Téléchargé 11 fois



























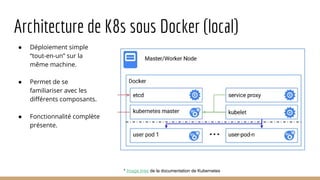
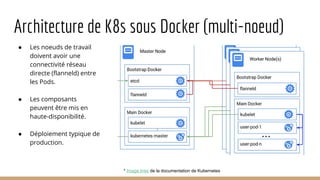


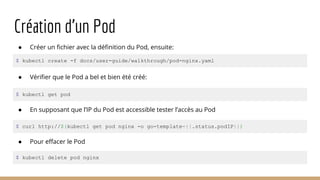












Ce document présente l'architecture et la mise en œuvre des micro-services sous Docker et Kubernetes par la startup MNubo, avec un accent sur l'automatisation, la scalabilité et l'amélioration continue. Il aborde les avantages des conteneurs pour la gestion des déploiements, l'utilisation de Kafka pour le traitement des données, et les principes de fonctionnement de Kubernetes pour l'orchestration des conteneurs. Enfin, il couvre la création, la gestion et la découverte des pods et services dans un environnement Kubernetes.























































































