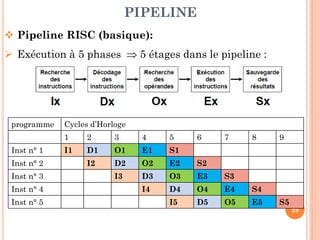
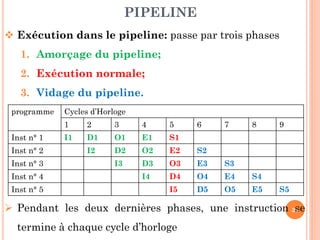
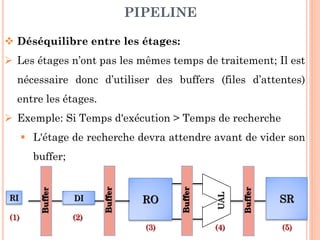
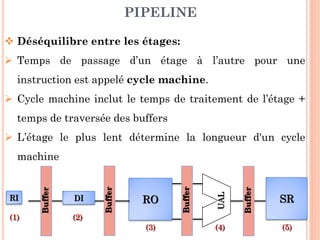
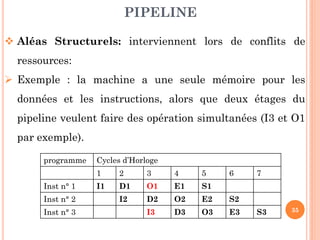
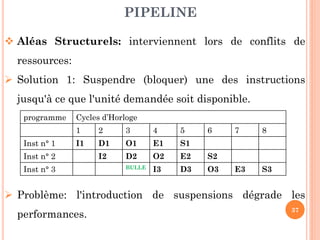
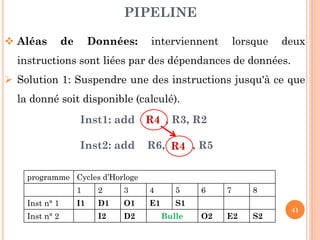
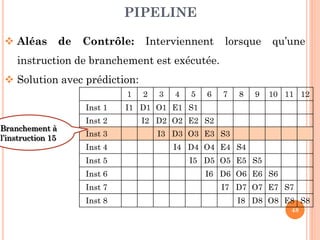
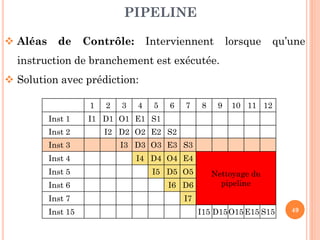
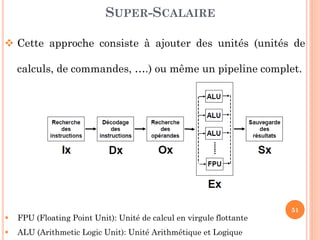
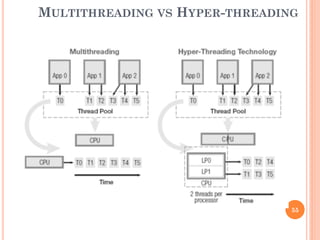
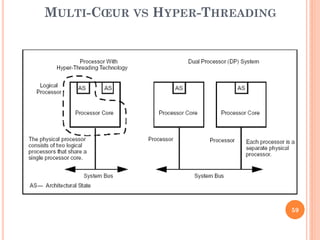
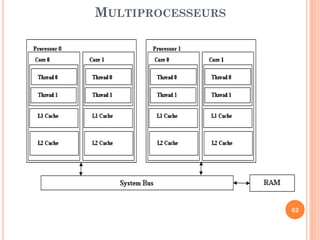
Ce document aborde l'architecture des ordinateurs, en particulier les processus récents, et compare les architectures CISC et RISC. Il traite des principes fondamentaux de l'architecture des processeurs, des cycles de fréquence, et des techniques de pipeline pour améliorer l'efficacité des instructions. Le contenu inclut également les problèmes d'aléas liés aux pipelines et les solutions proposées pour les gérer.










![ARCHITECTURE CISC
Le processeur CISC possède un jeu étendu d’instructions
complexes et puissantes.
Le processeur CISC réduit le nombre d'instructions écrites dans
un programme et facile ainsi sa compilation.
Une instruction CISC peut effectuer plusieurs opérations
élémentaires (Chargement, Rangement, Arithmétique, ….).
Exemple (Assembleur 8086): ADD [200h], 125
Charger la valeur du mot mémoire 200h
Faire l’addition ([200h]+125)
Ranger le résultat dans le mot mémoire 200h
10](https://image.slidesharecdn.com/chapitreiarchitecturesdesprocesseursrcents-140218143424-phpapp01/85/Chapitre-i-architectures-des-processeurs-recents-10-320.jpg)