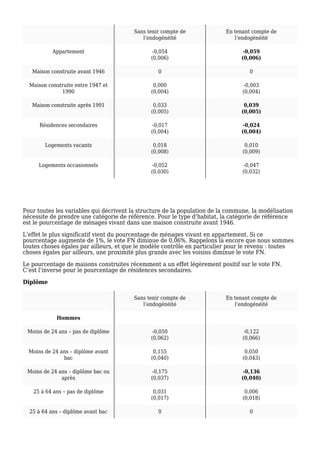
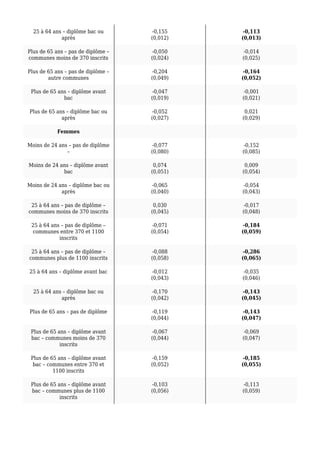
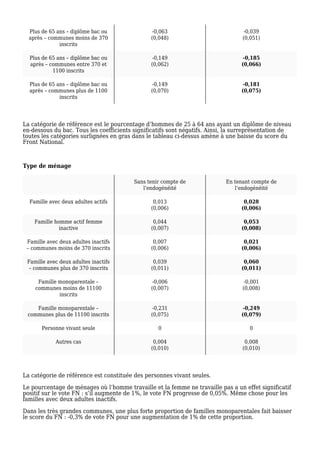
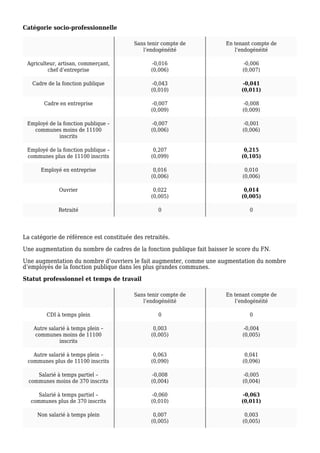
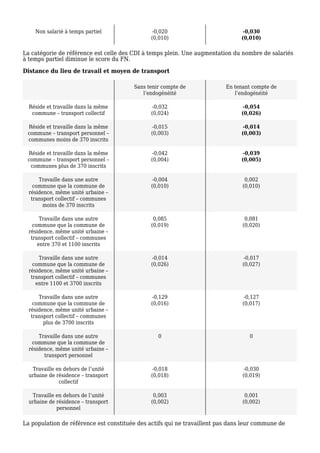
L'étude examine la relation entre le score du Front National et le taux d'abstention aux municipales de 2014, mettant en évidence l'importance de prendre en compte l'endogénéité des données pour obtenir des résultats précis. Après avoir modélisé divers facteurs communaux, les résultats montrent qu'une augmentation de 1 % de l'abstention équivaut à un accroissement de 0,5 % du vote en faveur du FN. Le modèle confirme que le taux de chômage et le revenu médian ont également un impact significatif sur le vote du FN.