















![Exemple : Java 8
Arrays.stream(rows)
.parallel().forEach(row -> {
for (int j = 0; j < matBCols; j++) {
double temp = 0;
for (int k = 0; k < matACols; k++) {
temp += row.rowA[k] * matB[k][j];
}
row.rowResult[j] = temp;
}
});
18](https://image.slidesharecdn.com/vivreenparallle-jugl2013-130517073916-phpapp01/85/Vivre-en-parallele-Softshake-2013-18-320.jpg)







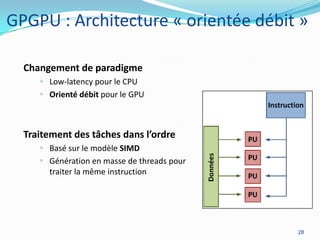
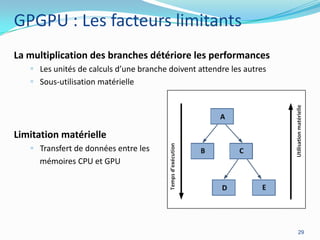



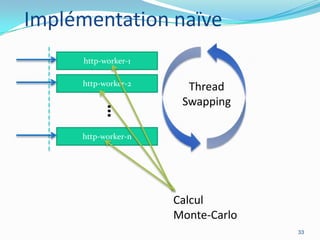
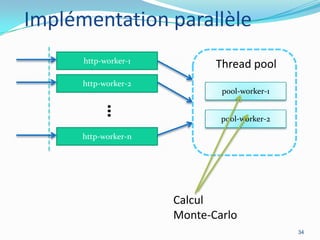









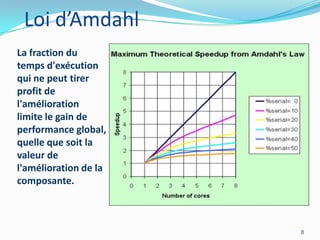
La programmation parallèle est essentielle pour les développeurs modernes, particulièrement à l'ère post-Lois de Moore où l'augmentation des cœurs devient primordiale. Les architectures CPU et GPU évoluent vers des modèles de traitement parallèle, ce qui permet des gains de performance significatifs, même en tenant compte des défis tels que la loi d'Amdahl. Des frameworks et des exemples de mise en œuvre tels que les collections parallèles en Java ou GPGPU démontrent l'importance croissante du parallélisme dans le développement logiciel.







![[Harvard CS264] 01 - Introduction](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201101-introductionshare-110206153841-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
























































