Télécharger pour lire hors ligne









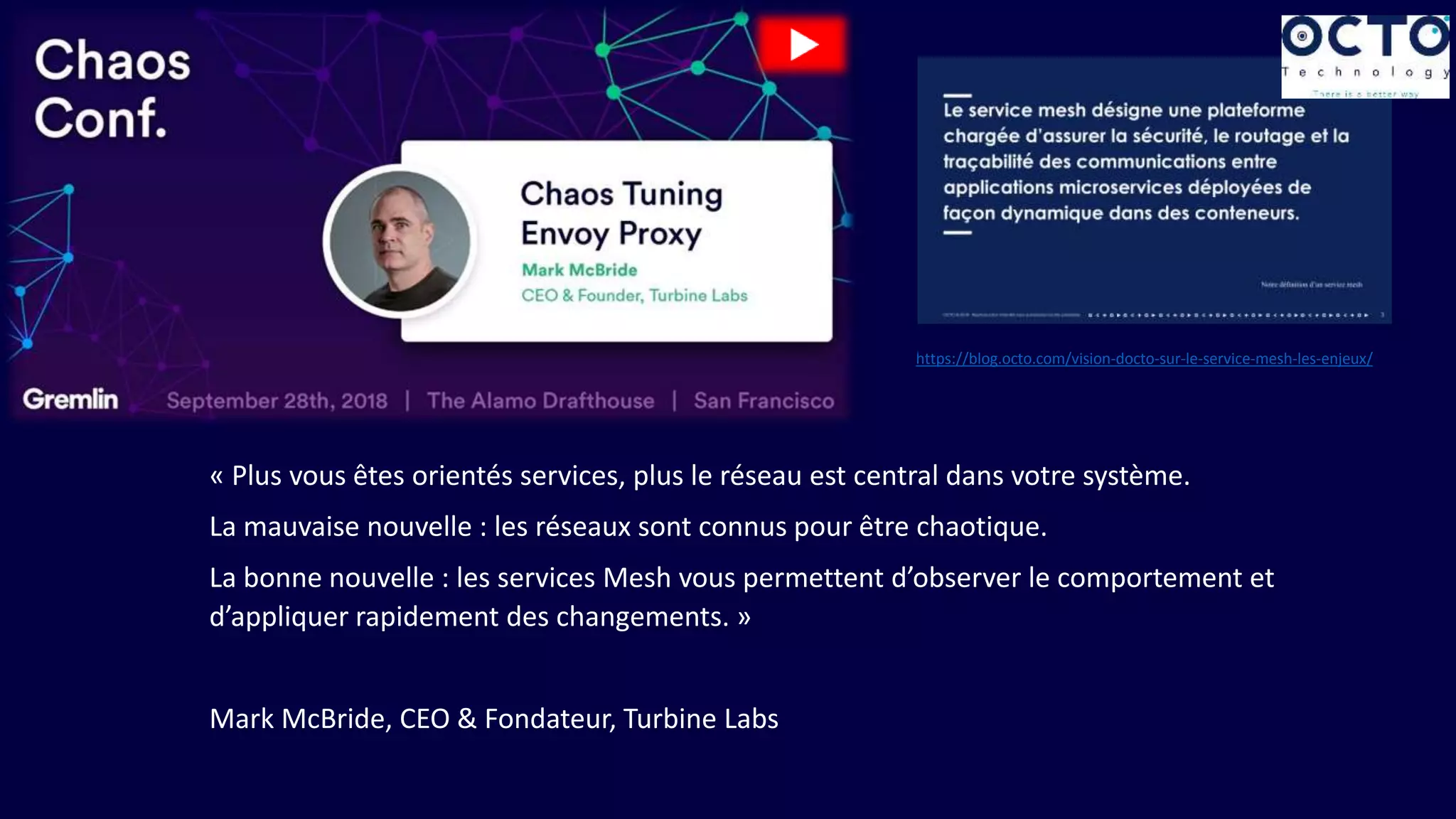






































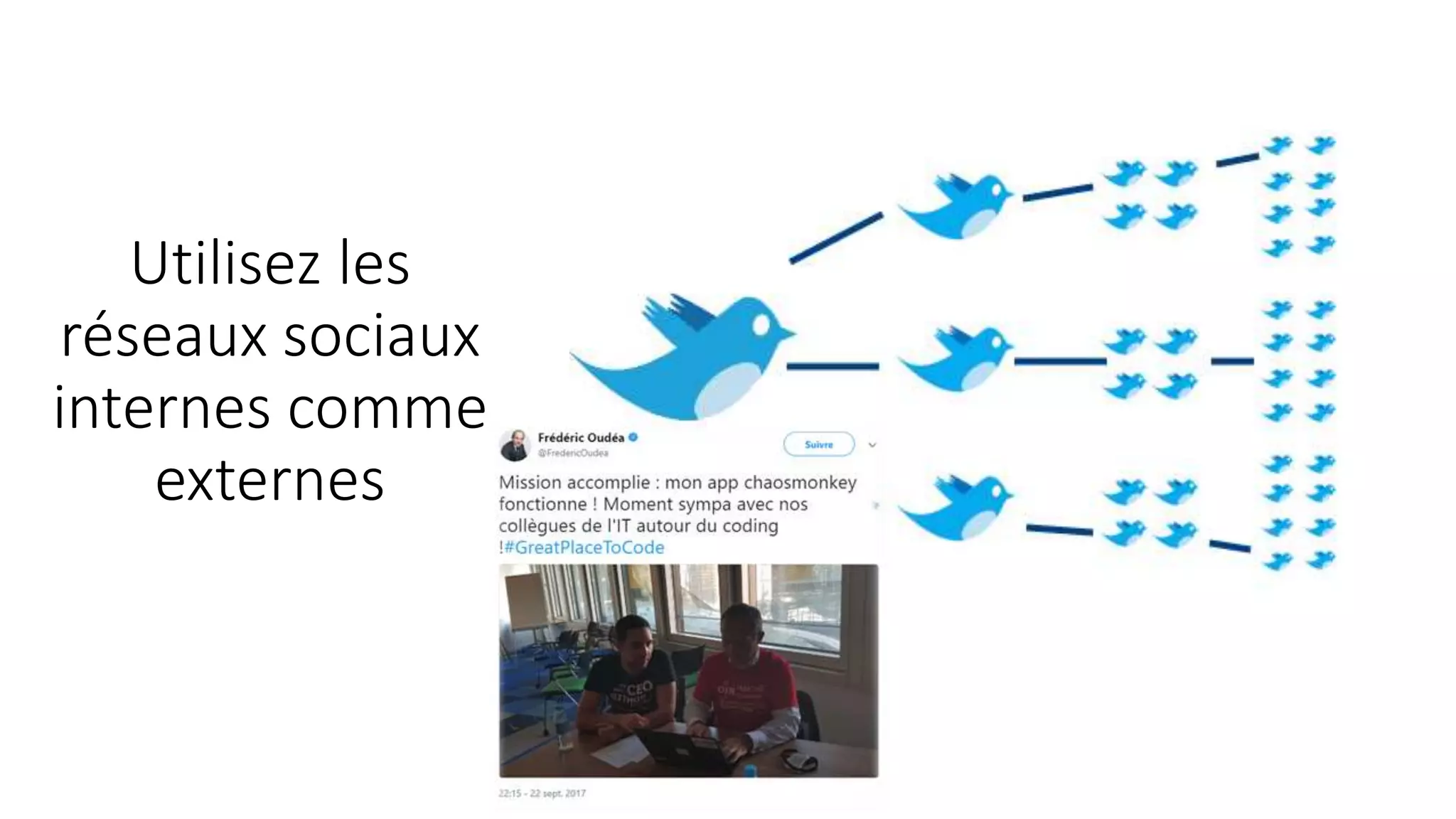











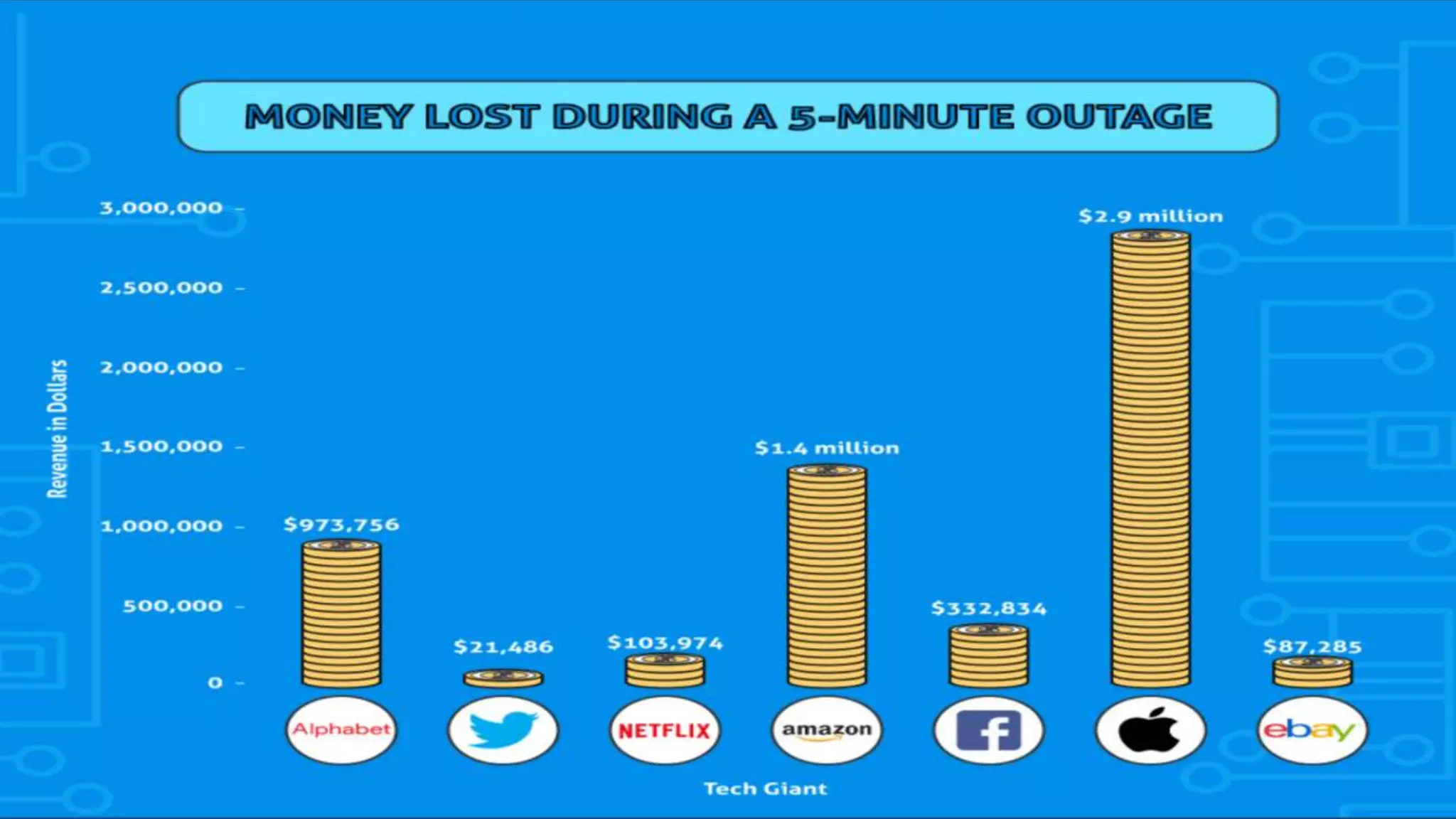









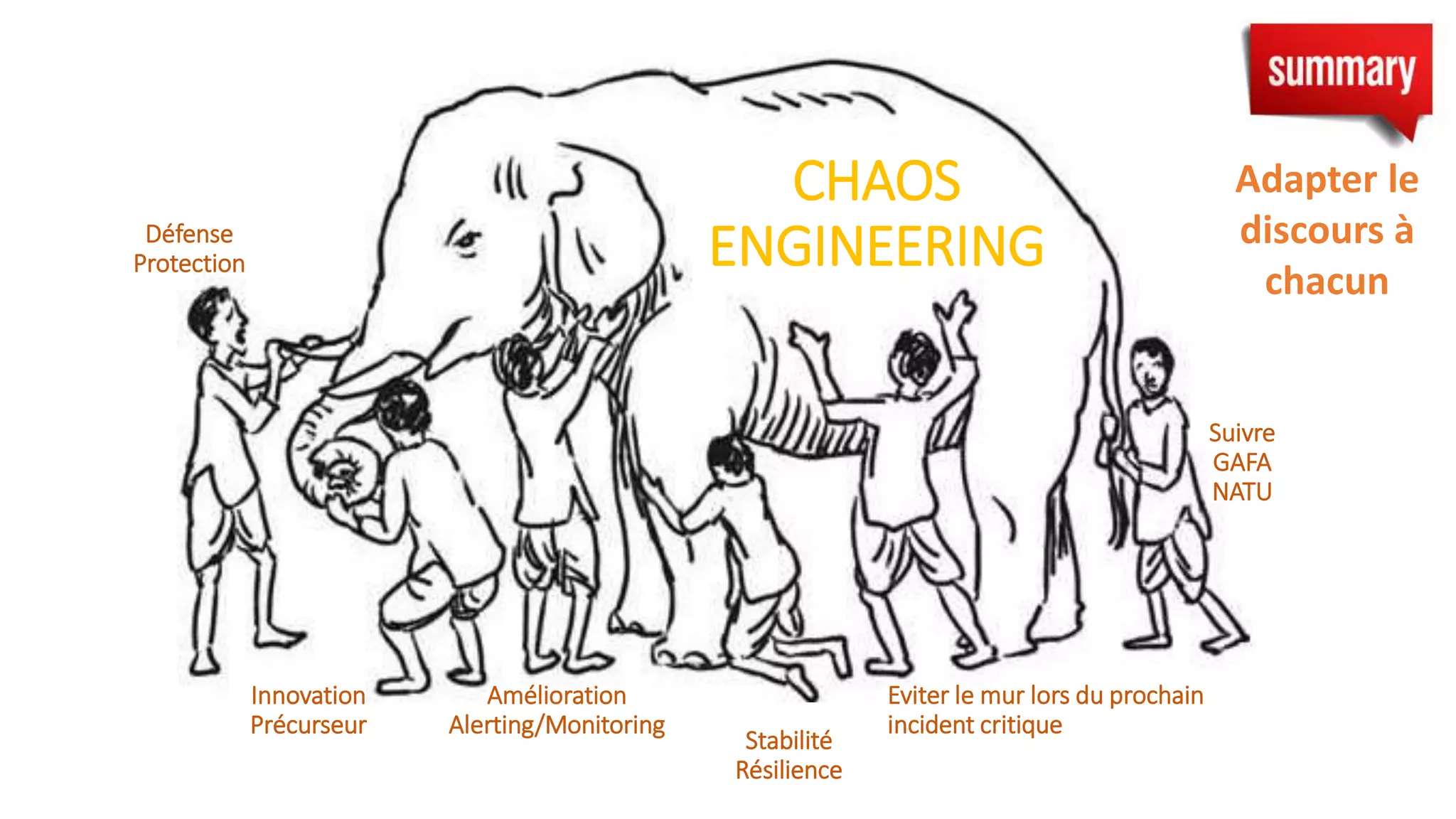







Le document présente un retour sur la Chaos Conf de septembre 2018, abordant l'importance de l'ingénierie du chaos et de l'observabilité dans les systèmes distribués. Des experts comme Kolton Andrus et Adrian Cockroft mettent en avant la nécessité d'une approche proactive vis-à-vis des pannes, tout en proposant une taxonomie des pannes pour mieux comprendre et gérer les incidents. Enfin, des stratégies d'influence sont partagées pour convaincre les décideurs d'adopter des pratiques de chaos engineering.





















![[devops REX 2017] Days of Chaos : le développement de la culture devops chez ...](https://cdn.slidesharecdn.com/ss_thumbnails/vsctdevopsdaysofchaos-devopsrex-v8-171003091127-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[POSS 2018] Passer d'un écosystème baremetal à un univers micro services et d...](https://cdn.slidesharecdn.com/ss_thumbnails/poss-devops-181220090153-thumbnail.jpg?width=640&height=640&fit=bounds)









![[GAV2025] Optimiser la productivité du troupeau : enjeux, outils et leviers d...](https://cdn.slidesharecdn.com/ss_thumbnails/09gav2025productivit-251208130427-d6f3d9c6-thumbnail.jpg?width=640&height=640&fit=bounds)
![[GAV 2025] - Impactomètres viande de boeuf](https://cdn.slidesharecdn.com/ss_thumbnails/prsentationgav2025-impactomtresviandedeboeuf-p-251211161728-dea3d37d-thumbnail.jpg?width=640&height=640&fit=bounds)

![[GAV2025] Démonstration d’outil « Bovin à équilibre » (Impactomètre)](https://cdn.slidesharecdn.com/ss_thumbnails/prsentationgav2025-impactomtresviandedeboeuf-p-251208124336-0558ab28-thumbnail.jpg?width=640&height=640&fit=bounds)

![[GAV 2025] Réduire les émissions de méthane avec des compléments alimentaires...](https://cdn.slidesharecdn.com/ss_thumbnails/06bertrandderochegav2025carmen-251208124622-e1c3f25a-thumbnail.jpg?width=640&height=640&fit=bounds)

![[GAV2025] Face aux tensions sur la ressource en eau, comment améliorer la rés...](https://cdn.slidesharecdn.com/ss_thumbnails/08romainsallesressourceeneaudiffusion-251208124939-59d67483-thumbnail.jpg?width=640&height=640&fit=bounds)


![[GAV2025] Engraissement de jeunes bovins. Quelles évolutions récentes en Fran...](https://cdn.slidesharecdn.com/ss_thumbnails/10gavengraissementjbcomplte-251208131215-0cbbeb11-thumbnail.jpg?width=640&height=640&fit=bounds)
![[GAV2025] Viande persillée : perceptions des consommateurs, pilotage et impac...](https://cdn.slidesharecdn.com/ss_thumbnails/04prsentationpersillgav-251208122356-1204022f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[GAV2025] Disponibilité de la ressource en eau : faire face à une baisse et à...](https://cdn.slidesharecdn.com/ss_thumbnails/7wittenagence-de-leauvf1-1-251208124826-5bb080ec-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Webinaire ECD] Élevage caprin : activer les bons leviers pour allier perform...](https://cdn.slidesharecdn.com/ss_thumbnails/web-ecd-cap2er041225-251208164235-7416ab2e-thumbnail.jpg?width=640&height=640&fit=bounds)