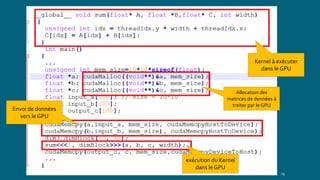
Le document présente CUDA, une API développée par NVIDIA pour le calcul parallèle sur GPU, en expliquant son fonctionnement, sa structure de code et ses domaines d'application. Il compare CUDA à d'autres API comme OpenMP en soulignant sa rapidité et son utilisation spécifique aux GPUs. La conclusion met en avant l'accélération des temps d'exécution des instructions grâce au parallélisme permis par CUDA.








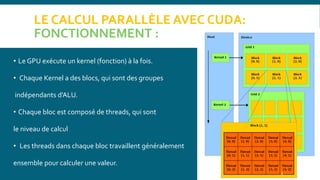



![LE CALCUL PARALLÈLE AVEC CUDA:
STRUCTURE DU CODE :
Le lancement d'un kernel s'effectue de la maniére suivante :
kernel<<< dimGrid, dimBlock ,[ dimMem ]>>>(params);
Kernel: nom de la fonction
dimGrid: taille de la grille (en nombre de blocs)
dimBlock: taille de chaque blocs (en nombre de threads)
dimMem (optienel): taille de la mémoire partagée allouée par bloc.
Les biblioteques associées: cuda.h et cuda_runtime.h.
12](https://image.slidesharecdn.com/cuda-190708175022/85/CUDA-12-320.jpg)