Télécharger pour lire hors ligne




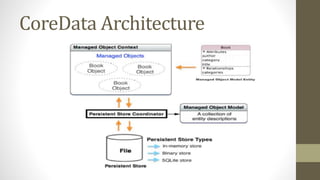
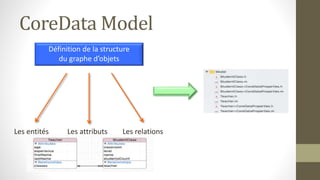
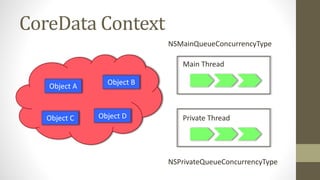
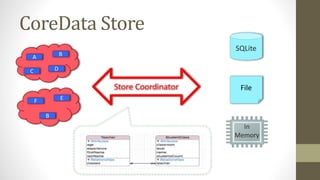
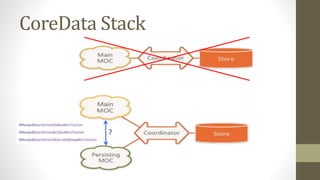
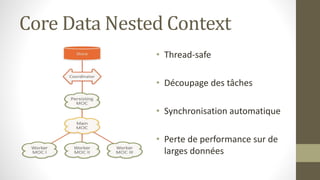
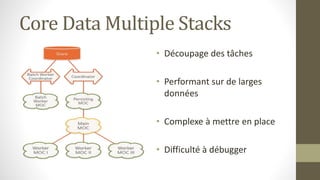

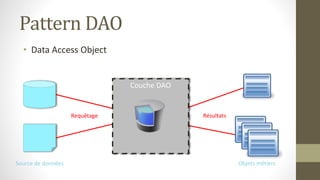
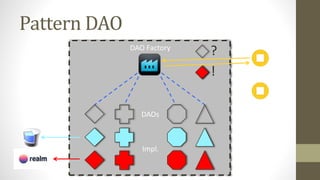



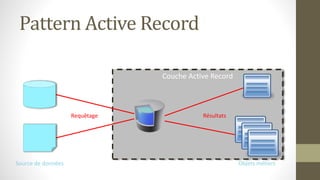




Le document présente les différents design patterns pour Core Data, notamment le pattern DAO et le pattern Active Record. Il aborde également l'architecture de Core Data, les implications de la gestion des contextes et les défis associés à la performance et à la complexité des implémentations. Des liens vers des ressources et projets exemplaires sont fournis pour approfondir le sujet.









![[Breizhcamp 2015] MongoDB et Elastic, meilleurs ennemis ?](https://cdn.slidesharecdn.com/ss_thumbnails/mongodbetelasticmeilleursennemis-150612210744-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)










































![Mappingobjetrelationnel[1]](https://cdn.slidesharecdn.com/ss_thumbnails/mappingobjetrelationnel1-101217111924-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)





![cours raspberry [Enregistrement automatique].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/coursraspberryenregistrementautomatique-260206145736-b1015531-thumbnail.jpg?width=640&height=640&fit=bounds)



