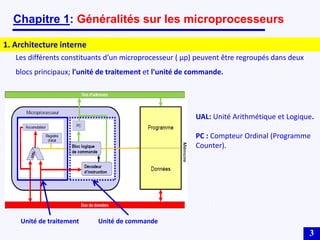
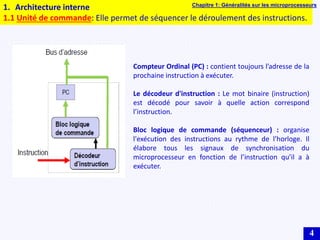
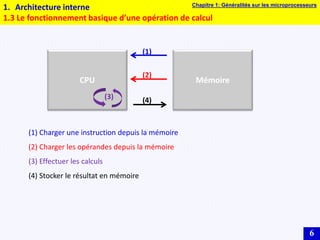
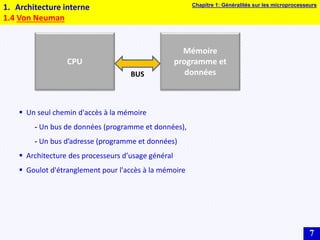
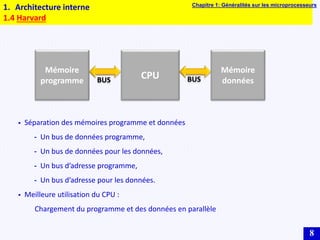
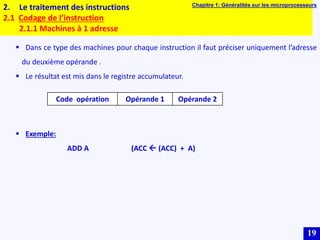
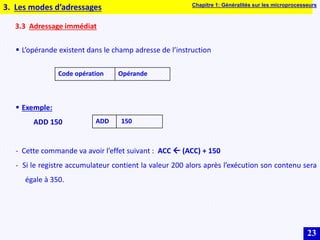
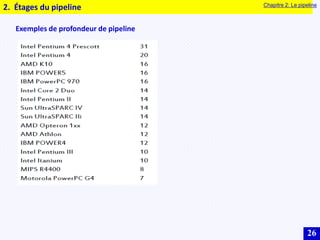
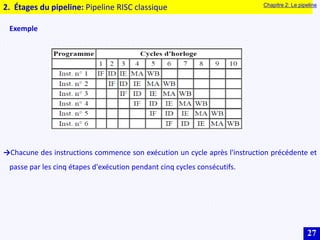
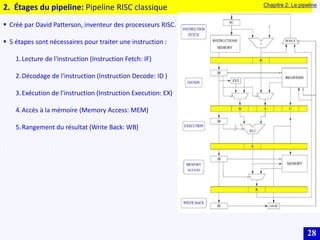
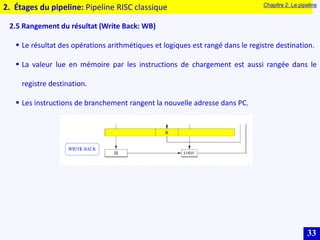
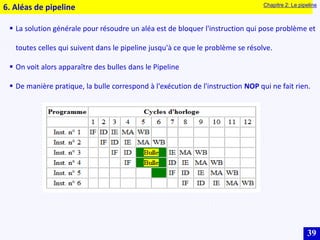
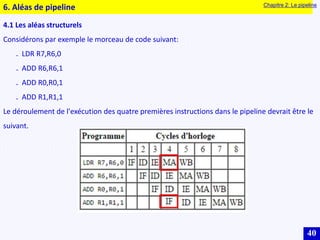
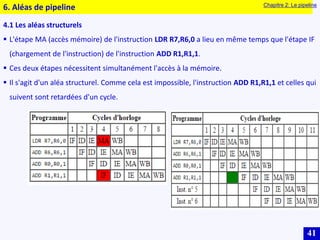
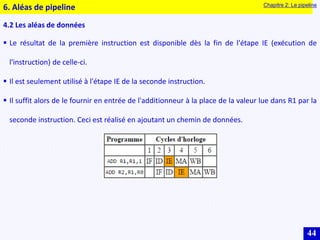
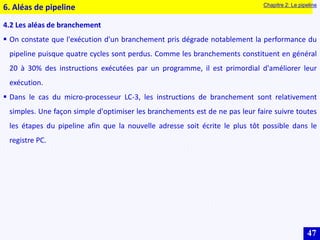
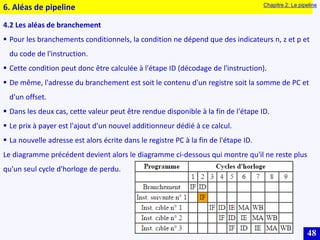
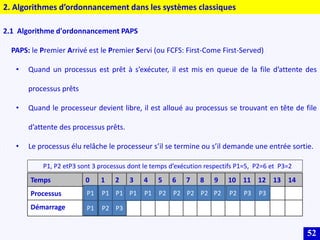
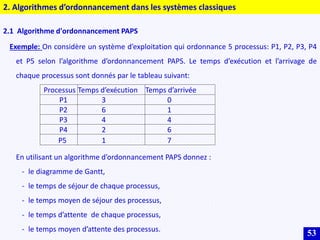
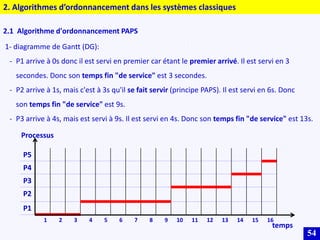
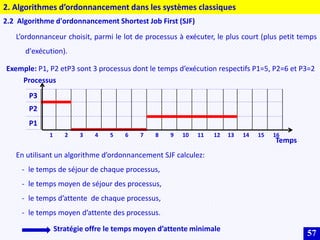
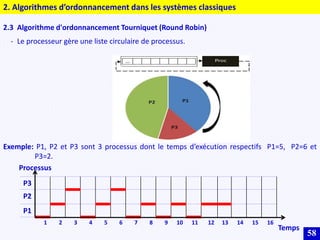
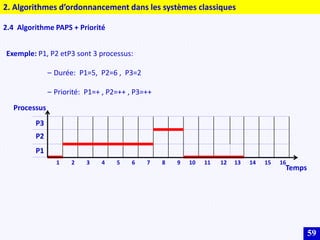
Le document traite des systèmes embarqués, couvrant des sujets tels que l'architecture des microprocesseurs, le traitement des instructions et les modes d'adressage. Il décrit en détail les unités de commande et de traitement, ainsi que les principes de fonctionnement des architectures Harvard et Von Neumann. Enfin, il aborde le concept de pipeline pour optimiser l'exécution d'instructions dans les microprocesseurs RISC.