_static float locA[TS][TS], locB[TS][TS];
tile_static float locA[TS][TS], locB[TS][TS];
Phase 1
locA[row][col] = a(t_idx.global[0], col i);
locA[row][col]= a(t_idx.global[0], col ++ i);
locB[row][col] = b(row + i, t_idx.global[1]);
locB[row][col] = b(row + i, t_idx.global[1]);
t_idx.barrier.wait();
t_idx.barrier.wait();
for(int k = 0; k < W; k++) for (int k = 0; k < TS; k++)
Phase 2
sum += a(row, k) * b(k, col); sum += locA[row][k] * locB[k][col];
t_idx.barrier.wait();
t_idx.barrier.wait();
}
c[idx] = sum; c[t_idx.global] = sum;
c[t_idx.global] = sum;
} ); } );
} }
Techniques plus avancées: calcul tuilé](https://image.slidesharecdn.com/lan401-130416042426-phpapp01/85/La-programmation-GPU-avec-C-AMP-pour-les-performances-extremes-37-320.jpg)








Le document présente une introduction à la programmation GPU avec C++ AMP, mettant en avant ses bases et concepts avancés, y compris la gestion des données multidimensionnelles et le calcul tuilé. Il souligne les avantages de C++ AMP pour optimiser les performances sur divers dispositifs, notamment via des exemples de code. Enfin, il illustre comment C++ AMP s'intègre à l'écosystème Microsoft et promeut la démocratisation de la programmation GPU.










































































