Télécharger en tant que PDF, PPTX






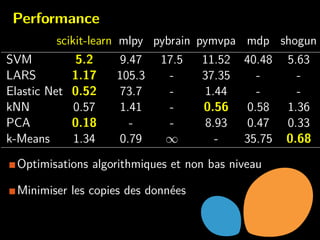





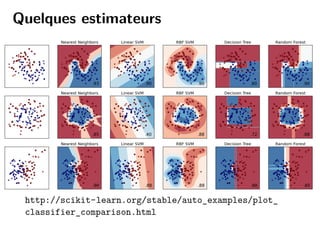
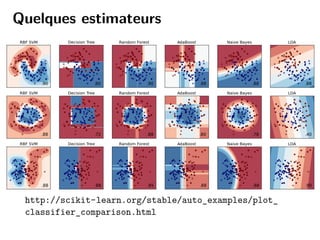
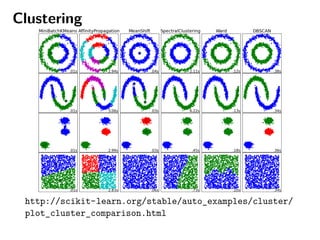


Scikit-learn est une bibliothèque Python d'apprentissage statistique axée sur la simplicité, l'efficacité et l'accessibilité pour tous les utilisateurs. Elle fournit divers outils pour l'apprentissage supervisé et non supervisé, ainsi qu'une API intuitive pour l'entraînement et la prédiction de modèles. Le projet est en constante évolution, bien documenté et nécessite des compétences techniques de base pour être intégré.